gMLP (Gated Multi-Layer Perceptron) Explained in 3 Minutes! скачать в хорошем качестве
gMLP (Gated Multi-Layer Perceptron) Explained in 3 Minutes!
2 недели назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: gMLP (Gated Multi-Layer Perceptron) Explained in 3 Minutes! в качестве 4k
У нас вы можете посмотреть бесплатно gMLP (Gated Multi-Layer Perceptron) Explained in 3 Minutes! или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон gMLP (Gated Multi-Layer Perceptron) Explained in 3 Minutes! в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
gMLP (Gated Multi-Layer Perceptron) Explained in 3 Minutes!
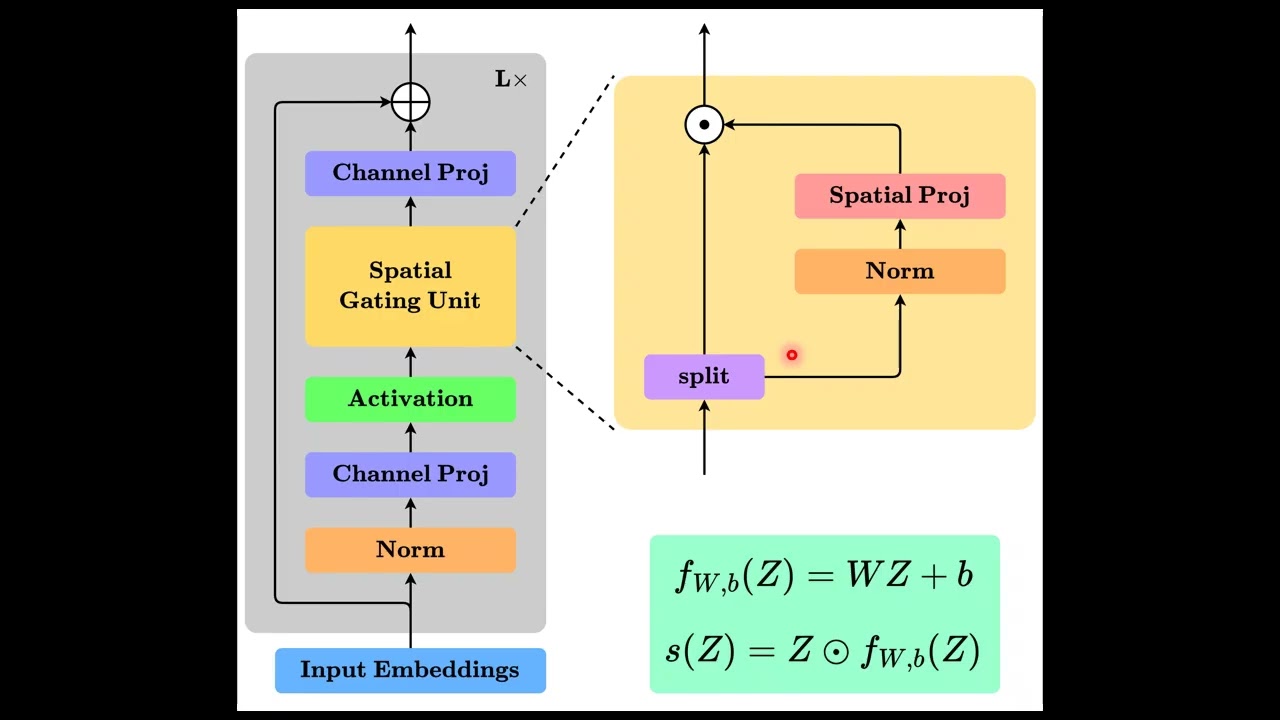
Can simple MLPs rival the power of Transformers? In this video, we break down gMLP (Gated Multi-Layer Perceptron), an architecture that challenges the dominance of self-attention in deep learning. Since 2017, Transformers have been the "holy grail" of AI, but do we actually need complex attention mechanisms for every task? We explore how gMLP uses a Spatial Gating Unit (SGU) to enable token communication and achieve impressive results in NLP and Vision without a single attention head. What you’ll learn in 3 minutes: ✅ The limitations of standard MLPs in modeling long-range dependencies. ✅ Why Transformers are powerful (and why we’re questioning them). ✅ The architecture of a gMLP block: Channel-wise projection and normalization. ✅ How the Spatial Gating Unit (SGU) uses linear projection to create dynamic gates. Chapters: [00:00] The Dominance of Transformers [00:37] Why Self-Attention is the Current Standard [01:05] MLPs as Universal Functional Approximators [01:36] The gMLP Architecture Explained [02:05] Solving Spatial Communication with the Gating Unit (SGU) [02:53] How the Hadamard Product Controls Information Flow Papers & Resources: 📄 Pay Attention to MLPs (gMLP Paper): https://arxiv.org/abs/2105.08050 🔗 Follow for more 3-minute AI deep dives! #machinelearning #deeplearning #Transformers #attention #gMLP #NeurIPS #AIResearch #visiontransformers #nlp #mlp
Comments