Micro partitions in Snowflake скачать в хорошем качестве
Micro partitions in Snowflake
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Micro partitions in Snowflake в качестве 4k
У нас вы можете посмотреть бесплатно Micro partitions in Snowflake или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Micro partitions in Snowflake в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Micro partitions in Snowflake
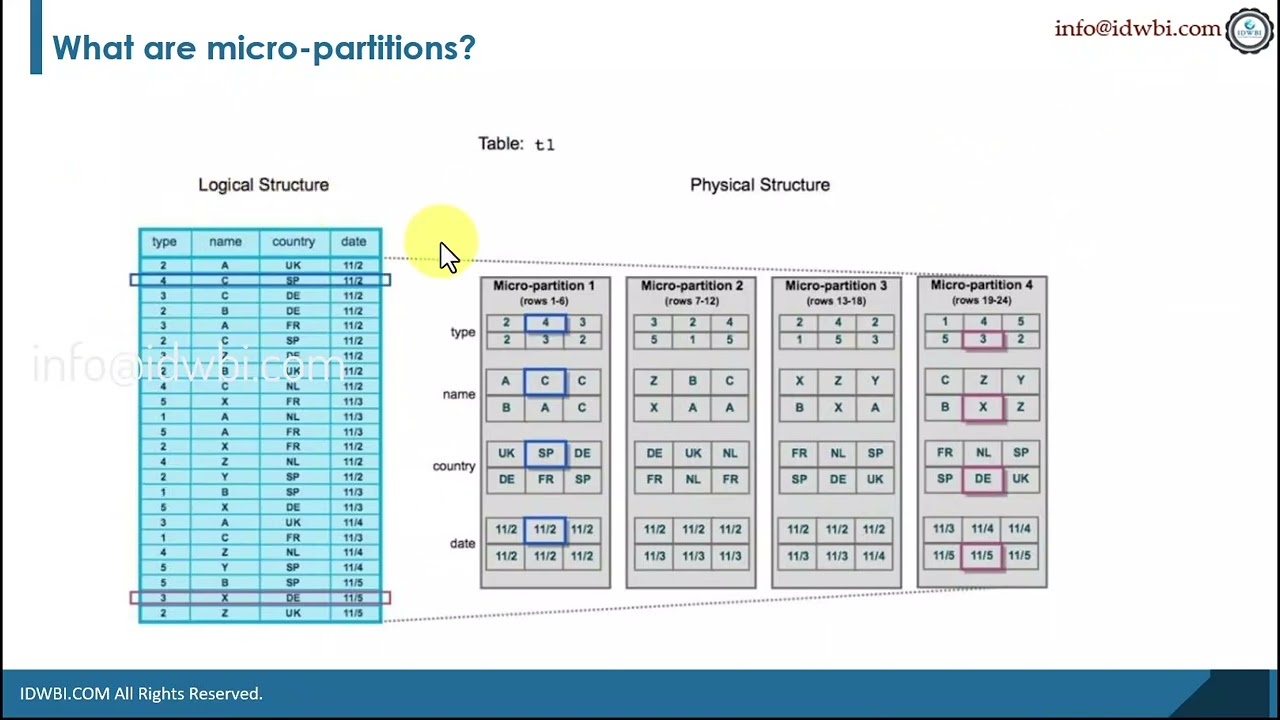
All data in Snowflake tables is automatically divided into micro-partitions with each partition containing between 50 MB and 500 MB of uncompressed data. Each micro-partition maps to a group of rows and is organized in a columnar fashion. This size and structure allows for both optimization and efficiency in query processing. Micro-partitions allow users to perform extremely efficient DML and fine-grained pruning on very large tables, which can be composed of millions, or even hundreds of millions, of micro-partitions. In simpler words, if a query specifies a filter predicate on a range of values that accesses 30% of the values in the range, it should ideally only scan the portion of the micro-partitions that contain the data, in this case, 30% of the values. Micro-partitions are derived automatically as data is ingested in Snowflake; they don’t need to be explicitly defined up-front or maintained by users. Unlike tables in traditional data warehouses that typically have a relatively small number of partitions (for example, 1 partition per day and per product), a table in Snowflake can easily have millions of partitions.
Comments