Unleashing DuckDB & dbt for local analytics triumphs скачать в хорошем качестве
Unleashing DuckDB & dbt for local analytics triumphs
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Unleashing DuckDB & dbt for local analytics triumphs в качестве 4k
У нас вы можете посмотреть бесплатно Unleashing DuckDB & dbt for local analytics triumphs или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Unleashing DuckDB & dbt for local analytics triumphs в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Unleashing DuckDB & dbt for local analytics triumphs
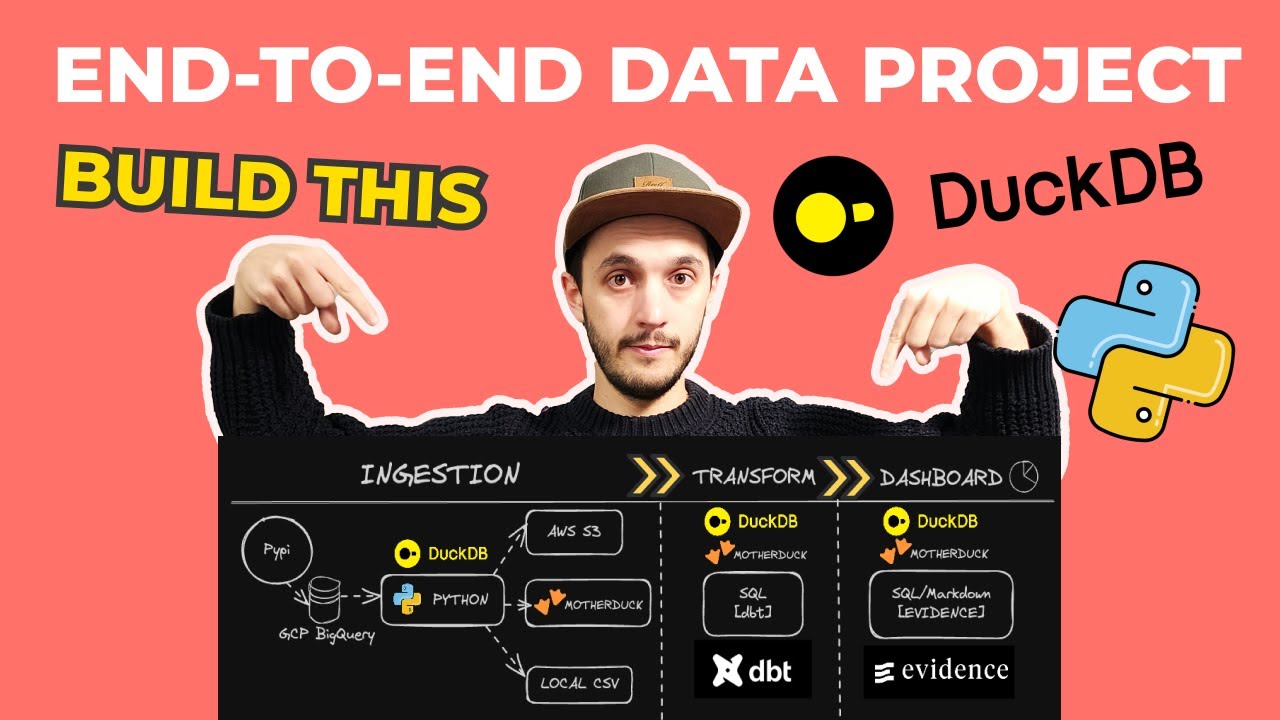
In this video, @mehdio will do a walkthrough of DuckDB with dbt. What kind of features these two frameworks provide together ? ☁️🦆 Start using DuckDB in the Cloud for FREE with MotherDuck : https://hubs.la/Q02QnFR40 📓 Resources Github Repo of the tutorial : https://github.com/mehd-io/dbt-duckdb... DuckDB getting started video: • DuckDB Tutorial For Beginners In 12 min Dbt docs: https://docs.getdbt.com/docs/core/con... ➡️ Follow Us LinkedIn: / 8192. . Twitter : / motherduck Blog: https://motherduck.com/blog/ 0:00 Intro 0:44 Challenges of dbt with cloud datawarehouses 2:23 Where DuckDB can help 3:05 DuckDB and dbt with a project 7:59 Take aways #dbtduckdb #dbtandduckdb #dataengineering #dbtdatabuildtool -------------------------------------- This dbt tutorial explores how to write production-ready SQL data pipelines locally by combining dbt with DuckDB, eliminating the need for a constant connection to a cloud data warehouse. We address the common challenges of traditional dbt development workflows, such as being unable to leverage local compute power and the difficulty of running isolated unit tests. Learn how DuckDB, a blazingly fast in-process SQL database, revolutionizes this process by running directly within your dbt Python process. This powerful combination improves your development experience, allowing you to build and test data pipelines anywhere, even offline. Follow our practical guide on how to use dbt and DuckDB together, starting with the simple installation of the `dbt-duckdb` adapter. We walk through a real-world example of building a data pipeline that analyzes air quality data. You'll see how to configure your dbt project to read Parquet files directly from a public S3 bucket, leveraging DuckDB extensions for seamless data access. We then write SQL queries to transform this data, ranking city air quality based on metrics like PM2.5 and NO2 concentration, and outputting the results as local CSV files for quick inspection. This video demonstrates the full potential of running pure production-ready SQL pipelines locally, perfect for rapid iteration, robust testing in CI, and a smoother onboarding experience for new analysts. We also discuss the real-world limitations of this local-first approach, such as data sharing and BI tool integration, and introduce how we're solving these challenges at MotherDuck. If you're searching for dbt optimization techniques or a powerful cloud data warehouse alternative for development, this guide is for you.
Comments