Multiplexing and molecular barcodes (indexes) in NGS (Next Gen Sequencing) скачать в хорошем качестве
Multiplexing and molecular barcodes (indexes) in NGS (Next Gen Sequencing)
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Multiplexing and molecular barcodes (indexes) in NGS (Next Gen Sequencing) в качестве 4k
У нас вы можете посмотреть бесплатно Multiplexing and molecular barcodes (indexes) in NGS (Next Gen Sequencing) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Multiplexing and molecular barcodes (indexes) in NGS (Next Gen Sequencing) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Multiplexing and molecular barcodes (indexes) in NGS (Next Gen Sequencing)
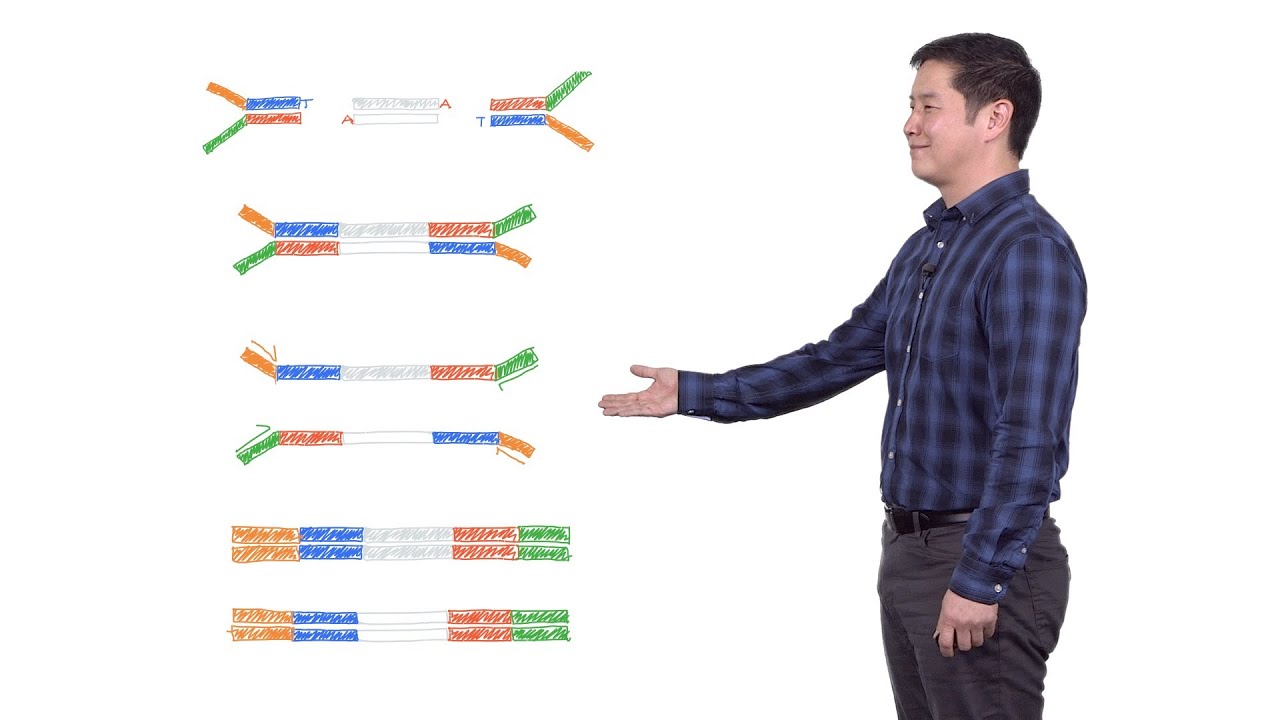
Multiplexing is when we combine or “pool” multiple samples together, process them all together, and then split up the results into those corresponding to each separate sample (this un-pooling process is called demultiplexing (demuxing). This saves resources (including time) and is commonly done in NGS (Next Generation Sequencing) techniques like Illumina DNA sequencing. We’re able to keep track of what results helping to what sample by using molecular “barcodes.” These barcodes are just additional sample-specific DNA sequences we put onto the ends of the DNA we want to sequence. They get read along with the rest of the sequence so you can tell which sample each read comes from. blog form: https://bit.ly/multiplexingandbarcodes Illumina uses short-read technology. Instead of trying to sequence a long piece of DNA (accumulating more and more errors along the way), it only reads out short sequences (100 or so bp depending on the sequencer and run conditions). You start by breaking your DNA into short pieces and those pieces are what get sequenced. The barcodes are added to the pieces as part of adaptors that allow the DNA pieces to bind to the sequencing chip, where lots of copies will get made and the sequence will be read out as they are (this is called sequencing by synthesis). We call the collection of prepared pieces a sequencing library and we will have one library per sample. If we use unique indexes on each sample (thus each library), we can pool together lots of them. The number we pool together is called the plexity. It’s common that researchers will have multiple samples they want to compare as part of an experiment (corresponding to different tissues, different drug treatments of cells in cell culture, different individuals, etc.). So they will give each a unique barcode (or 2!) & pool them together. Now they only have to pay for a single sequencing run! In the beginning of multiplex technology, a single index, on a single end, was used. But now it’s common to use dual indexes, one on each side (referred to as i5 and i7 in Illumina talk). Since each index is 8 or 10 nucleotides long, this allows for lots of possible combinations, so you can pool together lots of samples and still be able to tell them all apart (though if you try to sequence too many, you might not get enough depth of coverage (reads per sample) as you need - the sequencer can only give a certain number of reads and those will be divided up among the different samples). You get the most options, and the least problems with index hopping (a problem that results in the wrong index being assigned to a read), when you use Unique Dual Indexes. With these, no 2 barcodes get repeated. With earlier combinatorial indexes, some samples would share one (but not both) of their indexes (e.g. one sample might be A&Z and another sample might be B&Z). But with the UDI’s, you would instead have A&Z and B&Y or something. There’s also a kind of barcode called a Unique Molecular Index (UMI). Instead of “just” ID’s the sample, it ID’s the actual fragment. This is sometimes used to be able to tell which reads were PCR duplicates (boring) as opposed to different physical copies of the molecule to start with (which could indicate increased expression of a gene if it’s an RNA sequencing library, say). Note: although we talk about RNA seq, we’re usually actually sequencing DNA libraries made by first reverse transcribing RNA. Though some newer sequencing technologies like NanoPore can sequence RNA directly. A final note on something that might confuse you (I know it confused me at first) - the indexes are actually sequenced in their own read (not as part of the longer read). This has a few advantages including not “wasting” part of those already-short reads on a barcode rather than the actual sequence you care about. More discussion about some of the technical benefits of this sequence-separately approach here: https://www.seqanswers.com/forum/sequ... & https://www.researchgate.net/post/Why... Links to more resources in the comments
Comments