LoRA: эффективная адаптация LLM без полного дообучения скачать в хорошем качестве
LoRA: эффективная адаптация LLM без полного дообучения
5 месяцев назад
LoRA
что такое LoRA
адаптация ИИ
Low-Rank Adaptation
большие языковые модели
GPT-3
как дообучить нейросеть
эффективная адаптация ИИ
fine-tuning
донастройка моделей
проблема гигантских ИИ
низкоранговая адаптация
как работает LoRA
параметры нейросети
заморозка весов
обучаемые матрицы
результаты LoRA
снижение требований к ресурсам
демократизация ИИ
кастомизация моделей
будущее искусственного интеллекта
Microsoft
научная работа
инновации в ИИ
обучение ИИ
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: LoRA: эффективная адаптация LLM без полного дообучения в качестве 4k
У нас вы можете посмотреть бесплатно LoRA: эффективная адаптация LLM без полного дообучения или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон LoRA: эффективная адаптация LLM без полного дообучения в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
LoRA: эффективная адаптация LLM без полного дообучения
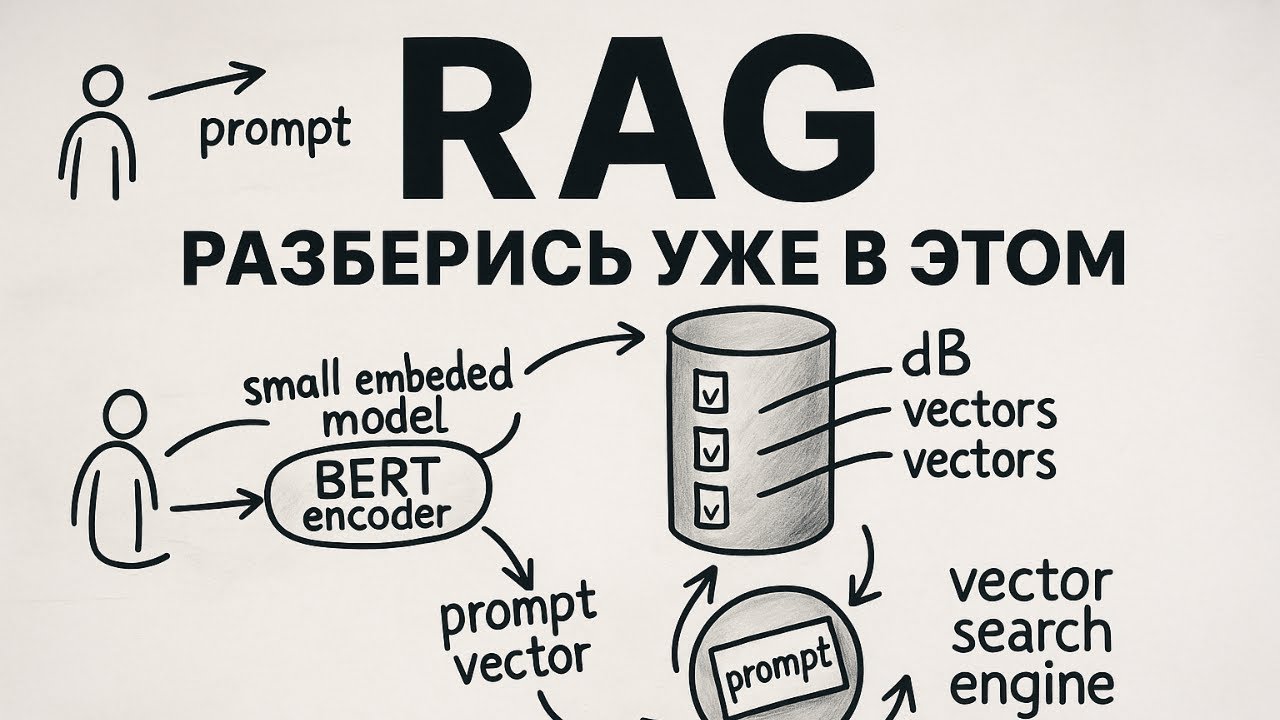
Обзор на научную статью «LoRA: Low-Rank Adaptation of Large Language Models» (Низкоранговая адаптация больших языковых моделей), в которой предлагается параметр-эффективный метод адаптации LLM. Вместо полного дообучения огромных моделей (например, GPT-3 на 175B параметров) LoRA замораживает исходные веса и вводит небольшие обучаемые низкоранговые матрицы разложения в слоях Transformer. Такой подход радикально уменьшает число обучаемых параметров (до ~10 000× для GPT-3) и снижает требования к памяти GPU, достигая при этом качества, сравнимого с полным fine-tuning. Важное практическое преимущество: на этапе инференса дополнительные матрицы могут быть слиты с базовыми весами, поэтому метод не добавляет задержки — в отличие от адаптеров или prefix-tuning. Источник: Статья "LoRA: Low-Rank Adaptation of Large Language Models", arXiv:2106.09685 Авторы: Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen 00:00 — LoRA: эффективная адаптация ИИ 00:46 — План разбора темы LoRA 01:07 — Проблема гигантских ИИ 02:29 — Идея LoRA: низкий ранг 03:14 — Как работает метод LoRA 04:33 — Впечатляющие результаты LoRA 05:49 — Почему LoRA важна: практическое влияние Сайт: https://systems-analysis.ru Wiki: https://systems-analysis.ru/wiki X (Twitter): https://x.com/system_ru Telegram: https://t.me/systems_analysis_ru #LoRA #LowRankAdaptation #LLM #GPT3 #FineTuning #PEFT #ParameterEfficient #Transformer #NLP #ИскусственныйИнтеллект #МашинноеОбучение #Нейросети #Инференс #GPUMemory #MicrosoftResearch #arXiv
Comments