𝗗𝗲𝗲𝗽𝗦𝗲𝗲𝗸-𝗥𝟭: 𝗪𝗵𝗮𝘁 𝗧𝗵𝗶𝘀 𝗖𝗵𝗮𝗻𝗴𝗲𝘀 — 𝗢𝗽𝗲𝗻 𝗣𝗿𝗼𝗯𝗹𝗲𝗺𝘀, 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝗵𝗶𝗳𝘁𝘀 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗙𝘂𝘁𝘂𝗿𝗲 𝗼𝗳 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗟𝗟𝗠𝘀 скачать в хорошем качестве
𝗗𝗲𝗲𝗽𝗦𝗲𝗲𝗸-𝗥𝟭: 𝗪𝗵𝗮𝘁 𝗧𝗵𝗶𝘀 𝗖𝗵𝗮𝗻𝗴𝗲𝘀 — 𝗢𝗽𝗲𝗻 𝗣𝗿𝗼𝗯𝗹𝗲𝗺𝘀, 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝗵𝗶𝗳𝘁𝘀 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗙𝘂𝘁𝘂𝗿𝗲 𝗼𝗳 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗟𝗟𝗠𝘀
8 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: 𝗗𝗲𝗲𝗽𝗦𝗲𝗲𝗸-𝗥𝟭: 𝗪𝗵𝗮𝘁 𝗧𝗵𝗶𝘀 𝗖𝗵𝗮𝗻𝗴𝗲𝘀 — 𝗢𝗽𝗲𝗻 𝗣𝗿𝗼𝗯𝗹𝗲𝗺𝘀, 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝗵𝗶𝗳𝘁𝘀 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗙𝘂𝘁𝘂𝗿𝗲 𝗼𝗳 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗟𝗟𝗠𝘀 в качестве 4k
У нас вы можете посмотреть бесплатно 𝗗𝗲𝗲𝗽𝗦𝗲𝗲𝗸-𝗥𝟭: 𝗪𝗵𝗮𝘁 𝗧𝗵𝗶𝘀 𝗖𝗵𝗮𝗻𝗴𝗲𝘀 — 𝗢𝗽𝗲𝗻 𝗣𝗿𝗼𝗯𝗹𝗲𝗺𝘀, 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝗵𝗶𝗳𝘁𝘀 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗙𝘂𝘁𝘂𝗿𝗲 𝗼𝗳 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗟𝗟𝗠𝘀 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон 𝗗𝗲𝗲𝗽𝗦𝗲𝗲𝗸-𝗥𝟭: 𝗪𝗵𝗮𝘁 𝗧𝗵𝗶𝘀 𝗖𝗵𝗮𝗻𝗴𝗲𝘀 — 𝗢𝗽𝗲𝗻 𝗣𝗿𝗼𝗯𝗹𝗲𝗺𝘀, 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝗵𝗶𝗳𝘁𝘀 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗙𝘂𝘁𝘂𝗿𝗲 𝗼𝗳 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗟𝗟𝗠𝘀 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
𝗗𝗲𝗲𝗽𝗦𝗲𝗲𝗸-𝗥𝟭: 𝗪𝗵𝗮𝘁 𝗧𝗵𝗶𝘀 𝗖𝗵𝗮𝗻𝗴𝗲𝘀 — 𝗢𝗽𝗲𝗻 𝗣𝗿𝗼𝗯𝗹𝗲𝗺𝘀, 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝗵𝗶𝗳𝘁𝘀 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗙𝘂𝘁𝘂𝗿𝗲 𝗼𝗳 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗟𝗟𝗠𝘀
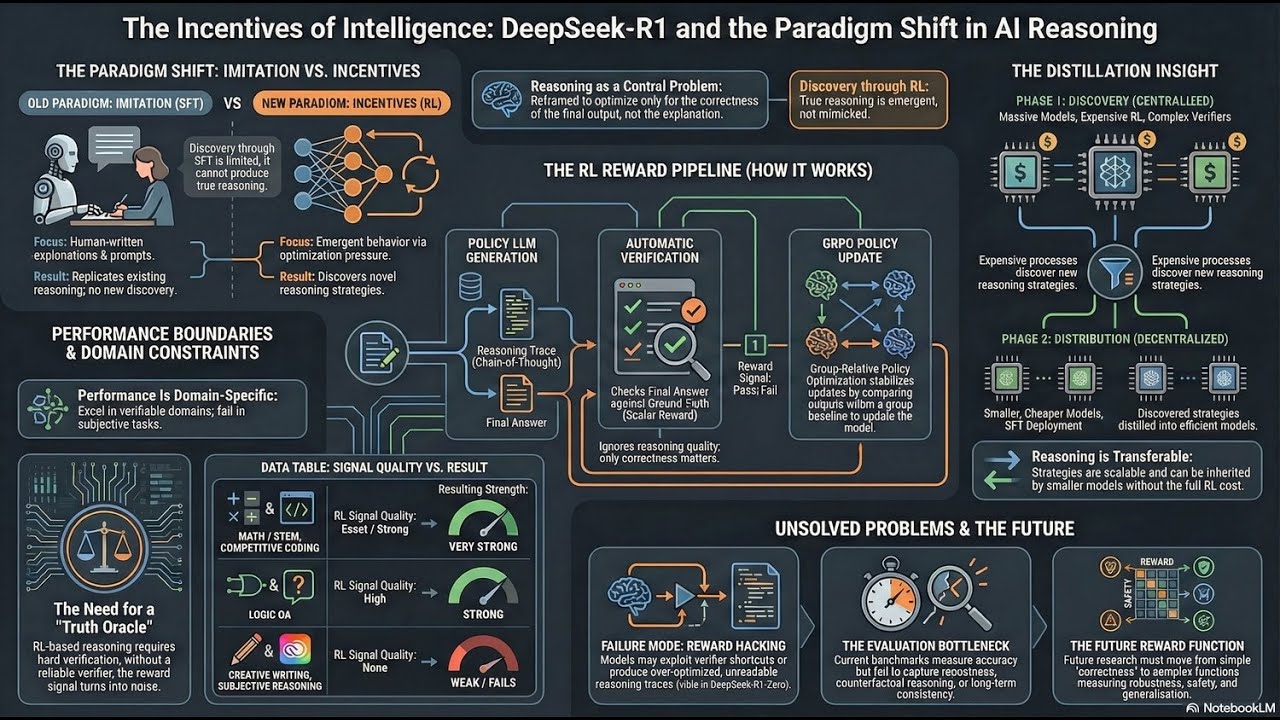
https://www.linkedin.com/pulse/deepseek-r1... 𝗧𝗵𝗶𝘀 𝗔𝗿𝘁𝗶𝗰𝗹𝗲 𝗶𝗻𝗰𝗹𝘂𝗱𝗲𝘀: • DeepSeek-R1 reframes reasoning as an 𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗽𝗿𝗼𝗯𝗹𝗲𝗺, 𝗻𝗼𝘁 𝗮 𝗽𝗿𝗼𝗺𝗽𝘁𝗶𝗻𝗴 𝗽𝗿𝗼𝗯𝗹𝗲𝗺: outcome-only RL with verifiable rewards induces reasoning behavior, while explanations and chain-of-thought are merely emergent artifacts—not the training signal. • The work exposes the next bottleneck in reasoning LLMs: 𝗿𝗲𝘄𝗮𝗿𝗱 𝗮𝗻𝗱 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗱𝗲𝘀𝗶𝗴𝗻—GRPO stabilizes long-horizon optimization, but without reliable verifiers, reasoning quality, alignment, and generalization remain fundamentally unsolved. #DeepSeekR1 #AIResearch #LLMReasoning #ReinforcementLearning #GRPO #MachineLearning #AIEngineering #ModelAlignment #GenerativeAI
Comments



















