EMPO2: Exploratory Memory-Augmented LLM Agents via Hybrid RL Optimization скачать в хорошем качестве
EMPO2: Exploratory Memory-Augmented LLM Agents via Hybrid RL Optimization
11 часов назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: EMPO2: Exploratory Memory-Augmented LLM Agents via Hybrid RL Optimization в качестве 4k
У нас вы можете посмотреть бесплатно EMPO2: Exploratory Memory-Augmented LLM Agents via Hybrid RL Optimization или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон EMPO2: Exploratory Memory-Augmented LLM Agents via Hybrid RL Optimization в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
EMPO2: Exploratory Memory-Augmented LLM Agents via Hybrid RL Optimization
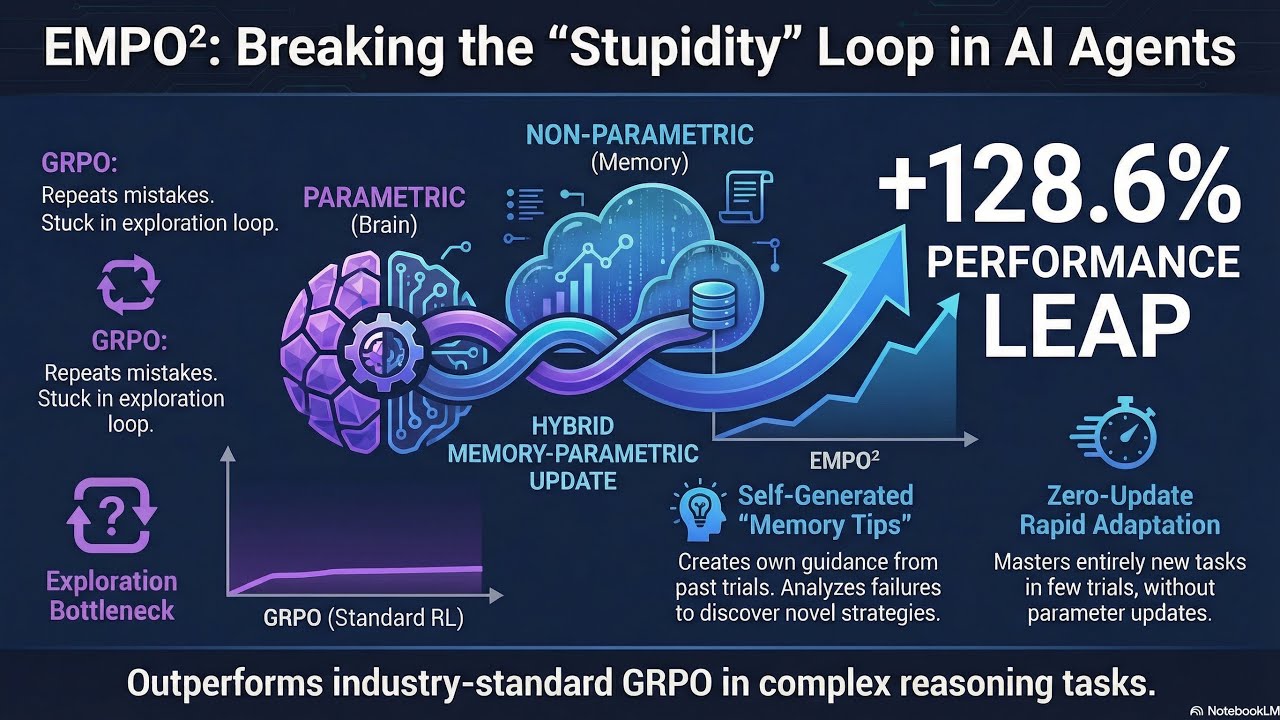
We propose a new reinforcement learning framework called EMPO² to innovatively improve the search ability of the giant language model (LLM) agent. Existing agents relied only on prior knowledge to limit the unfamiliar environment, but this method combines non-parametric external memory and parameter updates to induce autonomous learning from past failures. Agents use self-generated *reflective tips* to reduce trial and error, and systematically internalize these guides into the model through the off-polish knowledge distillation process. As a result of the experiment, complex benchmarks such as ScienceWorld and WebShop demonstrated more than twice the performance improvement and excellent adaptability than traditional algorithms. As a result, this technology shows that agents can achieve long-term evolution through self-directed search without external help. https://arxiv.org/pdf/2602.23008
Comments