How Cross Attention Powers Translation in Transformers | Encoder-Decoder Explained скачать в хорошем качестве
How Cross Attention Powers Translation in Transformers | Encoder-Decoder Explained
6 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How Cross Attention Powers Translation in Transformers | Encoder-Decoder Explained в качестве 4k
У нас вы можете посмотреть бесплатно How Cross Attention Powers Translation in Transformers | Encoder-Decoder Explained или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How Cross Attention Powers Translation in Transformers | Encoder-Decoder Explained в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How Cross Attention Powers Translation in Transformers | Encoder-Decoder Explained
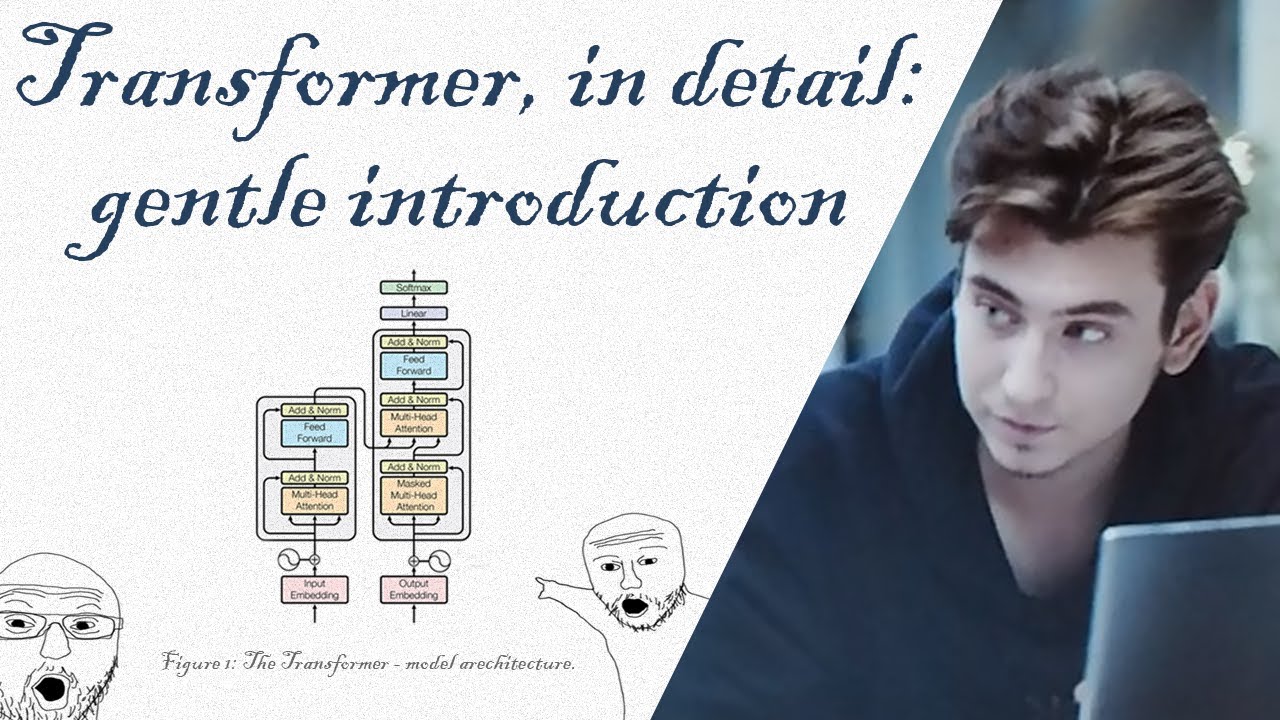
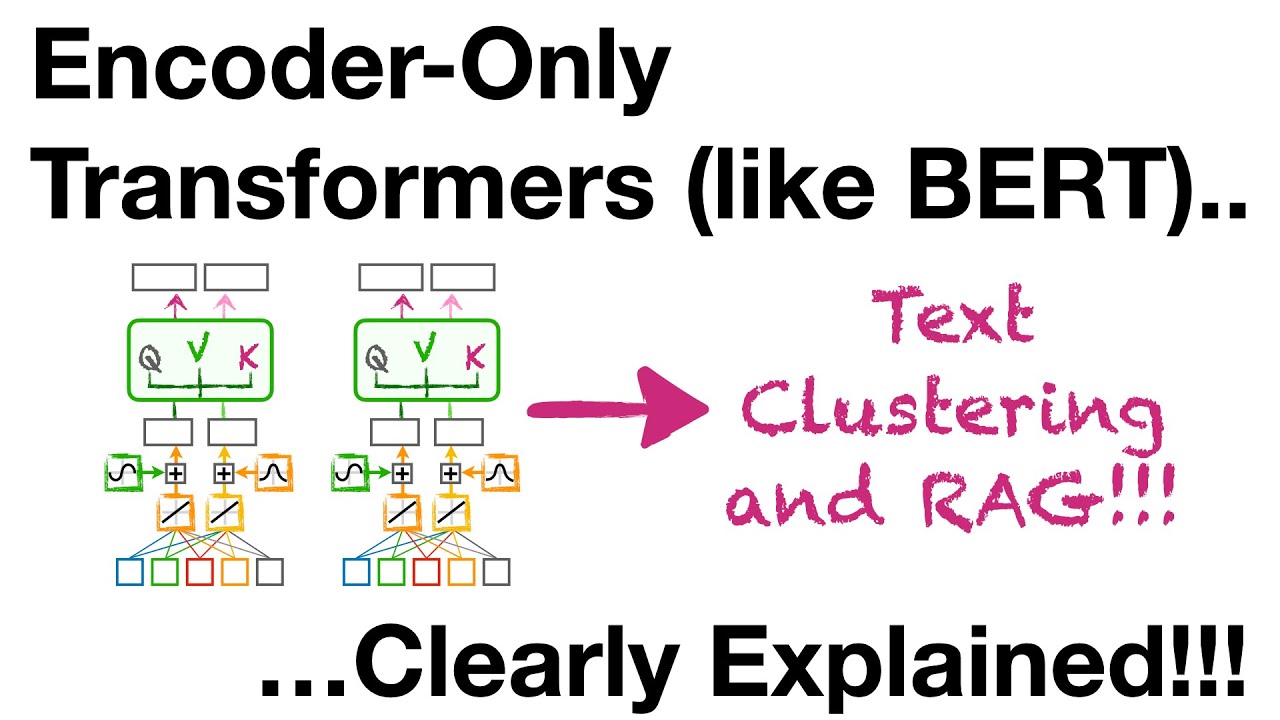
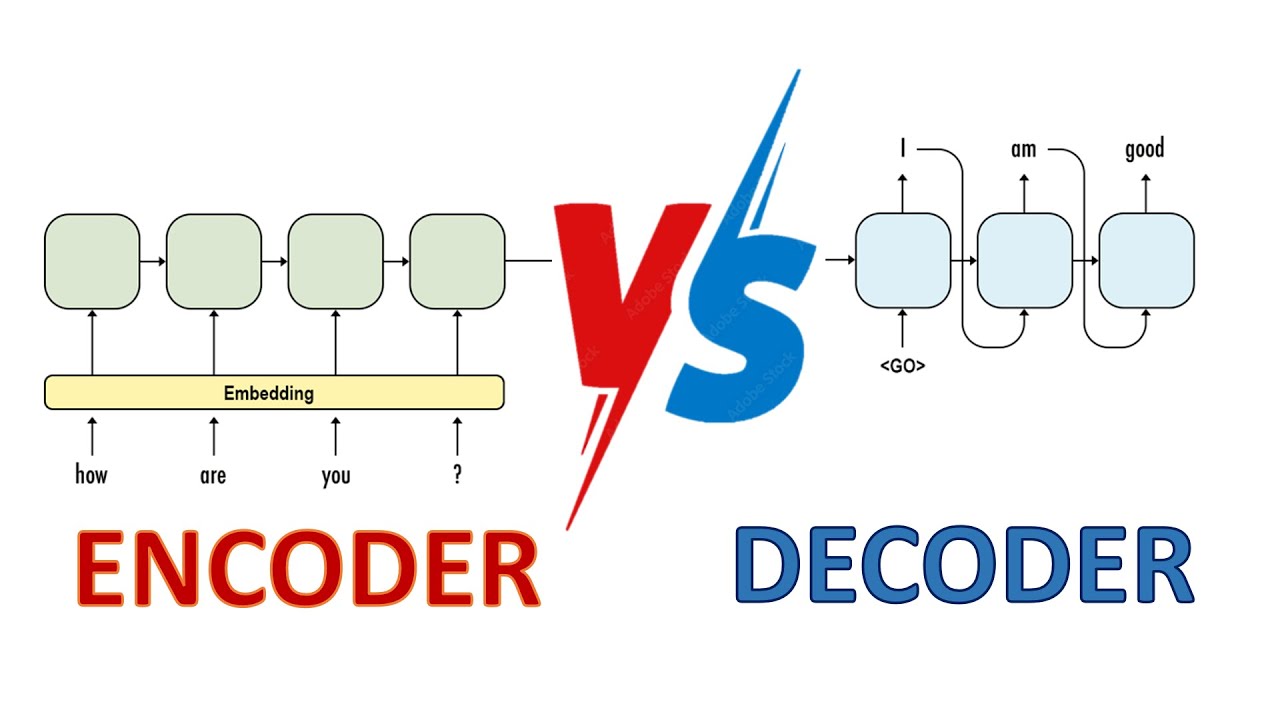
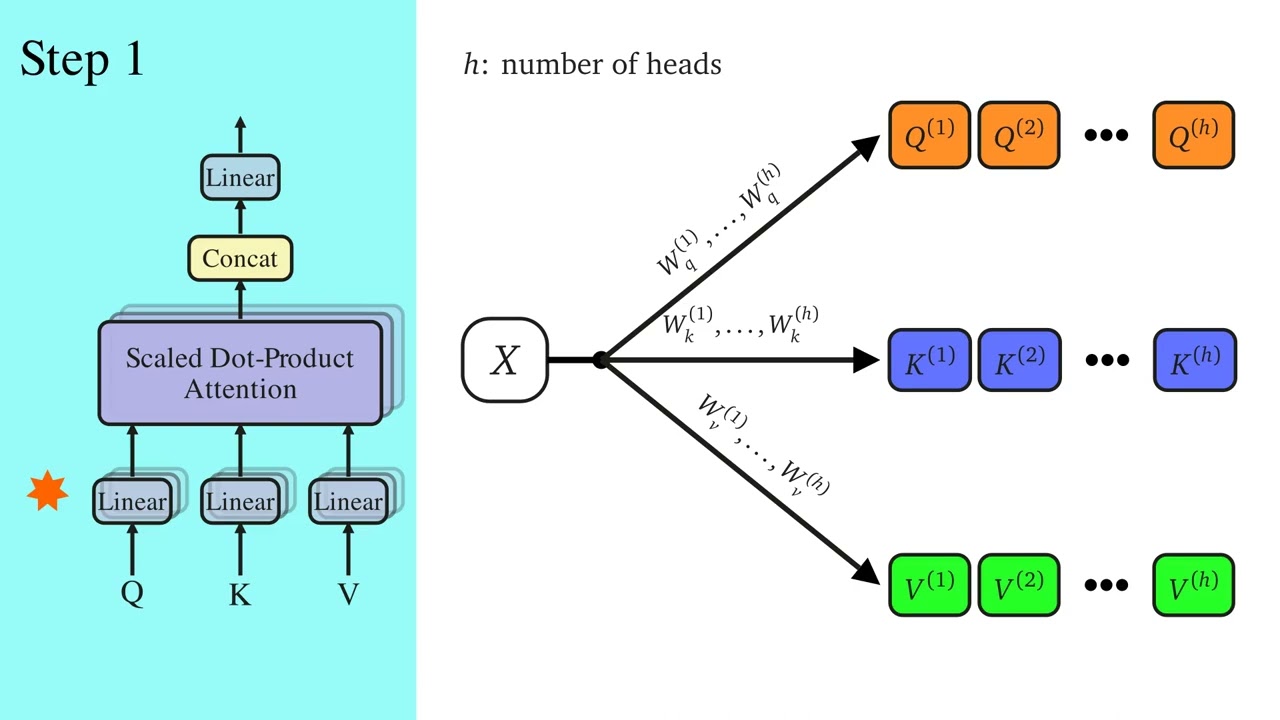
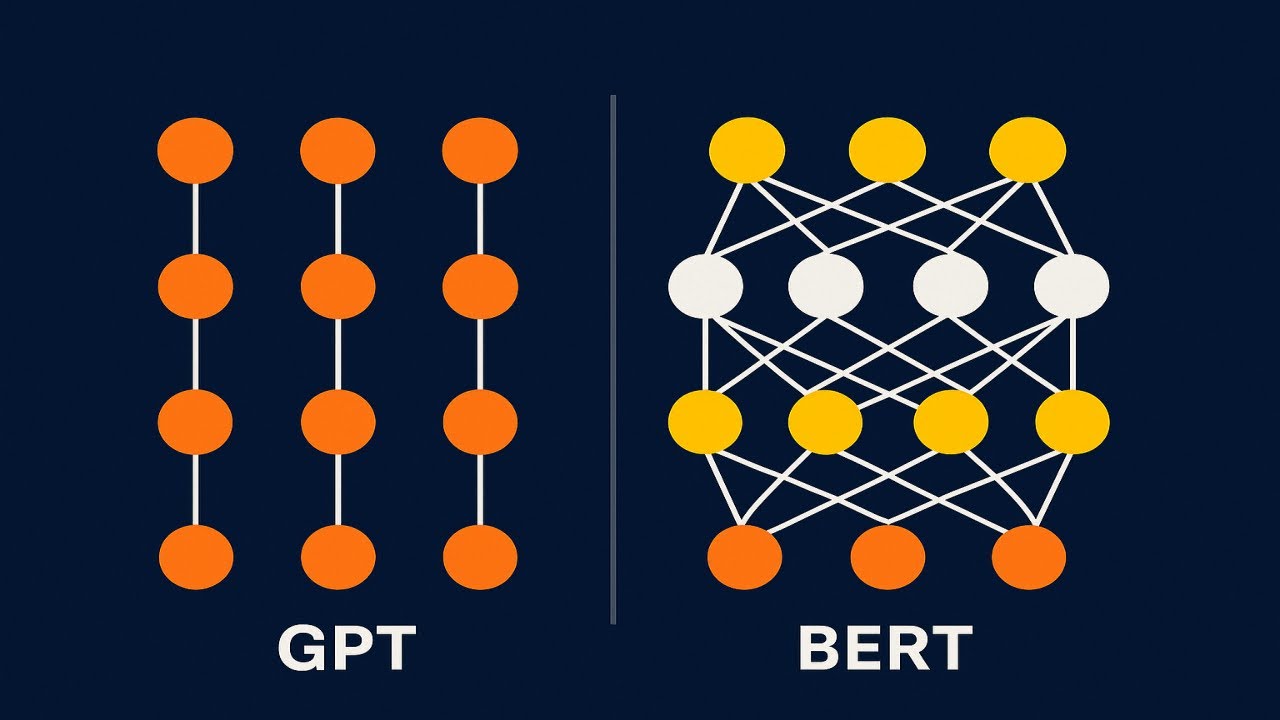
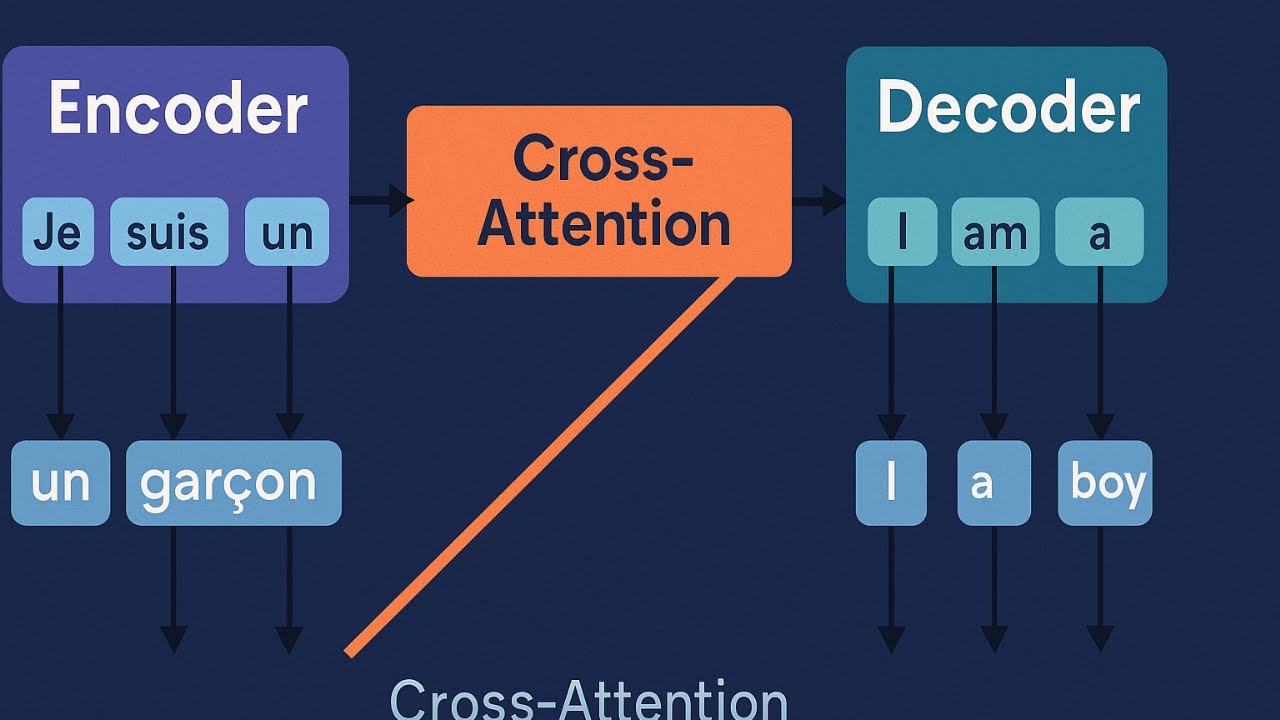
🎓 Full Course HERE 👉 https://community.superdatascience.co... In this lesson, we dive into one of the most crucial yet often overlooked mechanisms of transformer models: cross attention. Used in encoder-decoder architectures like those powering machine translation, cross attention allows the decoder to condition its output on the encoder's processed input. In other words—it's what enables accurate, context-rich translations. You’ll learn how Q, K, and V vectors interact across encoder and decoder layers, and why this attention mechanism is essential for aligning input and output sentences word by word. ✅ Understand the role of cross attention in encoder-decoder transformers ✅ Learn how decoder queries attend to encoder outputs ✅ Explore how context-aware vectors are refined across multiple heads ✅ Discover why translation relies on input-conditioned decoding ✅ Grasp the subtle differences between self-attention and cross attention 🔗 Also find us here: 🌐 Website: https://www.superdatascience.com/ 💼 LinkedIn: / superdatascience 📬 Contact: support@superdatascience.com ⏱️ Chapters: 00:00 – Introduction to Cross Attention 00:07 – Transformer Architecture Review 00:30 – Why the Encoder-Decoder Bridge Matters 01:16 – Translation Task Setup & Inference Recap 02:05 – Where Cross Attention Occurs in the Decoder 02:44 – Q, K, V Vectors from Decoder and Encoder 03:27 – Example Walkthrough: Translating the Word "Fant" 04:13 – Querying Encoder Outputs with Decoder Q Vectors 05:20 – Softmax Alignment to Choose Value Vectors 06:01 – Building O' Vectors: Enhanced Context Representations 07:00 – Why Cross Attention Is Vital for Translation Accuracy 07:52 – Multi-Headed Cross Attention Visualized 08:43 – Summary: Cross Attention Powers Translation 🧠 Hashtags: #CrossAttention #Transformers #MachineTranslation #EncoderDecoder #DeepLearning #NLP #LLMs #TransformerModels #AIExplained #NeuralNetworks
Comments