Reinforcement Learning 6: Temporal-difference methods —Å–∫–∞—á–∞—Ç—å –≤ —Ö–æ—Ä–æ—à–µ–º –∫–∞—á–µ—Å—Ç–≤–µ
Reinforcement Learning 6: Temporal-difference methods
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
–ù–µ —É–¥–∞–µ—Ç—Å—è –∑–∞–≥—Ä—É–∑–∏—Ç—å Youtube-–ø–ª–µ–µ—Ä. –ü—Ä–æ–≤–µ—Ä—å—Ç–µ –±–ª–æ–∫–∏—Ä–æ–≤–∫—É Youtube –≤ –≤–∞—à–µ–π —Å–µ—Ç–∏.
–ü–æ–≤—Ç–æ—Ä—è–µ–º –ø–æ–ø—ã—Ç–∫—É...
–ü–æ–≤—Ç–æ—Ä—è–µ–º –ø–æ–ø—ã—Ç–∫—É...

–°–∫–∞—á–∞—Ç—å –≤–∏–¥–µ–æ —Å —é—Ç—É–± –ø–æ —Å—Å—ã–ª–∫–µ –∏–ª–∏ —Å–º–æ—Ç—Ä–µ—Ç—å –±–µ–∑ –±–ª–æ–∫–∏—Ä–æ–≤–æ–∫ –Ω–∞ —Å–∞–π—Ç–µ: Reinforcement Learning 6: Temporal-difference methods –≤ –∫–∞—á–µ—Å—Ç–≤–µ 4k
–£ –Ω–∞—Å –≤—ã –º–æ–∂–µ—Ç–µ –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å –±–µ—Å–ø–ª–∞—Ç–Ω–æ Reinforcement Learning 6: Temporal-difference methods –∏–ª–∏ —Å–∫–∞—á–∞—Ç—å –≤ –º–∞–∫—Å–∏–º–∞–ª—å–Ω–æ–º –¥–æ—Å—Ç—É–ø–Ω–æ–º –∫–∞—á–µ—Å—Ç–≤–µ, –≤–∏–¥–µ–æ –∫–æ—Ç–æ—Ä–æ–µ –±—ã–ª–æ –∑–∞–≥—Ä—É–∂–µ–Ω–æ –Ω–∞ —é—Ç—É–±. –î–ª—è –∑–∞–≥—Ä—É–∑–∫–∏ –≤—ã–±–µ—Ä–∏—Ç–µ –≤–∞—Ä–∏–∞–Ω—Ç –∏–∑ —Ñ–æ—Ä–º—ã –Ω–∏–∂–µ:
-
–ò–Ω—Ñ–æ—Ä–º–∞—Ü–∏—è –ø–æ –∑–∞–≥—Ä—É–∑–∫–µ:
–°–∫–∞—á–∞—Ç—å mp3 —Å —é—Ç—É–±–∞ –æ—Ç–¥–µ–ª—å–Ω—ã–º —Ñ–∞–π–ª–æ–º. –ë–µ—Å–ø–ª–∞—Ç–Ω—ã–π —Ä–∏–Ω–≥—Ç–æ–Ω Reinforcement Learning 6: Temporal-difference methods –≤ —Ñ–æ—Ä–º–∞—Ç–µ MP3:
–ï—Å–ª–∏ –∫–Ω–æ–ø–∫–∏ —Å–∫–∞—á–∏–≤–∞–Ω–∏—è –Ω–µ
–∑–∞–≥—Ä—É–∑–∏–ª–∏—Å—å
–ù–ê–ñ–ú–ò–¢–ï –ó–î–ï–°–¨ –∏–ª–∏ –æ–±–Ω–æ–≤–∏—Ç–µ —Å—Ç—Ä–∞–Ω–∏—Ü—É
–ï—Å–ª–∏ –≤–æ–∑–Ω–∏–∫–∞—é—Ç –ø—Ä–æ–±–ª–µ–º—ã —Å–æ —Å–∫–∞—á–∏–≤–∞–Ω–∏–µ–º –≤–∏–¥–µ–æ, –ø–æ–∂–∞–ª—É–π—Å—Ç–∞ –Ω–∞–ø–∏—à–∏—Ç–µ –≤ –ø–æ–¥–¥–µ—Ä–∂–∫—É –ø–æ –∞–¥—Ä–µ—Å—É –≤–Ω–∏–∑—É
—Å—Ç—Ä–∞–Ω–∏—Ü—ã.
–°–ø–∞—Å–∏–±–æ –∑–∞ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ —Å–µ—Ä–≤–∏—Å–∞ ClipSaver.ru
Reinforcement Learning 6: Temporal-difference methods
Slides: https://cwkx.github.io/data/teaching/... Colab: https://colab.research.google.com/gis... Twitter: ¬Ý¬Ý/¬Ýcwkx¬Ý¬Ý Next video: ¬Ý¬Ý¬Ý‚Ä¢¬ÝReinforcement¬ÝLearning¬ÝLectures¬Ý¬Ý Temporal-difference learning dopamine and reward predictor error definition behaviour example SARSA (on-policy TD control) Off-policy learning Q-learning (off-policy TD control) TD lambda #reinforcementlearning #dopamine #RPE #SARSA #Qlearning #TDlambda #TDlearning #offpolicy
Comments
-
 4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-

-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 7 –ª–µ—Ç –Ω–∞–∑–∞–¥
7 –ª–µ—Ç –Ω–∞–∑–∞–¥
-
 8 –ª–µ—Ç –Ω–∞–∑–∞–¥
8 –ª–µ—Ç –Ω–∞–∑–∞–¥
-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
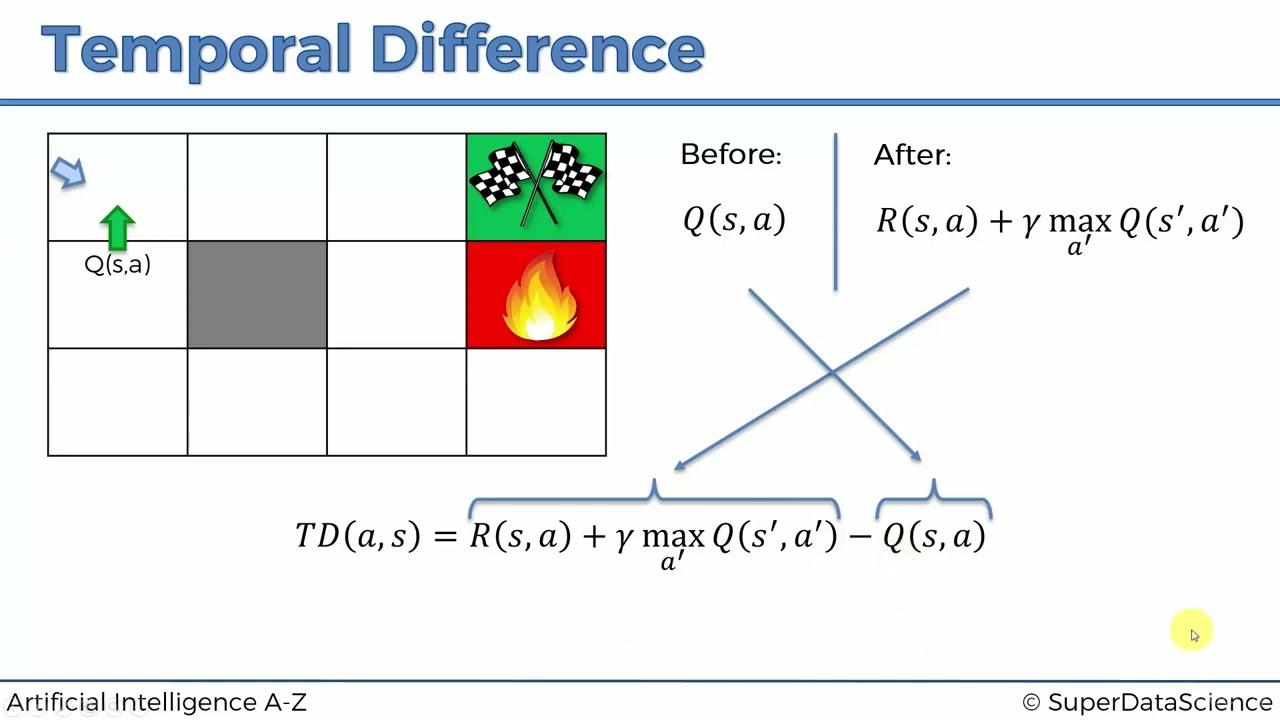 3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
2 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-

-
 6 лет назад
6 –ª–µ—Ç –Ω–∞–∑–∞–¥
-
 4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 2 недели назад
2 –Ω–µ–¥–µ–ª–∏ –Ω–∞–∑–∞–¥
-
 4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
4 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
-
 3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥
3 –≥–æ–¥–∞ –Ω–∞–∑–∞–¥