How strong is GPT-4? скачать в хорошем качестве
How strong is GPT-4?
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How strong is GPT-4? в качестве 4k
У нас вы можете посмотреть бесплатно How strong is GPT-4? или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How strong is GPT-4? в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How strong is GPT-4?
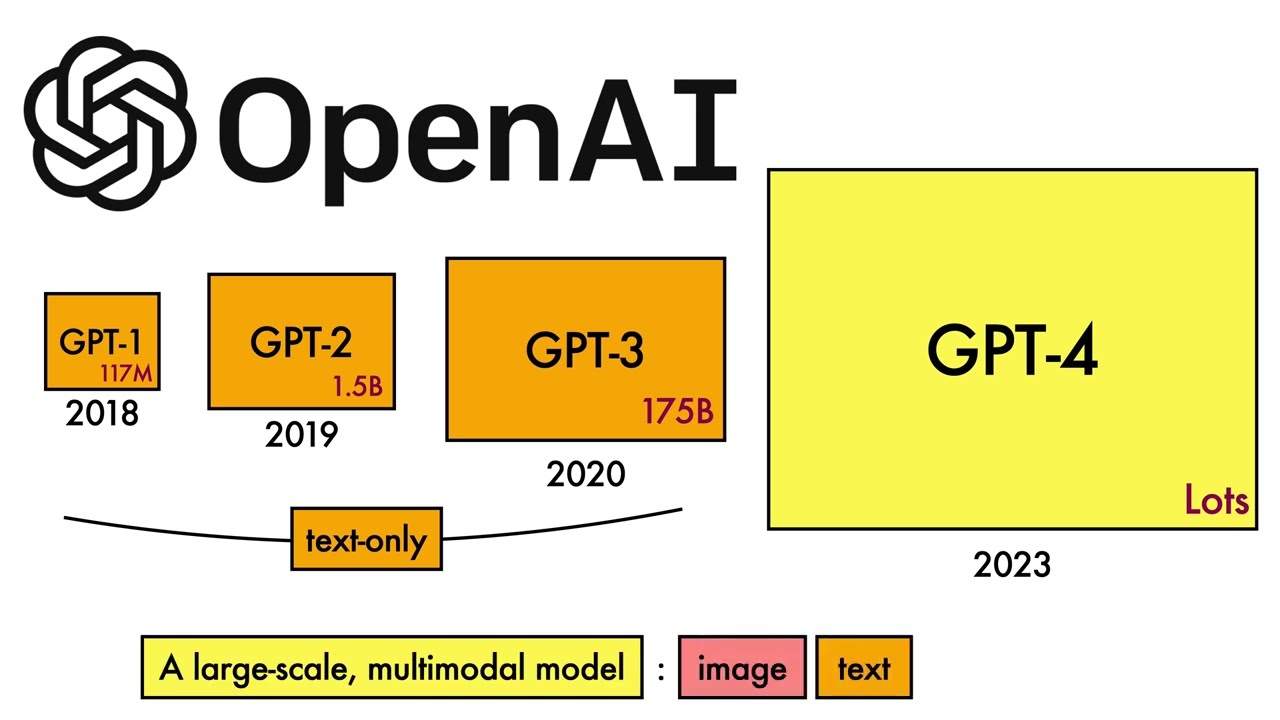
An overview of the OpenAI Technical Report describing GPT-4. Timestamps: 00:00 - GPT-4 00:23 - Overview 01:45 - Scope Of Technical Report 02:19 - Predictable Scaling: Loss 03:39 - Predictable Scaling: Coding 04:46 - Less Predictable Scaling: Hindsight Neglect 05:47 - Capabilities: Professional Exams 06:40 - Exams 07:21 - Capabilities: Academic Benchmarks 08:24 - Capabilities: Other Languages 09:15 - Capabilities: User Intent And Evaluation 10:22 - Capabilities: Visual Inputs 11:26 - Limitations 12:19 - Limitations: Factuality 12:45 - Limitations: TruthfulQA 13:27 - TruthfulQA: Qualitative Behaviour 14:18 - Calibration 14:54 - Risks And Mitigations: Adversarial Testing 15:37 - Red Teaming (Qualitative) 16:19 - Model-Assisted Safety Pipeline 17:34 - Reduced Refusal (Qualitative Example) 18:45 - Improvements On Safety Metrics Correction: 06:58 - note, the second to last xtick on the xaxis should read "SAT EBRW", not "AP Calculus BC" Topics: #gpt-4 #ai #capabilities #risks Links: Slides (pdf): https://samuelalbanie.com/files/diges... References for papers mentioned in the video can be found at http://samuelalbanie.com/digests/2023... The OpenAI technical report: https://cdn.openai.com/papers/gpt-4.pdf Detailed description: GPT-4 achieves human-level performance on several professional and academic tests. A key element of achieving this was to build infrastructure and optimisation tooling that behaves predictably across scales, allowing OpenAI to scale up from previous GPT models. However, it still suffers limitations (hallucinations, limited context, no learning from experience). It also poses significant safety challenges. The video describes the OpenAI technical report, which focuses on the capabilities, limitations and safety of the model. However, it offers few model details. This is both for safety reasons, and because of the competitive nature of language model development. We describe how the final loss of GPT-4 was accurately predicted by smaller models, as was its coding capability. However, some capabilities (like "hindsight neglect") are hard to predict. Next, we talk through the various exams on which GPT-4 achieves major gains. There are many. Using image inputs helps in a number of exams. The results on academic benchmarks are very strong, particularly on MMLU. Strikingly, GPT-4 can do well on MMLU in many languages (including those with far less training data than English). We describe how RLHF helps align the model to user intent, but interestingly doesn't help with multiple-choice exam performance. We also look at a qualitative example of GPT-4's visual capabilities. We discuss the limitations of GPT-4 highlighted by OpenAI. These include issues with factual accuracy, where GPT-4 does better than prior OpenAI models. We talk through the interventions used to improve the model, which include red-teaming with domain experts and a model assisted safety pipeline. Finally, we describe how GPT-4 represents improvements on several safety metrics. It is however, still vulnerable to jailbreaks, so further mitigations are put in place to monitor abuse. Still, we can probably expect some Twitter research on jailbreaks in the near future.... For related content: Twitter: / samuelalbanie Research lab: https://caml-lab.com/ personal webpage: https://samuelalbanie.com/ YouTube: / @samuelalbanie1 Experimental blog: https://filtir.com (Optional) if you'd like to support the channel: https://www.buymeacoffee.com/samuelal... / samuel_albanie
Comments



















