Exploring Simple Siamese Representation Learning скачать в хорошем качестве
Exploring Simple Siamese Representation Learning
5 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Exploring Simple Siamese Representation Learning в качестве 4k
У нас вы можете посмотреть бесплатно Exploring Simple Siamese Representation Learning или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Exploring Simple Siamese Representation Learning в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Exploring Simple Siamese Representation Learning
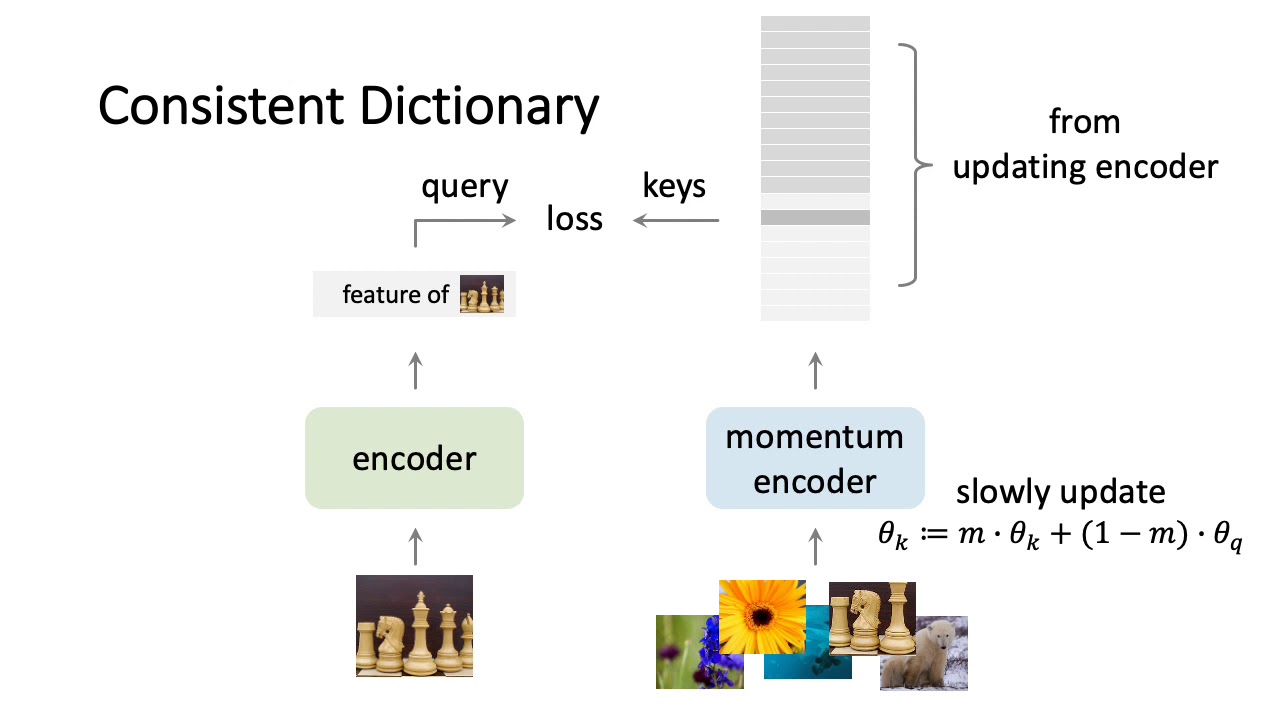
What makes contrastive learning work so well? This paper highlights the contribution of the Siamese architecture as a compliment to data augmentation and shows how Siamese nets + a stop-gradient operation in the negative encoder is all you need for strong contrastive self-supervised learning results. The paper also presents an interesting k-Means style explanation of the optimization problem contrastive self-supervised learning solves. Thanks for watching! Please Subscribe! Paper Links: SimSiam: https://arxiv.org/pdf/2011.10566.pdf SimCLR: https://arxiv.org/pdf/2002.05709.pdf MoCo: https://arxiv.org/pdf/1911.05722.pdf SwAV: https://arxiv.org/pdf/2006.09882.pdf BYOL: https://arxiv.org/pdf/2006.07733.pdf kMeans: https://stanford.edu/~cpiech/cs221/ha... (Not mentioned in video, but here's an interesting tutorial on coding siamese nets: https://www.pyimagesearch.com/2020/11...) Thanks for watching! Chapters 0:00 Introduction 1:16 SimSiam Architecture 2:42 Representation Collapse 3:41 SimCLR 4:50 MoCo 5:54 BYOL 7:00 SwaV (Clustering) 8:20 Unifying View 9:33 k-Means optimization problem 11:06 Results 12:20 Key Takeaways
Comments









![Как происходит модернизация остаточных соединений [mHC]](https://imager.clipsaver.ru/jYn_1PpRzxI/max.jpg)