Скачать с ютуб Data Con LA 2022 - Building a serverless data processing pipeline with PySpark on cloud в хорошем качестве
Data Con LA 2022 - Building a serverless data processing pipeline with PySpark on cloud
2 года назад
Скачать бесплатно и смотреть ютуб-видео без блокировок Data Con LA 2022 - Building a serverless data processing pipeline with PySpark on cloud в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно Data Con LA 2022 - Building a serverless data processing pipeline with PySpark on cloud или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон Data Con LA 2022 - Building a serverless data processing pipeline with PySpark on cloud в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Data Con LA 2022 - Building a serverless data processing pipeline with PySpark on cloud
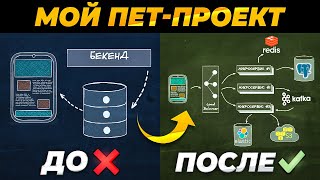
Suman Debnath, Principal Developer Advocate(Data Engineering), Amazon Web Services Data is all over the place, and what matters is how we manage that data and make sense out of it and take some meaningful data driven decision. In this session we will discuss about whole data engineering pipeline, starting from data collection, processing, analysis and visualization in a complete serverless fashion. We will pick some opensource dataset and shall store and process it on cloud(AWS). While the focus would be more on the general understanding of data pipeline aspects of data engineering, but during the process we will learn few of the AWS services which can help us to achieve our goal in an effective and efficient way.
Comments