рқ—ҹрқ—ҹрқ— рқ— рқ—јрқ—ұрқ—Ірқ—№ рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ: рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ рқҳғрқҳҖ рқ—ӨрқҳӮрқ—®рқ—»рқҳҒрқ—¶рқҳҮрқ—®рқҳҒрқ—¶рқ—јрқ—» рқҳғрқҳҖ рқ——рқ—¶рқҳҖрқҳҒрқ—¶рқ—№рқ—№рқ—®рқҳҒрқ—¶рқ—јрқ—» СҒРәР°СҮР°СӮСҢ РІ С…РҫСҖРҫСҲРөРј РәР°СҮРөСҒСӮРІРө
рқ—ҹрқ—ҹрқ— рқ— рқ—јрқ—ұрқ—Ірқ—№ рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ: рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ рқҳғрқҳҖ рқ—ӨрқҳӮрқ—®рқ—»рқҳҒрқ—¶рқҳҮрқ—®рқҳҒрқ—¶рқ—јрқ—» рқҳғрқҳҖ рқ——рқ—¶рқҳҖрқҳҒрқ—¶рқ—№рқ—№рқ—®рқҳҒрқ—¶рқ—јрқ—»
7 РҙРҪРөР№ РҪазаРҙ
РқРө СғРҙР°РөСӮСҒСҸ загСҖСғР·РёСӮСҢ Youtube-РҝР»РөРөСҖ. РҹСҖРҫРІРөСҖСҢСӮРө РұР»РҫРәРёСҖРҫРІРәСғ Youtube РІ РІР°СҲРөР№ СҒРөСӮРё.
РҹРҫРІСӮРҫСҖСҸРөРј РҝРҫРҝСӢСӮРәСғ...
РҹРҫРІСӮРҫСҖСҸРөРј РҝРҫРҝСӢСӮРәСғ...
РЎРәР°СҮР°СӮСҢ РІРёРҙРөРҫ СҒ СҺСӮСғРұ РҝРҫ СҒСҒСӢР»РәРө или СҒРјРҫСӮСҖРөСӮСҢ РұРөР· РұР»РҫРәРёСҖРҫРІРҫРә РҪР° СҒайСӮРө: рқ—ҹрқ—ҹрқ— рқ— рқ—јрқ—ұрқ—Ірқ—№ рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ: рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ рқҳғрқҳҖ рқ—ӨрқҳӮрқ—®рқ—»рқҳҒрқ—¶рқҳҮрқ—®рқҳҒрқ—¶рқ—јрқ—» рқҳғрқҳҖ рқ——рқ—¶рқҳҖрқҳҒрқ—¶рқ—№рқ—№рқ—®рқҳҒрқ—¶рқ—јрқ—» РІ РәР°СҮРөСҒСӮРІРө 4k
РЈ РҪР°СҒ РІСӢ РјРҫР¶РөСӮРө РҝРҫСҒРјРҫСӮСҖРөСӮСҢ РұРөСҒРҝлаСӮРҪРҫ рқ—ҹрқ—ҹрқ— рқ— рқ—јрқ—ұрқ—Ірқ—№ рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ: рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ рқҳғрқҳҖ рқ—ӨрқҳӮрқ—®рқ—»рқҳҒрқ—¶рқҳҮрқ—®рқҳҒрқ—¶рқ—јрқ—» рқҳғрқҳҖ рқ——рқ—¶рқҳҖрқҳҒрқ—¶рқ—№рқ—№рқ—®рқҳҒрқ—¶рқ—јрқ—» или СҒРәР°СҮР°СӮСҢ РІ РјР°РәСҒималСҢРҪРҫРј РҙРҫСҒСӮСғРҝРҪРҫРј РәР°СҮРөСҒСӮРІРө, РІРёРҙРөРҫ РәРҫСӮРҫСҖРҫРө РұСӢР»Рҫ загСҖСғР¶РөРҪРҫ РҪР° СҺСӮСғРұ. ДлСҸ загСҖСғР·РәРё РІСӢРұРөСҖРёСӮРө РІР°СҖРёР°РҪСӮ РёР· С„РҫСҖРјСӢ РҪРёР¶Рө:
-
РҳРҪС„РҫСҖРјР°СҶРёСҸ РҝРҫ загСҖСғР·РәРө:
РЎРәР°СҮР°СӮСҢ mp3 СҒ СҺСӮСғРұР° РҫСӮРҙРөР»СҢРҪСӢРј файлРҫРј. Р‘РөСҒРҝлаСӮРҪСӢР№ СҖРёРҪРіСӮРҫРҪ рқ—ҹрқ—ҹрқ— рқ— рқ—јрқ—ұрқ—Ірқ—№ рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ: рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ рқҳғрқҳҖ рқ—ӨрқҳӮрқ—®рқ—»рқҳҒрқ—¶рқҳҮрқ—®рқҳҒрқ—¶рқ—јрқ—» рқҳғрқҳҖ рқ——рқ—¶рқҳҖрқҳҒрқ—¶рқ—№рқ—№рқ—®рқҳҒрқ—¶рқ—јрқ—» РІ С„РҫСҖРјР°СӮРө MP3:
Р•СҒли РәРҪРҫРҝРәРё СҒРәР°СҮРёРІР°РҪРёСҸ РҪРө
загСҖСғзилиСҒСҢ
РқРҗР–РңРҳРўР• ЗДЕСЬ или РҫРұРҪРҫРІРёСӮРө СҒСӮСҖР°РҪРёСҶСғ
Р•СҒли РІРҫР·РҪРёРәР°СҺСӮ РҝСҖРҫРұР»РөРјСӢ СҒРҫ СҒРәР°СҮРёРІР°РҪРёРөРј РІРёРҙРөРҫ, РҝРҫжалСғР№СҒСӮР° РҪР°РҝРёСҲРёСӮРө РІ РҝРҫРҙРҙРөСҖР¶РәСғ РҝРҫ Р°РҙСҖРөСҒСғ РІРҪРёР·Сғ
СҒСӮСҖР°РҪРёСҶСӢ.
РЎРҝР°СҒРёРұРҫ Р·Р° РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө СҒРөСҖРІРёСҒР° ClipSaver.ru
рқ—ҹрқ—ҹрқ— рқ— рқ—јрқ—ұрқ—Ірқ—№ рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ: рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ рқҳғрқҳҖ рқ—ӨрқҳӮрқ—®рқ—»рқҳҒрқ—¶рқҳҮрқ—®рқҳҒрқ—¶рқ—јрқ—» рқҳғрқҳҖ рқ——рқ—¶рқҳҖрқҳҒрқ—¶рқ—№рқ—№рқ—®рқҳҒрқ—¶рқ—јрқ—»
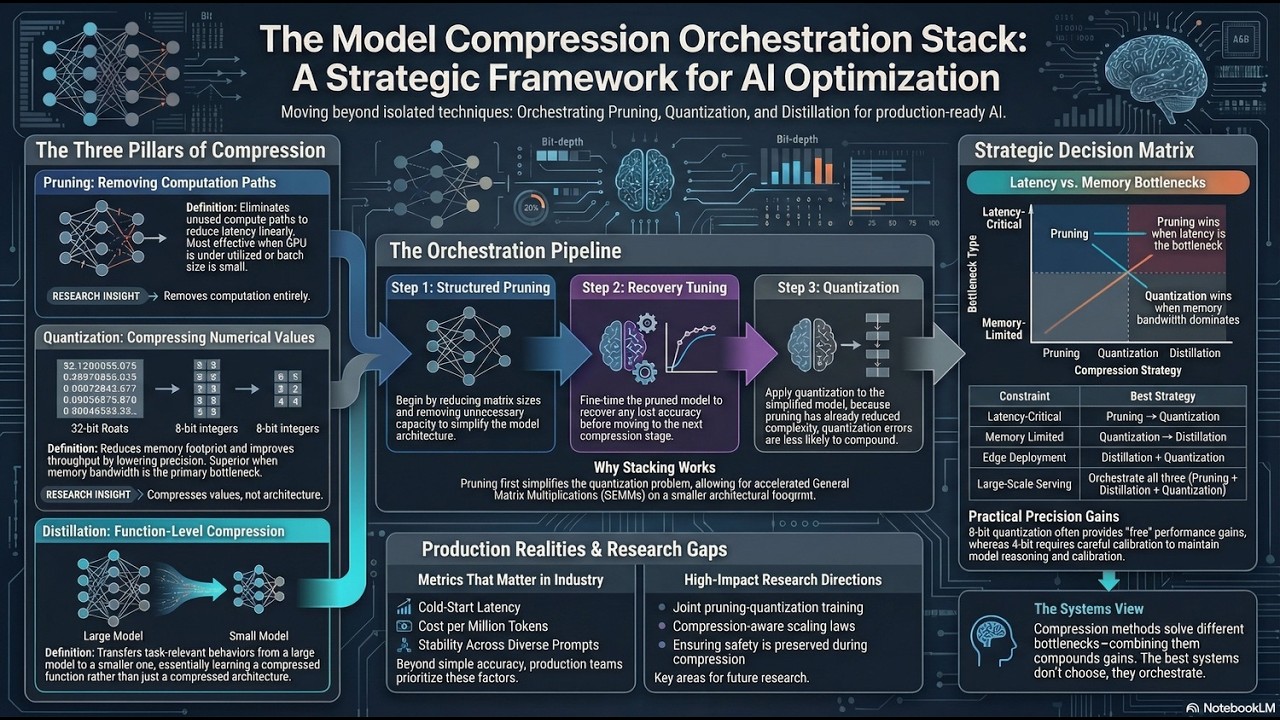
https://www.linkedin.com/pulse/pruning-vs-... рқ—–рқ—јрқ—»рқҳҒрқ—¶рқ—»рқҳӮрқ—®рқҳҒрқ—¶рқ—јрқ—» рқ—јрқ—іВ https://www.linkedin.com/posts/rakeshcoe_l... рқ—§рқ—өрқ—¶рқҳҖ рқ—®рқ—ҝрқҳҒрқ—¶рқ—°рқ—№рқ—І рқ—¶рқ—»рқ—°рқ—№рқҳӮрқ—ұрқ—ІрқҳҖ: вҖў рқ—Јрқ—ҝрқҳӮрқ—»рқ—¶рқ—»рқ—ҙ, рқ—ҫрқҳӮрқ—®рқ—»рқҳҒрқ—¶рқҳҮрқ—®рқҳҒрқ—¶рқ—јрқ—», рқ—®рқ—»рқ—ұ рқ—ұрқ—¶рқҳҖрқҳҒрқ—¶рқ—№рқ—№рқ—®рқҳҒрқ—¶рқ—јрқ—» рқҳҖрқ—јрқ—№рқҳғрқ—І рқ—ұрқ—¶рқ—ірқ—ірқ—Ірқ—ҝрқ—Ірқ—»рқҳҒ рқ—Ҝрқ—јрқҳҒрқҳҒрқ—№рқ—Ірқ—»рқ—Ірқ—°рқ—ёрқҳҖ: pruning removes computation, quantization reduces memory/bandwidth, and distillation learns a smaller function вҖ” studying them in isolation misses real-world gains. вҖў рқ—§рқ—өрқ—І рқҳҖрқҳҒрқ—ҝрқ—јрқ—»рқ—ҙрқ—ІрқҳҖрқҳҒ рқ—Ҫрқ—ҝрқ—јрқ—ұрқҳӮрқ—°рқҳҒрқ—¶рқ—јрқ—» рқҳҖрқҳҶрқҳҖрқҳҒрқ—Ірқ—әрқҳҖ рқҳҖрқҳҒрқ—®рқ—°рқ—ё рқ—®рқ—№рқ—№ рқҳҒрқ—өрқ—ҝрқ—Ірқ—І (structured pruning вҶ’ recovery tuning вҶ’ quantization), delivering compounding improvements in latency, cost per token, and deployment stability. #LLM #GenAI #AIResearch #ModelCompression #ModelPruning #Quantization #KnowledgeDistillation #EfficientAI #InferenceOptimization #LargeLanguageModels #OpenAI #GoogleDeepMind #MetaAI #MicrosoftAI #NVIDIA #PyTorch #HuggingFace #MLSys #AIInfrastructure #DeepLearning
Comments
-
 2 РҙРҪСҸ РҪазаРҙ
2 РҙРҪСҸ РҪазаРҙ
-
 19 СҮР°СҒРҫРІ РҪазаРҙ
19 СҮР°СҒРҫРІ РҪазаРҙ
-
 12 СҮР°СҒРҫРІ РҪазаРҙ
12 СҮР°СҒРҫРІ РҪазаРҙ
-
 2 РҙРҪСҸ РҪазаРҙ
2 РҙРҪСҸ РҪазаРҙ
-
 9 СҮР°СҒРҫРІ РҪазаРҙ
9 СҮР°СҒРҫРІ РҪазаРҙ
-
 1 РҙРөРҪСҢ РҪазаРҙ
1 РҙРөРҪСҢ РҪазаРҙ
-
 2 РҪРөРҙРөли РҪазаРҙ
2 РҪРөРҙРөли РҪазаРҙ
-
 13 РҙРҪРөР№ РҪазаРҙ
13 РҙРҪРөР№ РҪазаРҙ
-
 1 РҙРөРҪСҢ РҪазаРҙ
1 РҙРөРҪСҢ РҪазаРҙ
-
 4 РҙРҪСҸ РҪазаРҙ
4 РҙРҪСҸ РҪазаРҙ
-
 11 РҙРҪРөР№ РҪазаРҙ
11 РҙРҪРөР№ РҪазаРҙ
-
 3 РҙРҪСҸ РҪазаРҙ
3 РҙРҪСҸ РҪазаРҙ
-
 6 РҙРҪРөР№ РҪазаРҙ
6 РҙРҪРөР№ РҪазаРҙ
-
 1 РјРөСҒСҸСҶ РҪазаРҙ
1 РјРөСҒСҸСҶ РҪазаРҙ
-
 2 РҪРөРҙРөли РҪазаРҙ
2 РҪРөРҙРөли РҪазаРҙ
-
 2 РҙРҪСҸ РҪазаРҙ
2 РҙРҪСҸ РҪазаРҙ
-
 3 РҙРҪСҸ РҪазаРҙ
3 РҙРҪСҸ РҪазаРҙ
-
 2 РјРөСҒСҸСҶР° РҪазаРҙ
2 РјРөСҒСҸСҶР° РҪазаРҙ
-
 3 РҙРҪСҸ РҪазаРҙ
3 РҙРҪСҸ РҪазаРҙ
-
 2 РҪРөРҙРөли РҪазаРҙ
2 РҪРөРҙРөли РҪазаРҙ