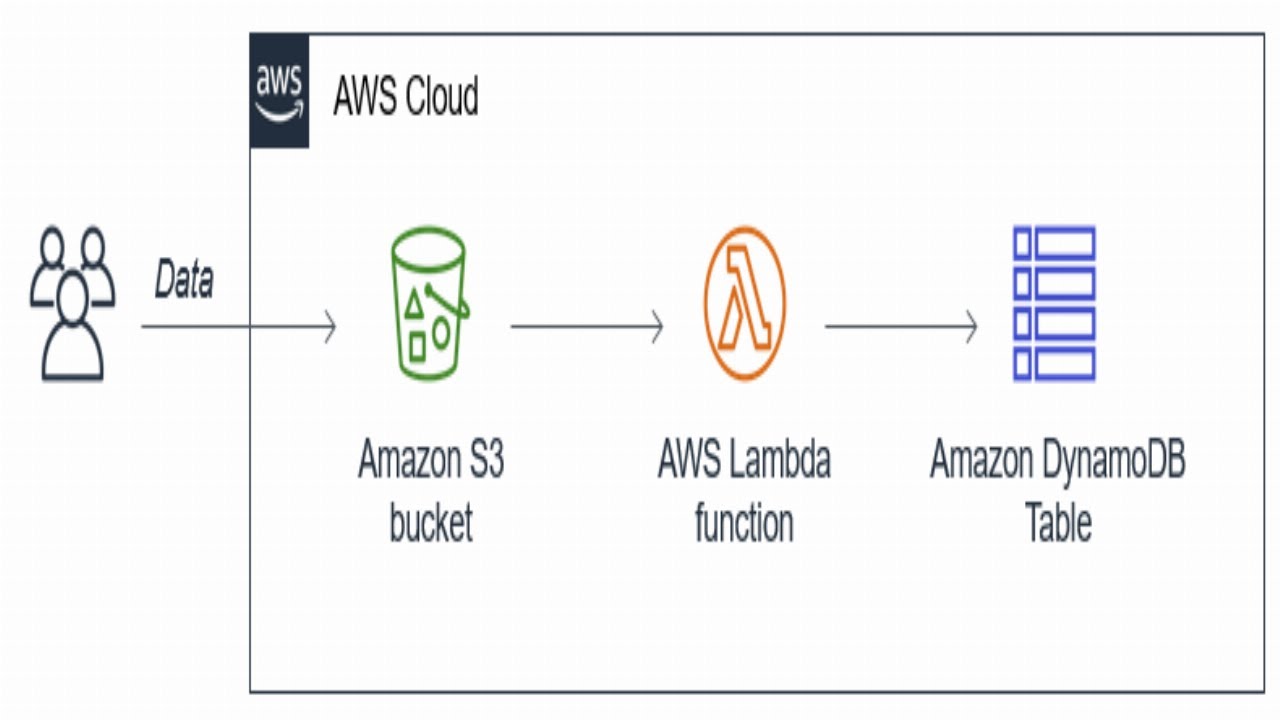
Как асинхронно извлечь данные таблицы PDF-файла с помощью Amazon Textract и AWS Lambda скачать в хорошем качестве
Как асинхронно извлечь данные таблицы PDF-файла с помощью Amazon Textract и AWS Lambda
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Как асинхронно извлечь данные таблицы PDF-файла с помощью Amazon Textract и AWS Lambda в качестве 4k
У нас вы можете посмотреть бесплатно Как асинхронно извлечь данные таблицы PDF-файла с помощью Amazon Textract и AWS Lambda или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Как асинхронно извлечь данные таблицы PDF-файла с помощью Amazon Textract и AWS Lambda в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Как асинхронно извлечь данные таблицы PDF-файла с помощью Amazon Textract и AWS Lambda
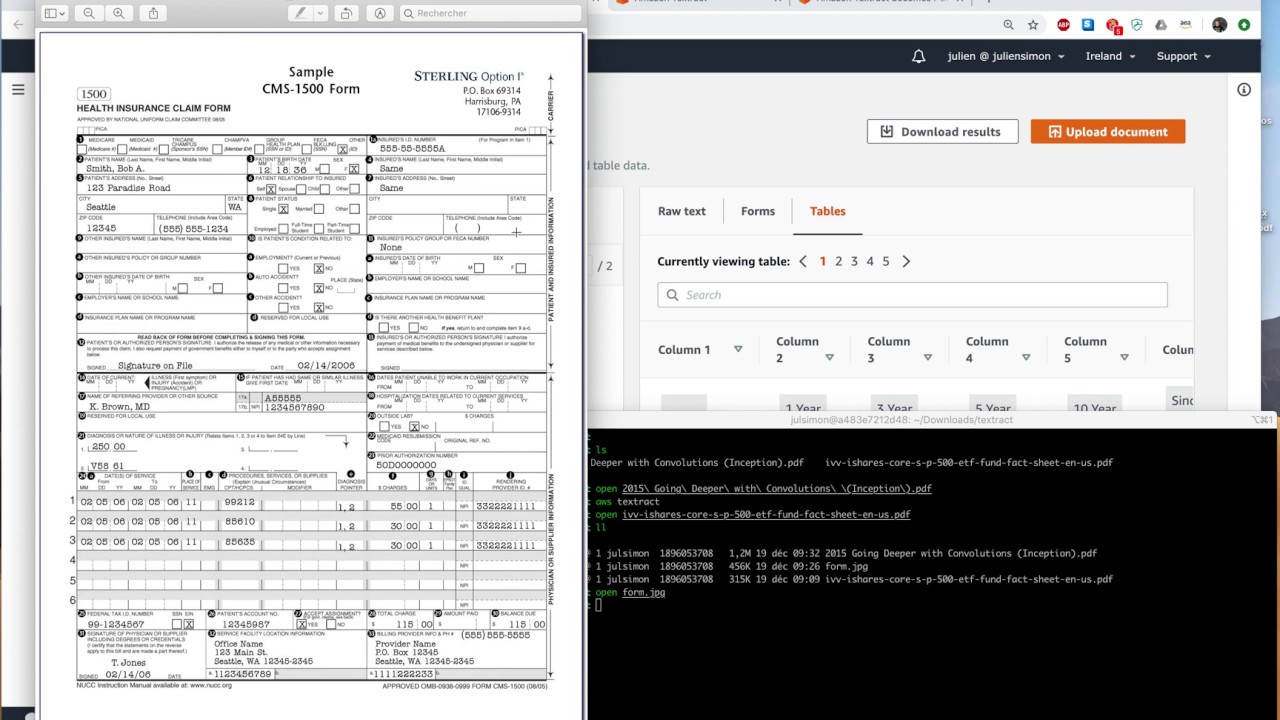
======================================================================= 1. ПОДПИШИТЕСЬ, ЧТОБЫ УЗНАТЬ БОЛЬШЕ: / @cloudquicklabs ========================================================================== 2. БЫСТРЫЕ ЛАБОРАТОРНЫЕ ЗАНЯТИЯ В ОБЛАКЕ — ПОДПИШИТЕСЬ НА КАНАЛ, ЧТОБЫ ПОЛУЧИТЬ БОЛЬШЕ ПРЕИМУЩЕСТВ : / @cloudquicklabs ======================================================================== 3. КУПИТЕ МНЕ КОФЕ В ЗНАК БЛАГОДАРНОСТИ: https://www.buymeacoffee.com/cloudqui... ======================================================================= В этом видео показано, как асинхронно извлекать данные из таблицы PDF-файла с помощью Amazon Textract и AWS Lambda. В этом видео представлена схема проекта и объяснение процесса. В нём также представлен разбор кода и демонстрация решения. Это видео поможет инженерам данных AWS, архитекторам AWS, специалистам по малому и среднему бизнесу и т.д. Использованный файл кода и модуль слоя Lambda можно найти по ссылке: https://github.com/RekhuGopal/PythonH... #AmazonTextract #Textract #aws #python #pdftabledata
Comments










![AWS re:Invent 2018: [NEW LAUNCH!] Introducing Amazon Textract: Now in Preview (AIM363)](https://imager.clipsaver.ru/FnZFK_2oqKk/max.jpg)
![Почему работает теория шести рукопожатий? [Veritasium]](https://imager.clipsaver.ru/ggI1xKzoANs/max.jpg)