The columnar roadmap: Apache Parquet and Apache Arrow скачать в хорошем качестве
The columnar roadmap: Apache Parquet and Apache Arrow
7 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: The columnar roadmap: Apache Parquet and Apache Arrow в качестве 4k
У нас вы можете посмотреть бесплатно The columnar roadmap: Apache Parquet and Apache Arrow или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон The columnar roadmap: Apache Parquet and Apache Arrow в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
The columnar roadmap: Apache Parquet and Apache Arrow
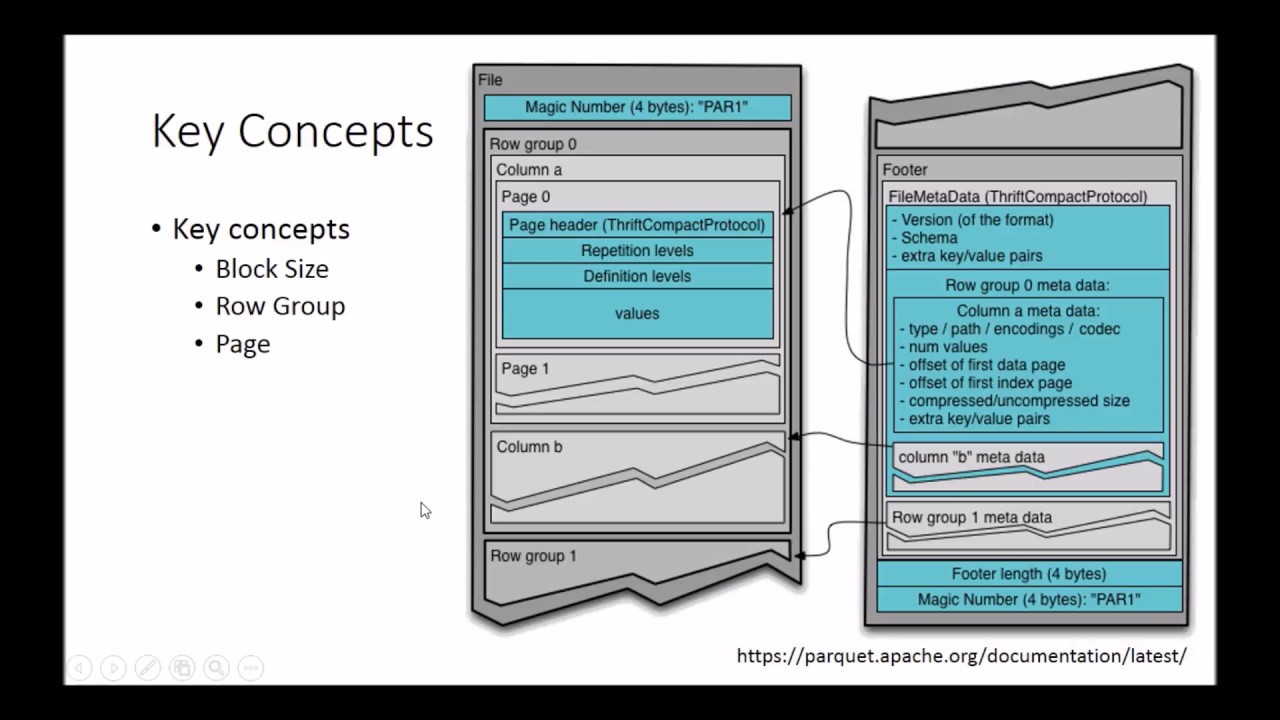
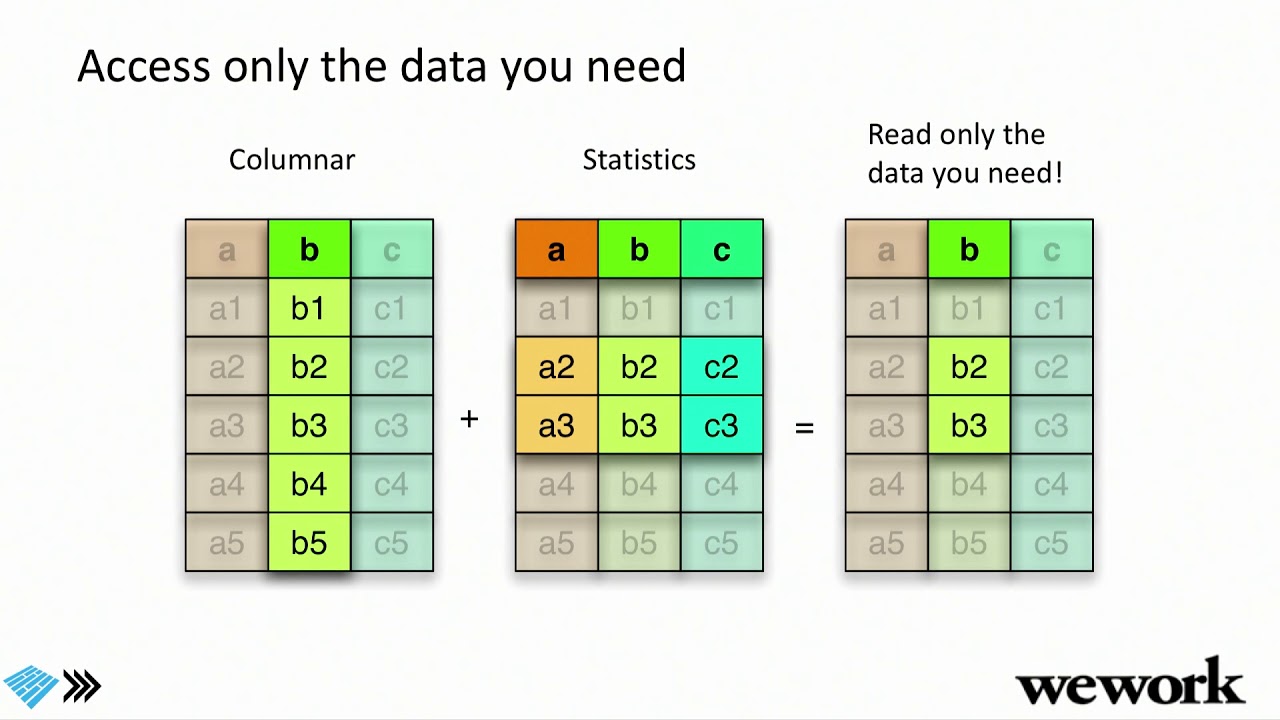
The Hadoop ecosystem has standardized on columnar formats—Apache Parquet for on-disk storage and Apache Arrow for in-memory. With this trend, deep integration with columnar formats is a key differentiator for big data technologies. Vertical integration from storage to execution greatly improves the latency of accessing data by pushing projections and filters to the storage layer, reducing time spent in IO reading from disk, as well as CPU time spent decompressing and decoding. Standards like Arrow and Parquet make this integration even more valuable as data can now cross system boundaries without incurring costly translation. Cross-system programming using languages such as Spark, Python, or SQL can becomes as fast as native internal performance. In this talk we’ll explain how Parquet is improving at the storage level, with metadata and statistics that will facilitate more optimizations in query engines in the future. We’ll detail how the new vectorized reader from Parquet to Arrow enables much faster reads by removing abstractions as well as several future improvements. We will also discuss how standard Arrow-based APIs pave the way to breaking the silos of big data. One example is Arrow-based universal function libraries that can be written in any language (Java, Scala, C++, Python, R, ...) and will be usable in any big data system (Spark, Impala, Presto, Drill). Another is a standard data access API with projection and predicate push downs, which will greatly simplify data access optimizations across the board. Speaker JULIEN LE DEM Principal Engineer WeWork
Comments