Скачать с ютуб Easy, Scalable, Fault Tolerant Stream Processing with Structured Streaming in Apache Spark в хорошем качестве
Easy, Scalable, Fault Tolerant Stream Processing with Structured Streaming in Apache Spark
7 лет назад
Скачать бесплатно и смотреть ютуб-видео без блокировок Easy, Scalable, Fault Tolerant Stream Processing with Structured Streaming in Apache Spark в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно Easy, Scalable, Fault Tolerant Stream Processing with Structured Streaming in Apache Spark или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон Easy, Scalable, Fault Tolerant Stream Processing with Structured Streaming in Apache Spark в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Easy, Scalable, Fault Tolerant Stream Processing with Structured Streaming in Apache Spark
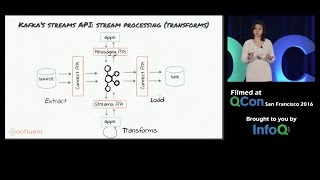
"Last year, in Apache Spark 2.0, Databricks introduced Structured Streaming, a new stream processing engine built on Spark SQL, which revolutionized how developers could write stream processing application. Structured Streaming enables users to express their computations the same way they would express a batch query on static data. Developers can express queries using powerful high-level APIs including DataFrames, Dataset and SQL. Then, the Spark SQL engine is capable of converting these batch-like transformations into an incremental execution plan that can process streaming data, while automatically handling late, out-of-order data and ensuring end-to-end exactly-once fault-tolerance guarantees. With Tathagata Das. Since Spark 2.0, Databricks has been hard at work building first-class integration with Kafka. With this new connectivity, performing complex, low-latency analytics is now as easy as writing a standard SQL query. This functionality, in addition to the existing connectivity of Spark SQL, makes it easy to analyze data using one unified framework. Users can now seamlessly extract insights from data, independent of whether it is coming from messy / unstructured files, a structured / columnar historical data warehouse, or arriving in real-time from Kafka/Kinesis. In this session, Das will walk through a concrete example where – in less than 10 lines – you read Kafka, parse JSON payload data into separate columns, transform it, enrich it by joining with static data and write it out as a table ready for batch and ad-hoc queries on up-to-the-last-minute data. He’ll use techniques including event-time based aggregations, arbitrary stateful operations, and automatic state management using event-time watermarks. About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business. Read more here: https://databricks.com/product/unifie... Connect with us: Website: https://databricks.com Facebook: / databricksinc Twitter: / databricks LinkedIn: / databricks Instagram: / databricksinc Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here. https://databricks.com/databricks-nam...
Comments