–Ы—Г—З—И–Є–є —Б–њ–Њ—Б–Њ–± —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г —Б –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е (—Е–∞–Ї —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ LSM-–і–µ—А–µ–≤–∞) —Б–Ї–∞—З–∞—В—М –≤ —Е–Њ—А–Њ—И–µ–Љ –Ї–∞—З–µ—Б—В–≤–µ
–Ы—Г—З—И–Є–є —Б–њ–Њ—Б–Њ–± —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г —Б –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е (—Е–∞–Ї —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ LSM-–і–µ—А–µ–≤–∞)
15 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
–Э–µ —Г–і–∞–µ—В—Б—П –Ј–∞–≥—А—Г–Ј–Є—В—М Youtube-–њ–ї–µ–µ—А. –Я—А–Њ–≤–µ—А—М—В–µ –±–ї–Њ–Ї–Є—А–Њ–≤–Ї—Г Youtube –≤ –≤–∞—И–µ–є —Б–µ—В–Є.
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...

–°–Ї–∞—З–∞—В—М –≤–Є–і–µ–Њ —Б —О—В—Г–± –њ–Њ —Б—Б—Л–ї–Ї–µ –Є–ї–Є —Б–Љ–Њ—В—А–µ—В—М –±–µ–Ј –±–ї–Њ–Ї–Є—А–Њ–≤–Њ–Ї –љ–∞ —Б–∞–є—В–µ: –Ы—Г—З—И–Є–є —Б–њ–Њ—Б–Њ–± —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г —Б –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е (—Е–∞–Ї —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ LSM-–і–µ—А–µ–≤–∞) –≤ –Ї–∞—З–µ—Б—В–≤–µ 4k
–£ –љ–∞—Б –≤—Л –Љ–Њ–ґ–µ—В–µ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –±–µ—Б–њ–ї–∞—В–љ–Њ –Ы—Г—З—И–Є–є —Б–њ–Њ—Б–Њ–± —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г —Б –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е (—Е–∞–Ї —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ LSM-–і–µ—А–µ–≤–∞) –Є–ї–Є —Б–Ї–∞—З–∞—В—М –≤ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–Љ –і–Њ—Б—В—Г–њ–љ–Њ–Љ –Ї–∞—З–µ—Б—В–≤–µ, –≤–Є–і–µ–Њ –Ї–Њ—В–Њ—А–Њ–µ –±—Л–ї–Њ –Ј–∞–≥—А—Г–ґ–µ–љ–Њ –љ–∞ —О—В—Г–±. –Ф–ї—П –Ј–∞–≥—А—Г–Ј–Ї–Є –≤—Л–±–µ—А–Є—В–µ –≤–∞—А–Є–∞–љ—В –Є–Ј —Д–Њ—А–Љ—Л –љ–Є–ґ–µ:
-
–Ш–љ—Д–Њ—А–Љ–∞—Ж–Є—П –њ–Њ –Ј–∞–≥—А—Г–Ј–Ї–µ:
–°–Ї–∞—З–∞—В—М mp3 —Б —О—В—Г–±–∞ –Њ—В–і–µ–ї—М–љ—Л–Љ —Д–∞–є–ї–Њ–Љ. –С–µ—Б–њ–ї–∞—В–љ—Л–є —А–Є–љ–≥—В–Њ–љ –Ы—Г—З—И–Є–є —Б–њ–Њ—Б–Њ–± —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г —Б –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е (—Е–∞–Ї —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ LSM-–і–µ—А–µ–≤–∞) –≤ —Д–Њ—А–Љ–∞—В–µ MP3:
–Х—Б–ї–Є –Ї–љ–Њ–њ–Ї–Є —Б–Ї–∞—З–Є–≤–∞–љ–Є—П –љ–µ
–Ј–∞–≥—А—Г–Ј–Є–ї–Є—Б—М
–Э–Р–Ц–Ь–Ш–Ґ–Х –Ч–Ф–Х–°–ђ –Є–ї–Є –Њ–±–љ–Њ–≤–Є—В–µ —Б—В—А–∞–љ–Є—Ж—Г
–Х—Б–ї–Є –≤–Њ–Ј–љ–Є–Ї–∞—О—В –њ—А–Њ–±–ї–µ–Љ—Л —Б–Њ —Б–Ї–∞—З–Є–≤–∞–љ–Є–µ–Љ –≤–Є–і–µ–Њ, –њ–Њ–ґ–∞–ї—Г–є—Б—В–∞ –љ–∞–њ–Є—И–Є—В–µ –≤ –њ–Њ–і–і–µ—А–ґ–Ї—Г –њ–Њ –∞–і—А–µ—Б—Г –≤–љ–Є–Ј—Г
—Б—В—А–∞–љ–Є—Ж—Л.
–°–њ–∞—Б–Є–±–Њ –Ј–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —Б–µ—А–≤–Є—Б–∞ ClipSaver.ru
–Ы—Г—З—И–Є–є —Б–њ–Њ—Б–Њ–± —Г—Б–Ї–Њ—А–Є—В—М —А–∞–±–Њ—В—Г —Б –±–∞–Ј–∞–Љ–Є –і–∞–љ–љ—Л—Е (—Е–∞–Ї —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ LSM-–і–µ—А–µ–≤–∞)
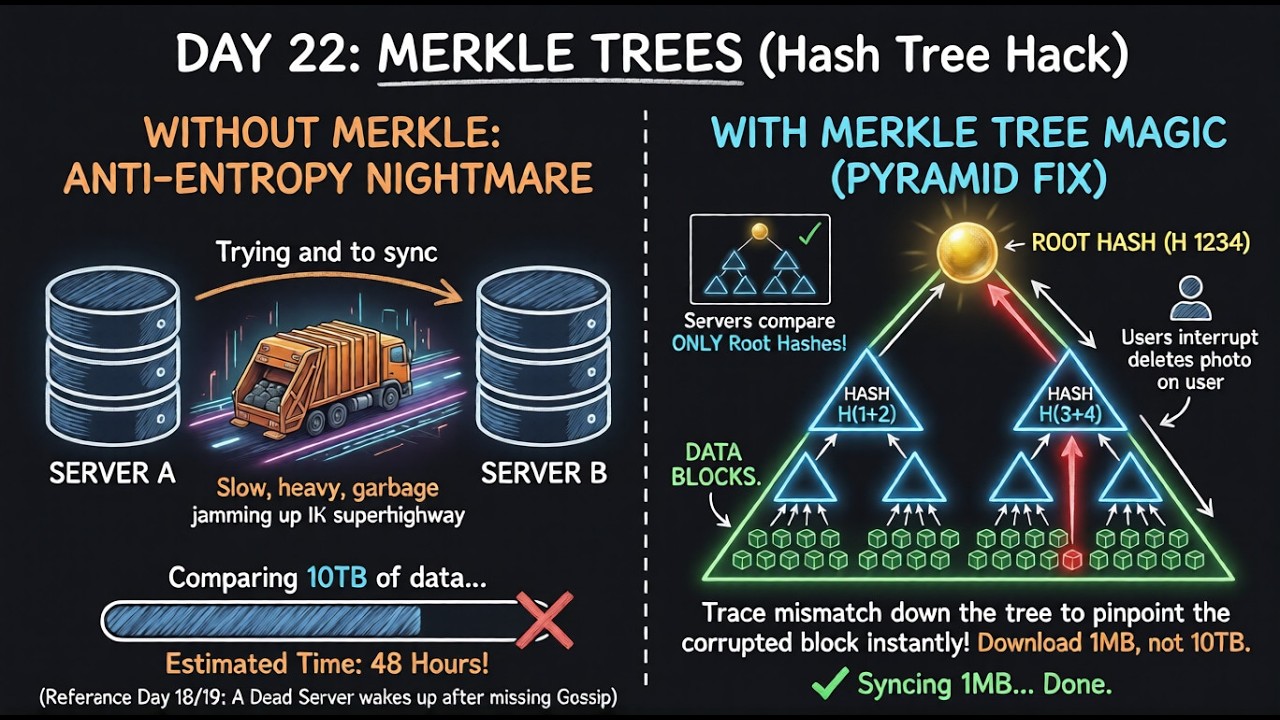
–Я–Њ–Љ–љ–Є—В–µ –Ф–µ–љ—М 23 (–§–Є–ї—М—В—А—Л –С–ї—Г–Љ–∞)? –Ь—Л —Б–Њ–Ј–і–∞–ї–Є –Є–љ—В–µ–ї–ї–µ–Ї—В—Г–∞–ї—М–љ—Л–є —Д–Є–ї—М—В—А –і–ї—П –Ј–∞—Й–Є—В—Л –љ–∞—И–µ–є –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –Њ—В –љ–µ–љ—Г–ґ–љ—Л—Е –Њ–њ–µ—А–∞—Ж–Є–є —З—В–µ–љ–Є—П. –°–µ–≥–Њ–і–љ—П –Љ—Л —Г–≥–ї—Г–±–Є–Љ—Б—П –≤ —Н—В–Њ—В –≤–Њ–њ—А–Њ—Б –Є –Ј–∞–Љ–µ–љ–Є–Љ —В—А–∞–і–Є—Ж–Є–Њ–љ–љ—Л–є –Љ–µ—Е–∞–љ–Є–Ј–Љ —Е—А–∞–љ–µ–љ–Є—П –і–∞–љ–љ—Л—Е, —З—В–Њ–±—Л –Ј–љ–∞—З–Є—В–µ–ї—М–љ–Њ —Г—Б–Ї–Њ—А–Є—В—М –Ј–∞–њ–Є—Б—М. –Х—Б–ї–Є –≤—Л –њ–Њ–Љ–љ–Є—В–µ –Ф–µ–љ—М 19 (Cassandra –Є Gossip), Cassandra –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В —В–Њ—В –ґ–µ –њ–Њ–і—Е–Њ–і –Ї —Е—А–∞–љ–µ–љ–Є—О –і–∞–љ–љ—Л—Е –і–ї—П –Њ–±—А–∞–±–Њ—В–Ї–Є –±–Њ–ї—М—И–Є—Е –Њ–±—К–µ–Љ–Њ–≤ –≤—Е–Њ–і—П—Й–Є—Е –і–∞–љ–љ—Л—Е. –Ф–Њ–±—А–Њ –њ–Њ–ґ–∞–ї–Њ–≤–∞—В—М –≤ –Ф–µ–љ—М 24 ¬Ђ100 –і–љ–µ–є –њ—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є—П —Б–Є—Б—В–µ–Љ¬ї. –°–µ–≥–Њ–і–љ—П –Љ—Л –њ–µ—А–µ–є–і–µ–Љ –Ї —Б–∞–Љ–Њ–Љ—Г –Љ–µ—Е–∞–љ–Є–Ј–Љ—Г –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –Є —А–∞—Б—Б–Љ–Њ—В—А–Є–Љ –Њ–і–љ—Г –Є–Ј —Б–∞–Љ—Л—Е –Љ–Њ—Й–љ—Л—Е –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–є —Е—А–∞–љ–µ–љ–Є—П, –Њ–њ–Є—Б–∞–љ–љ—Л—Е –≤ –Ї–љ–Є–≥–µ ¬Ђ–Я—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є–µ —А–µ—Б—Г—А—Б–Њ–µ–Љ–Ї–Є—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є¬ї. –Я—А–Њ–±–ї–µ–Љ–∞ —Б–ї—Г—З–∞–є–љ–Њ–є –Ј–∞–њ–Є—Б–Є –Ґ—А–∞–і–Є—Ж–Є–Њ–љ–љ—Л–µ –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –Њ–±–љ–Њ–≤–ї—П—О—В –Ј–∞–њ–Є—Б–Є, –≤—Л–њ–Њ–ї–љ—П—П —Б–ї—Г—З–∞–є–љ—Л–µ –Ј–∞–њ–Є—Б–Є –њ–Њ –і–Є—Б–Ї—Г –і–ї—П –њ–Њ–Є—Б–Ї–∞ –Є –Є–Ј–Љ–µ–љ–µ–љ–Є—П –Њ–њ—А–µ–і–µ–ї–µ–љ–љ—Л—Е —Б—В—А–Њ–Ї. –Ц–µ—Б—В–Ї–Є–µ –і–Є—Б–Ї–Є –Ї—А–∞–є–љ–µ –љ–µ—Н—Д—Д–µ–Ї—В–Є–≤–љ—Л –њ—А–Є –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ–Њ–Љ –і–Њ—Б—В—Г–њ–µ, —З—В–Њ –і–µ–ї–∞–µ—В —Н—В–Њ—В –њ–Њ–і—Е–Њ–і –Љ–µ–і–ї–µ–љ–љ—Л–Љ –Є –і–Њ—А–Њ–≥–Њ—Б—В–Њ—П—Й–Є–Љ –≤ –±–Њ–ї—М—И–Є—Е –Љ–∞—Б—И—В–∞–±–∞—Е. –†–µ—И–µ–љ–Є–µ: –Ц—Г—А–љ–∞–ї—Л —В–Њ–ї—М–Ї–Њ –і–ї—П –і–Њ–±–∞–≤–ї–µ–љ–Є—П –Є Memtable –Т–Љ–µ—Б—В–Њ –њ—А—П–Љ–Њ–є –Ј–∞–њ–Є—Б–Є –љ–∞ –і–Є—Б–Ї, –≤—Е–Њ–і—П—Й–Є–µ –Ј–∞–њ–Є—Б–Є —Б–љ–∞—З–∞–ї–∞ –њ–Њ–њ–∞–і–∞—О—В –≤ –±—Л—Б—В—А—Г—О —Б—В—А—Г–Ї—В—Г—А—Г –≤ –Њ–њ–µ—А–∞—В–Є–≤–љ–Њ–є –њ–∞–Љ—П—В–Є, –љ–∞–Ј—Л–≤–∞–µ–Љ—Г—О Memtable. Memtable —Е—А–∞–љ–Є—В –і–∞–љ–љ—Л–µ –≤ –њ–∞–Љ—П—В–Є –≤ –Њ—В—Б–Њ—А—В–Є—А–Њ–≤–∞–љ–љ–Њ–Љ –≤–Є–і–µ, –њ—А–Є —Н—В–Њ–Љ –Њ–±–µ—Б–њ–µ—З–Є–≤–∞—П –±—Л—Б—В—А—Г—О –Ј–∞–њ–Є—Б—М. –Я—А–Є –Ј–∞–њ–Є—Б–Є –љ–∞ –і–Є—Б–Ї —Б–Є—Б—В–µ–Љ–∞ –Є–Ј–±–µ–≥–∞–µ—В –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ–Њ–≥–Њ –і–Њ—Б—В—Г–њ–∞ –Є –≤—Л–њ–Њ–ї–љ—П–µ—В –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ—Г—О –Ј–∞–њ–Є—Б—М, –Ї–Њ—В–Њ—А–∞—П –Ј–љ–∞—З–Є—В–µ–ї—М–љ–Њ –±—Л—Б—В—А–µ–µ. –Ю—З–Є—Б—В–Ї–∞ SSTable –Ъ–∞–Ї —В–Њ–ї—М–Ї–Њ Memtable –і–Њ—Б—В–Є–≥–∞–µ—В —Б–≤–Њ–µ–≥–Њ –њ—А–µ–і–µ–ї–∞ —А–∞–Ј–Љ–µ—А–∞, –Њ–љ –Њ—З–Є—Й–∞–µ—В—Б—П –љ–∞ –і–Є—Б–Ї –≤ –≤–Є–і–µ SSTable (–Њ—В—Б–Њ—А—В–Є—А–Њ–≤–∞–љ–љ–Њ–є —Б—В—А–Њ–Ї–Њ–≤–Њ–є —В–∞–±–ї–Є—Ж—Л). –≠—В–Њ—В —Д–∞–є–ї —П–≤–ї—П–µ—В—Б—П –љ–µ–Є–Ј–Љ–µ–љ—П–µ–Љ—Л–Љ –Є –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В—Б—П –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ–Њ, —З—В–Њ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –±–∞–Ј–µ –і–∞–љ–љ—Л—Е —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ —Б–Њ—Е—А–∞–љ—П—В—М –±–Њ–ї—М—И–Є–µ –Њ–±—К–µ–Љ—Л –Њ—В—Б–Њ—А—В–Є—А–Њ–≤–∞–љ–љ—Л—Е –і–∞–љ–љ—Л—Е. –Я—Г—В—М —З—В–µ–љ–Є—П –Ф–ї—П —З—В–µ–љ–Є—П –і–∞–љ–љ—Л—Е —Б–Є—Б—В–µ–Љ–∞ —Б–љ–∞—З–∞–ї–∞ –њ—А–Њ–≤–µ—А—П–µ—В Memtable. –Х—Б–ї–Є –Ј–∞–њ–Є—Б—М –Њ—В—Б—Г—В—Б—В–≤—Г–µ—В, –Њ–љ–∞ –Є—Й–µ—В –≤ —Б–∞–Љ—Л—Е –њ–Њ—Б–ї–µ–і–љ–Є—Е SSTable, –∞ –Ј–∞—В–µ–Љ –≤ –±–Њ–ї–µ–µ —Б—В–∞—А—Л—Е. –§–Є–ї—М—В—А—Л –С–ї—Г–Љ–∞ –њ–Њ–Љ–Њ–≥–∞—О—В –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М —Н—В–Њ—В –њ—А–Њ—Ж–µ—Б—Б, –±—Л—Б—В—А–Њ –Њ–њ—А–µ–і–µ–ї—П—П, –Ї–∞–Ї–Є–µ SSTable —В–Њ—З–љ–Њ –љ–µ —Б–Њ–і–µ—А–ґ–∞—В –Ј–∞–њ—А–Њ—И–µ–љ–љ—Л–є –Ї–ї—О—З, –Є–Ј–±–µ–≥–∞—П –љ–µ–љ—Г–ґ–љ—Л—Е –Њ–±—А–∞—Й–µ–љ–Є–є –Ї –і–Є—Б–Ї—Г. –≠—В–∞ –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ –њ–Њ–Ј–≤–Њ–ї—П–µ—В –±–∞–Ј–∞–Љ –і–∞–љ–љ—Л—Е –Њ–±—А–∞–±–∞—В—Л–≤–∞—В—М —З—А–µ–Ј–≤—Л—З–∞–є–љ–Њ –≤—Л—Б–Њ–Ї—Г—О –њ—А–Њ–њ—Г—Б–Ї–љ—Г—О —Б–њ–Њ—Б–Њ–±–љ–Њ—Б—В—М –Ј–∞–њ–Є—Б–Є. –Ю–і–љ–∞–Ї–Њ —Б–Њ –≤—А–µ–Љ–µ–љ–µ–Љ –љ–∞ –і–Є—Б–Ї–µ –љ–∞–Ї–∞–њ–ї–Є–≤–∞–µ—В—Б—П –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ SSTable. –Т 25-–є –і–µ–љ—М –Љ—Л —А–∞—Б—Б–Љ–Њ—В—А–Є–Љ –Ї–Њ–Љ–њ–∞–Ї—В–Є–Ј–∞—Ж–Є—О –Є —В–Њ, –Ї–∞–Ї –±–∞–Ј—Л –і–∞–љ–љ—Л—Е —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ —Г–њ—А–∞–≤–ї—П—О—В —Н—В–Є–Љ–Є —Д–∞–є–ї–∞–Љ–Є –Є –Њ–±—К–µ–і–Є–љ—П—О—В –Є—Е, –∞ —В–∞–Ї–ґ–µ –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Њ–µ —Б—А–∞–≤–љ–µ–љ–Є–µ B-–і–µ—А–µ–≤—М–µ–≤. –°—Б—Л–ї–Ї–Є: ¬Ђ–Я—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є–µ —А–µ—Б—Г—А—Б–Њ–µ–Љ–Ї–Є—Е –њ—А–Є–ї–Њ–ґ–µ–љ–Є–є¬ї –Ь–∞—А—В–Є–љ–∞ –Ъ–ї–µ–њ–њ–Љ–∞–љ–∞ (–•—А–∞–љ–µ–љ–Є–µ –Є –Є–Ј–≤–ї–µ—З–µ–љ–Є–µ –і–∞–љ–љ—Л—Е) #–Я—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є–µ–°–Є—Б—В–µ–Љ #LSMTrees #SSTables #–С—Н–Ї–µ–љ–і–Ш–љ–ґ–µ–љ–µ—А–Є—П #–Я—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є–µ–С–∞–Ј–Ф–ї—П–Я—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є—П #Cassandra #–Р—А—Е–Є—В–µ–Ї—В—Г—А–∞–Я—А–Њ–≥—А–∞–Љ–Љ–љ–Њ–≥–Њ–Ю–±—А–∞–Ј–Њ–≤–∞–љ–Є—П #DDIA #–Ґ–µ—Е–љ–Є—З–µ—Б–Ї–Њ–µ–Ш–љ—В–µ—А–≤—М—О #100–Ф–љ–µ–є–Я—А–Њ–µ–Ї—В–Є—А–Њ–≤–∞–љ–Є—П–°–Є—Б—В–µ–Љ #–Ь–∞—Б—И—В–∞–±–Є—А—Г–µ–Љ–Њ—Б—В—М #–•—А–∞–љ–µ–љ–Є–µ–Ф–∞–љ–љ—Л–µ
Comments
-
 2 –і–љ—П –љ–∞–Ј–∞–і
2 –і–љ—П –љ–∞–Ј–∞–і
-
 15 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
15 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
-
 4 –і–љ—П –љ–∞–Ј–∞–і
4 –і–љ—П –љ–∞–Ј–∞–і
-
 3 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
3 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 21 —З–∞—Б –љ–∞–Ј–∞–і
21 —З–∞—Б –љ–∞–Ј–∞–і
-
 5 –і–љ–µ–є –љ–∞–Ј–∞–і
5 –і–љ–µ–є –љ–∞–Ј–∞–і
-
 7 –і–љ–µ–є –љ–∞–Ј–∞–і
7 –і–љ–µ–є –љ–∞–Ј–∞–і
-
 2 –і–љ—П –љ–∞–Ј–∞–і
2 –і–љ—П –љ–∞–Ј–∞–і
-
 19 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
19 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
-
 1 –і–µ–љ—М –љ–∞–Ј–∞–і
1 –і–µ–љ—М –љ–∞–Ј–∞–і
-
 3 –і–љ—П –љ–∞–Ј–∞–і
3 –і–љ—П –љ–∞–Ј–∞–і
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 3 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
3 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 22 —З–∞—Б–∞ –љ–∞–Ј–∞–і
22 —З–∞—Б–∞ –љ–∞–Ј–∞–і
-
 4 –і–љ—П –љ–∞–Ј–∞–і
4 –і–љ—П –љ–∞–Ј–∞–і
-
 1 –і–µ–љ—М –љ–∞–Ј–∞–і
1 –і–µ–љ—М –љ–∞–Ј–∞–і
-
 11 –і–љ–µ–є –љ–∞–Ј–∞–і
11 –і–љ–µ–є –љ–∞–Ј–∞–і
-
 1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
-
 2 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
2 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
-
 2 –і–љ—П –љ–∞–Ј–∞–і
2 –і–љ—П –љ–∞–Ј–∞–і