Analizador Sintáctico y Léxico con Python (PLY) скачать в хорошем качестве
Analizador Sintáctico y Léxico con Python (PLY)
2 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Analizador Sintáctico y Léxico con Python (PLY) в качестве 4k
У нас вы можете посмотреть бесплатно Analizador Sintáctico y Léxico con Python (PLY) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Analizador Sintáctico y Léxico con Python (PLY) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Analizador Sintáctico y Léxico con Python (PLY)
Integrantes del equipo:
• Carrasco Alcántara Arleth
• Duran Ventura Alexis Uriel
• Gómez Soto Brandon Javier
• Silva Bata Miguel Ángel
Te dejo los enlaces:
Descargar python: https://www.python.org/downloads/
Repositorio de github: https://github.com/dabeaz/ply
Solución por si python no aparece en consola: • ¡Solución! Python no se reconoce como un c...
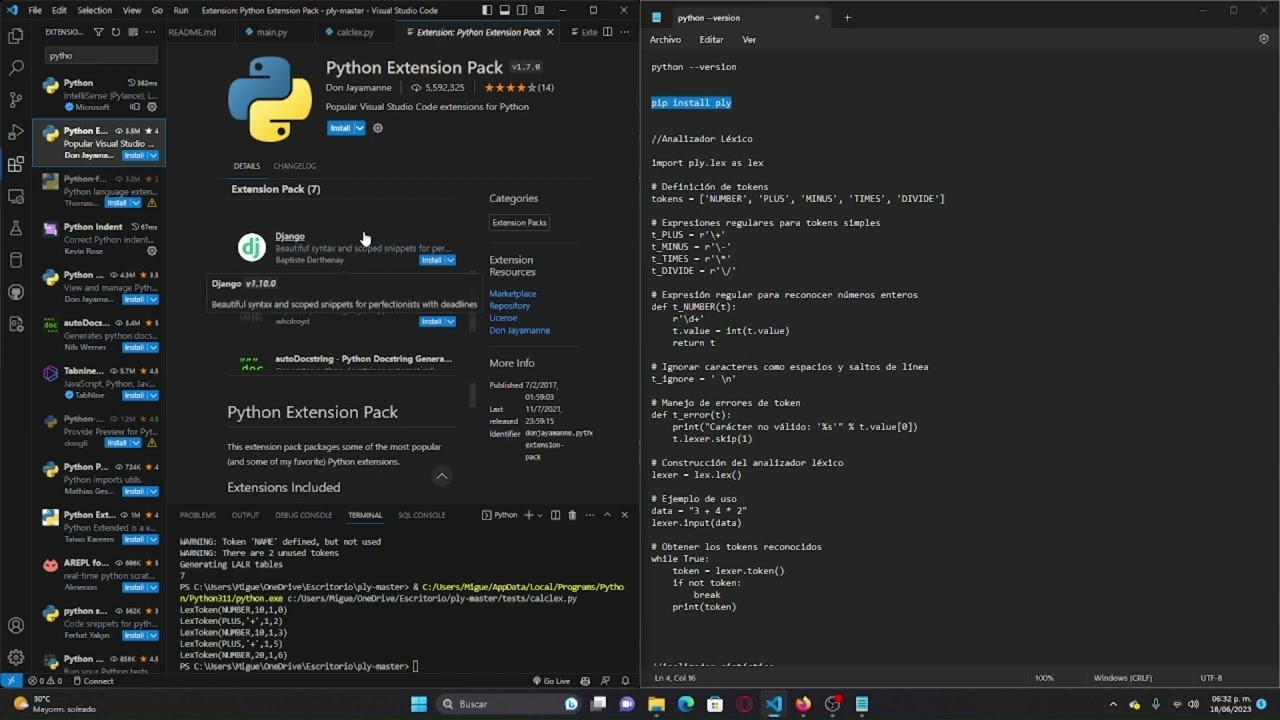
Verificar si se instaló python: python --version
Intalación necesaria: pip install ply
//Analizador Léxico
import ply.lex as lex
Definición de tokens
tokens = ['NUMBER', 'PLUS', 'MINUS', 'TIMES', 'DIVIDE']
Expresiones regulares para tokens simples
t_PLUS = r'\+'
t_MINUS = r'\-'
t_TIMES = r'\*'
t_DIVIDE = r'\/'
Expresión regular para reconocer números enteros
def t_NUMBER(t):
r'\d+'
t.value = int(t.value)
return t
Ignorar caracteres como espacios y saltos de línea
t_ignore = '
'
Manejo de errores de token
def t_error(t):
print("Carácter no válido: '%s'" % t.value[0])
t.lexer.skip(1)
Construcción del analizador léxico
lexer = lex.lex()
Ejemplo de uso
data = "3 + 4 * 2"
lexer.input(data)
Obtener los tokens reconocidos
while True:
token = lexer.token()
if not token:
break
print(token)
//Analizador sintáctico
import ply.yacc as yacc
from calclex import tokens
Reglas de precedencia
precedence = (
('left', 'PLUS', 'MINUS'),
('left', 'TIMES', 'DIVIDE'),
)
Reglas de producción
def p_expression_binop(p):
'''expression : expression PLUS expression
| expression MINUS expression
| expression TIMES expression
| expression DIVIDE expression'''
if p[2] == '+':
p[0] = p[1] + p[3]
elif p[2] == '-':
p[0] = p[1] - p[3]
elif p[2] == '*':
p[0] = p[1] * p[3]
elif p[2] == '/':
p[0] = p[1] / p[3]
def p_expression_number(p):
'expression : NUMBER'
p[0] = p[1]
def p_expression_parentheses(p):
'expression : LPAREN expression RPAREN'
p[0] = p[2]
Manejo de errores de sintaxis
def p_error(p):
print("Error de sintaxis en la entrada:", p)
Construcción del analizador sintáctico
yacc.yacc()
Ejemplo de uso
data = "3 + 4 * (2 - 1)"
result = yacc.parse(data)
print(result)
python --version
pip install ply
//Analizador Léxico
import ply.lex as lex
Definición de tokens
tokens = ['NUMBER', 'PLUS', 'MINUS', 'TIMES', 'DIVIDE']
Expresiones regulares para tokens simples
t_PLUS = r'\+'
t_MINUS = r'\-'
t_TIMES = r'\*'
t_DIVIDE = r'\/'
Expresión regular para reconocer números enteros
def t_NUMBER(t):
r'\d+'
t.value = int(t.value)
return t
Ignorar caracteres como espacios y saltos de línea
t_ignore = '
'
Manejo de errores de token
def t_error(t):
print("Carácter no válido: '%s'" % t.value[0])
t.lexer.skip(1)
Construcción del analizador léxico
lexer = lex.lex()
Ejemplo de uso
data = "3 + 4 * 2"
lexer.input(data)
Obtener los tokens reconocidos
while True:
token = lexer.token()
if not token:
break
print(token)
//Analizador sintáctico
import ply.yacc as yacc
from calclex import tokens
Reglas de precedencia
precedence = (
('left', 'PLUS', 'MINUS'),
('left', 'TIMES', 'DIVIDE'),
)
Reglas de producción
def p_expression_binop(p):
'''expression : expression PLUS expression
| expression MINUS expression
| expression TIMES expression
| expression DIVIDE expression'''
if p[2] == '+':
p[0] = p[1] + p[3]
elif p[2] == '-':
p[0] = p[1] - p[3]
elif p[2] == '*':
p[0] = p[1] * p[3]
elif p[2] == '/':
p[0] = p[1] / p[3]
def p_expression_number(p):
'expression : NUMBER'
p[0] = p[1]
def p_expression_parentheses(p):
'expression : LPAREN expression RPAREN'
p[0] = p[2]
Manejo de errores de sintaxis
def p_error(p):
print("Error de sintaxis en la entrada:", p)
Construcción del analizador sintáctico
yacc.yacc()
Ejemplo de uso
data = "3 + 4 * (2 - 1)"
result = yacc.parse(data)
print(result)
Comments















![Divine Music - The Year Mix Vol.10 [Chill & Ethnic Deep 2025]](https://imager.clipsaver.ru/Q3XBH_FhuKY/max.jpg)



