Spark SQL Bucketing at Facebook - Cheng Su (Facebook) скачать в хорошем качестве
Spark SQL Bucketing at Facebook - Cheng Su (Facebook)
6 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Spark SQL Bucketing at Facebook - Cheng Su (Facebook) в качестве 4k
У нас вы можете посмотреть бесплатно Spark SQL Bucketing at Facebook - Cheng Su (Facebook) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Spark SQL Bucketing at Facebook - Cheng Su (Facebook) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Spark SQL Bucketing at Facebook - Cheng Su (Facebook)
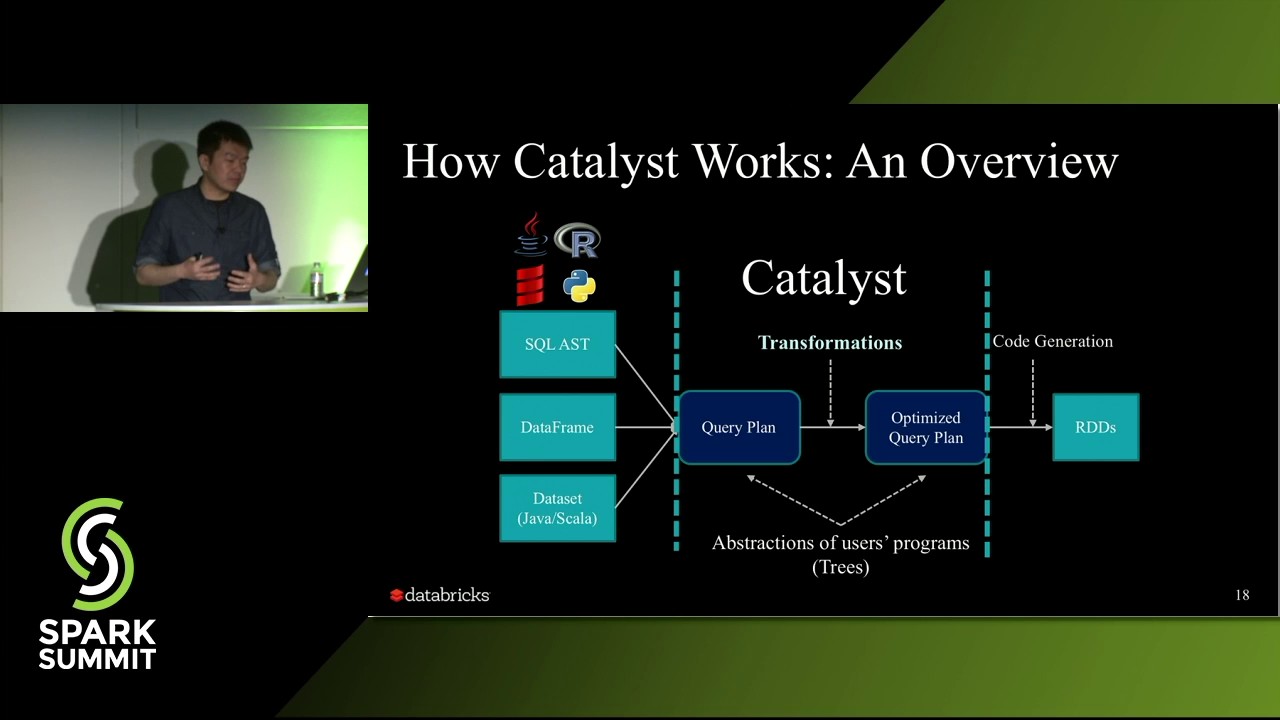
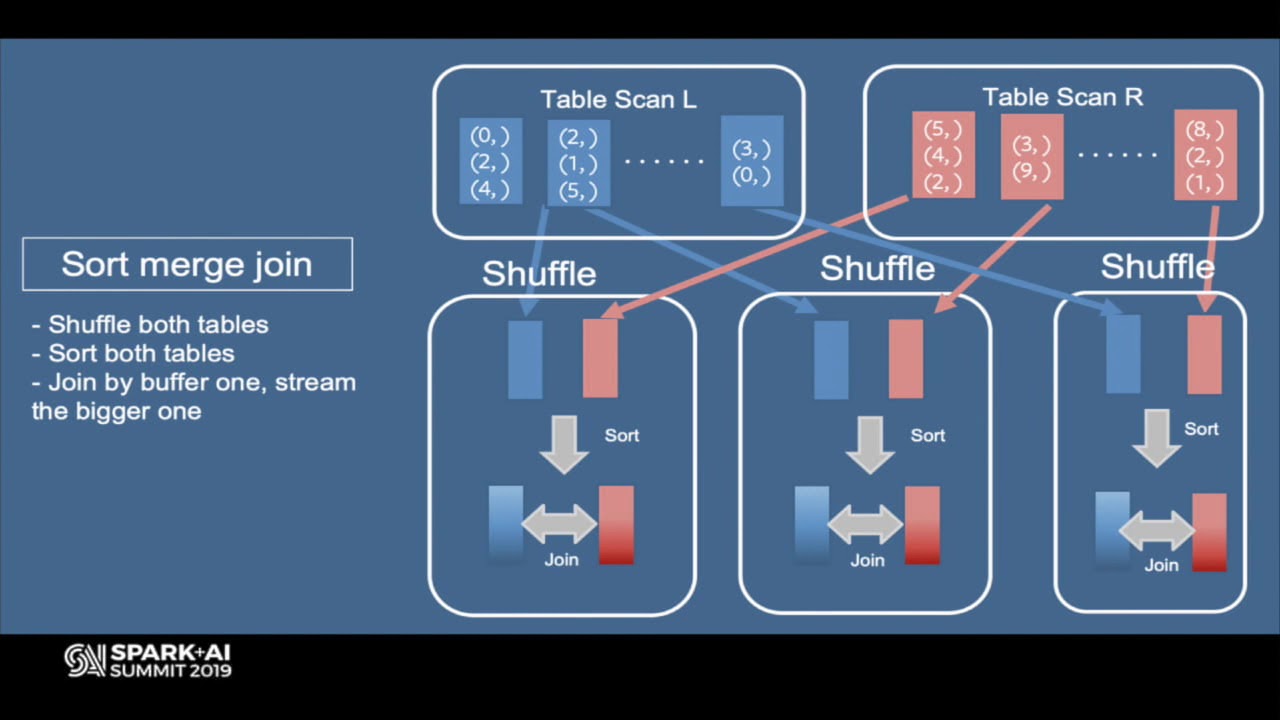
Bucketing is a popular data partitioning technique to pre-shuffle and (optionally) pre-sort data during writes. This is ideal for a variety of write-once and read-many datasets at Facebook, where Spark can automatically avoid expensive shuffles/sorts (when the underlying data is joined/aggregated on its bucketed keys) resulting in substantial savings in both CPU and IO. Over the last year, we've added a series of optimizations in Apache Spark as a means towards achieving feature parity with Hive and Spark. These include avoiding shuffle/sort when joining/aggregating/inserting on tables with mismatching buckets, allowing user to skip shuffle/sort when writing to bucketed tables, adding data validators before writing bucketed data, among many others. As a direct consequence of these efforts, we've witnessed over 10x growth (spanning 40% of total compute) in queries that read one or more bucketed tables across the entire data warehouse at Facebook. In this talk, we'll take a deep dive into the internals of bucketing support in SparkSQL, describe use-cases where bucketing is useful, touch upon some of the on-going work to automatically suggest bucketing tables based on query column lineage, and summarize the lessons learned from developing bucketing support in Spark at Facebook over the last 2 years. About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business. Read more here: https://databricks.com/product/unifie... Connect with us: Website: https://databricks.com Facebook: / databricksinc Twitter: / databricks LinkedIn: / databricks Instagram: / databricksinc Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here. https://databricks.com/databricks-nam...
Comments