Python Web-scraping: Usando Selenium para recolectar textos y analizarlo con NLTK (principiantes) скачать в хорошем качестве
Python Web-scraping: Usando Selenium para recolectar textos y analizarlo con NLTK (principiantes)
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Python Web-scraping: Usando Selenium para recolectar textos y analizarlo con NLTK (principiantes) в качестве 4k
У нас вы можете посмотреть бесплатно Python Web-scraping: Usando Selenium para recolectar textos y analizarlo con NLTK (principiantes) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Python Web-scraping: Usando Selenium para recolectar textos y analizarlo con NLTK (principiantes) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Python Web-scraping: Usando Selenium para recolectar textos y analizarlo con NLTK (principiantes)
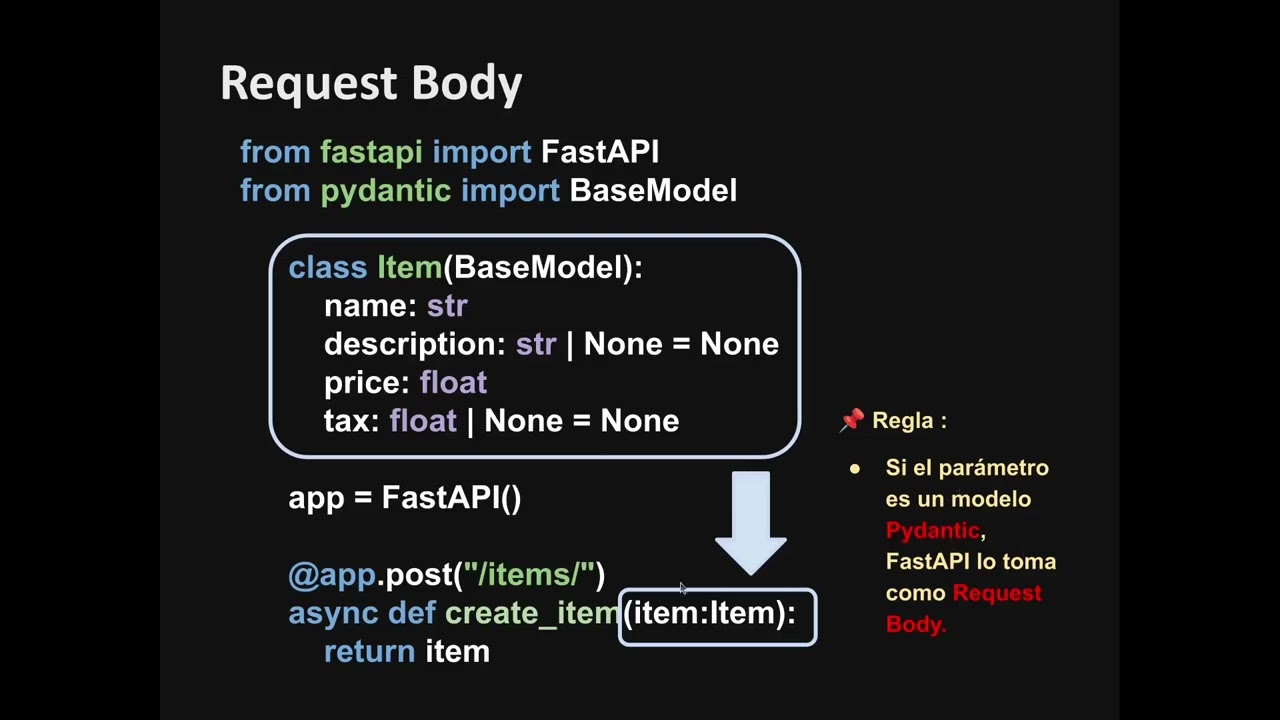
Generamos un proyecto real para extraer datos de necesidad de entidades de gobierno y mediante su texto comprender el tipo de adquisiciones que realizan bajo modalidad de ínfima cuantía (portal sercop Ecuador). Usando Python y Selenium generamos un bot que nos permite extraer los datos y usando NLTK hacemos un análisis exploratorio inicial de esos textos. Repositorio GitHub: https://github.com/bluesfer2007/selen... Notion Con Links que necesitamos: https://foil-skate-4fb.notion.site/Se... Mi Linkedin / fernando-j-pullutasig-acosta-b7463086 Contenido del video: 0:00 Por qué usar Selenium 3:05 Página a Scrapear 7:47 Iniciar configuración con Selenium 11:54 Árbol Proyecto con VSCODE 16:31 Iniciar con Super Clase 22:54 Ejecutar main primer test 24:42 Método get obtener URL 31:41 Lógica avanzar paginas 37:15 Iniciar métodos extraer datos 45:24 Crear clase Reporte 54:42 Método Pull extraer texto 59:10 Método guardar en disco 1:06:04 Test extraer y guarda 1:12:36 Iniciar instalando NLTK 1:14:58 Notebook trabajo 1:17:16 Unificar archivos descargados 1:22:11 Iniciar tratamiento de texto 1:23:58 Tokenizar texto con REGEX 1:28:13 Estadística básica de texto 1:31:05 Limpiar StopWords 1:36:20 Gráfico Freq palabras 1:38:05 Generar Bigrams Ngrams 1:43:06 Gráfico Nube de Palabras 1:48:10 No Olvides compartir suscríbete
Comments