Episode 3: Technical Implementation—Fine-Tuning, Enriched Schemas, and Deployment скачать в хорошем качестве
Episode 3: Technical Implementation—Fine-Tuning, Enriched Schemas, and Deployment
2 месяца назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Episode 3: Technical Implementation—Fine-Tuning, Enriched Schemas, and Deployment в качестве 4k
У нас вы можете посмотреть бесплатно Episode 3: Technical Implementation—Fine-Tuning, Enriched Schemas, and Deployment или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Episode 3: Technical Implementation—Fine-Tuning, Enriched Schemas, and Deployment в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Episode 3: Technical Implementation—Fine-Tuning, Enriched Schemas, and Deployment
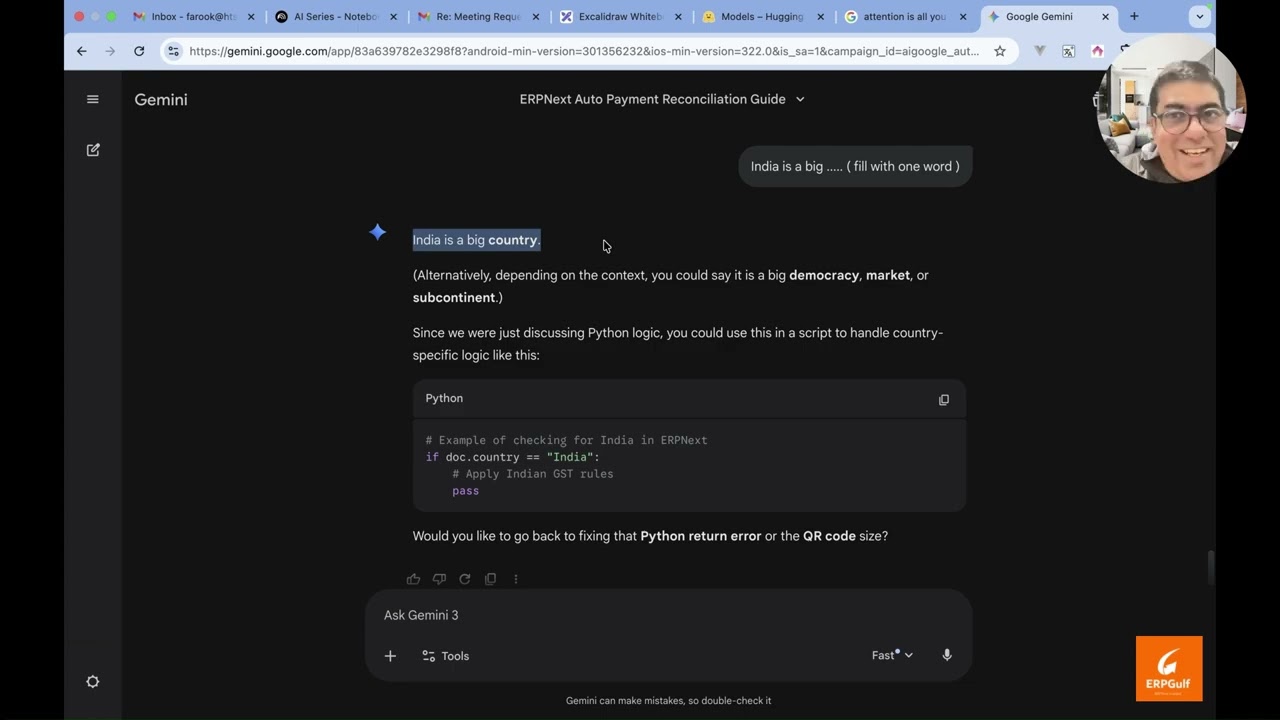
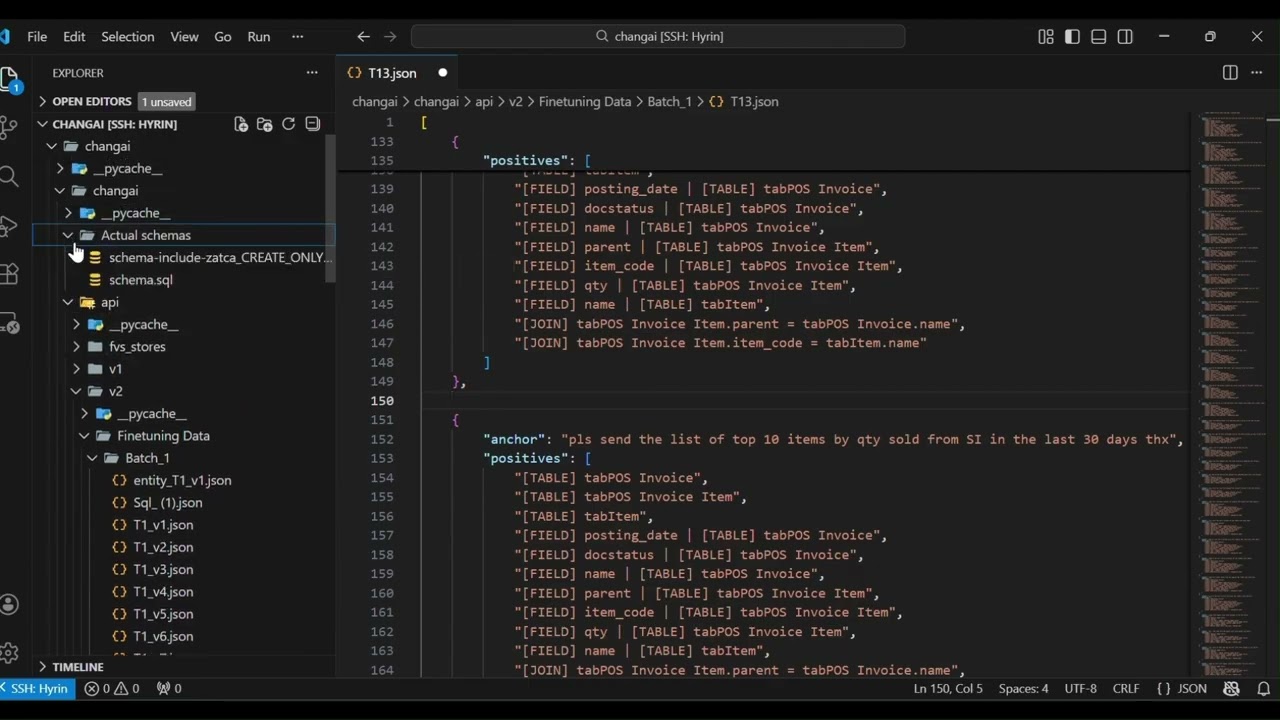
On AI building for ERP series, In Episode 3, we move from the theory of RAG to the actual technical pipeline required to build a reliable ERPNext AI Agent. To cross the 90% accuracy barrier, we had to move beyond general models and implement a rigorous process of fine-tuning, data enrichment, and agentic deployment. What you will learn in this episode: • Preparing Training Data: We explain the format of our training data using "Anchors" (user questions) and "Positives" (the metadata needed to generate SQL, including tables, fields, and joins)., • Synthetic Data Generation: How we use GPT-4 mini to create "messy" or "noisy" variants of questions. This ensures the model understands real-world human phrasing like "Items with zero stock" vs. "Out of stock products.", • Enriched Schema Preparation: Moving beyond raw storage schema to an Enriched Schema. We add synonyms, descriptions, and join chunks to your Doctypes so the AI understands the "why" behind your data.,, • The Fine-Tuning Process: A walkthrough of fine-tuning the Nomic AI ModernBert embedding model using Google Colab Pro+. We explain the Loss Function—the mathematical mechanism that pushes correct results (positives) closer to the user's question in the embedding space while pushing irrelevant data away.,,, • Evaluation Metrics: How we measure success using technical benchmarks like MRR (Mean Reciprocal Rank), NDCG, and Precision to ensure the most relevant schema is always ranked at the top. • FAISS Vector Store: Building the vector store for both Master Data and Enriched Schemas to enable lightning-fast semantic search., • Deploying via Replicate & Docker: The step-by-step process of wrapping models in Docker containers (using Cog) and deploying them to Replicate for production-grade inference.,, • The Multi-Model Strategy: Why we use Qwen 4B for SQL generation and rewriting chat history, alongside a lightweight Qwen 1.5B model for formatting database results into friendly responses.,, Technical Tech Stack: • Embedding Model: Nomic AI (ModernBert) • Generative Models: Qwen 4B & 1.5B • Vector Store: FAISS • Training Environment: Google Colab Pro+ • Inference/Deployment: Replicate & Hugging Face, Join the Journey: We are building this in the open to save you from "losing a year" of failed experiments. Follow our progress as we bridge the gap between human language and ERP logic. ERPGulf - Customized ERPNext for the Gulf, regional hosting For personalized training for individuals and companies email training@ERPGulf.com https://www.ERPGulf.com / erpgulf / erpgulf https://github.com/erpgulf / erpgulf / erpgulf / erpgulf https://claudion.com/
Comments


![[SIG ContribEx] Biweekly Meeting for 2026-03-18T16:56:38Z.mp4](https://imager.clipsaver.ru/ztzkbiiRbrs/max.jpg)