MPI Meets Machine Learning: Unlocking PyTorch distributed for scaling AI workloads - DevConf.IN 2026 скачать в хорошем качестве
MPI Meets Machine Learning: Unlocking PyTorch distributed for scaling AI workloads - DevConf.IN 2026
3 дня назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: MPI Meets Machine Learning: Unlocking PyTorch distributed for scaling AI workloads - DevConf.IN 2026 в качестве 4k
У нас вы можете посмотреть бесплатно MPI Meets Machine Learning: Unlocking PyTorch distributed for scaling AI workloads - DevConf.IN 2026 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон MPI Meets Machine Learning: Unlocking PyTorch distributed for scaling AI workloads - DevConf.IN 2026 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
MPI Meets Machine Learning: Unlocking PyTorch distributed for scaling AI workloads - DevConf.IN 2026
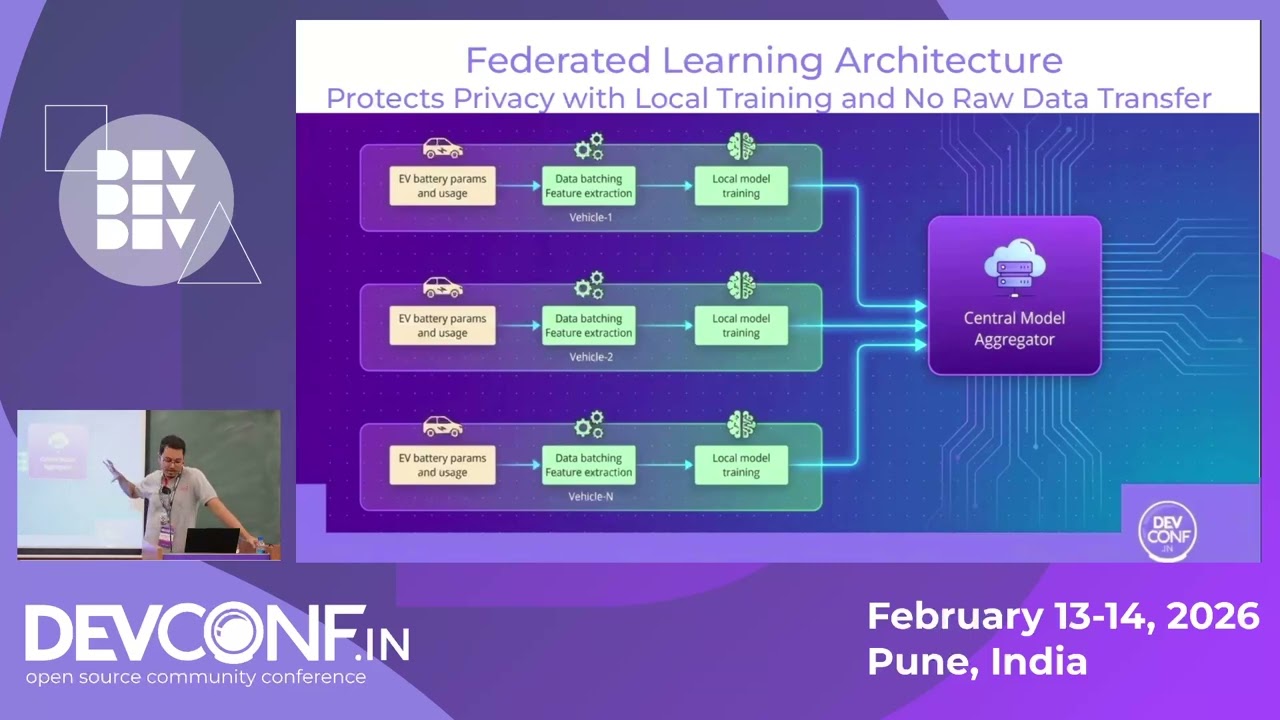
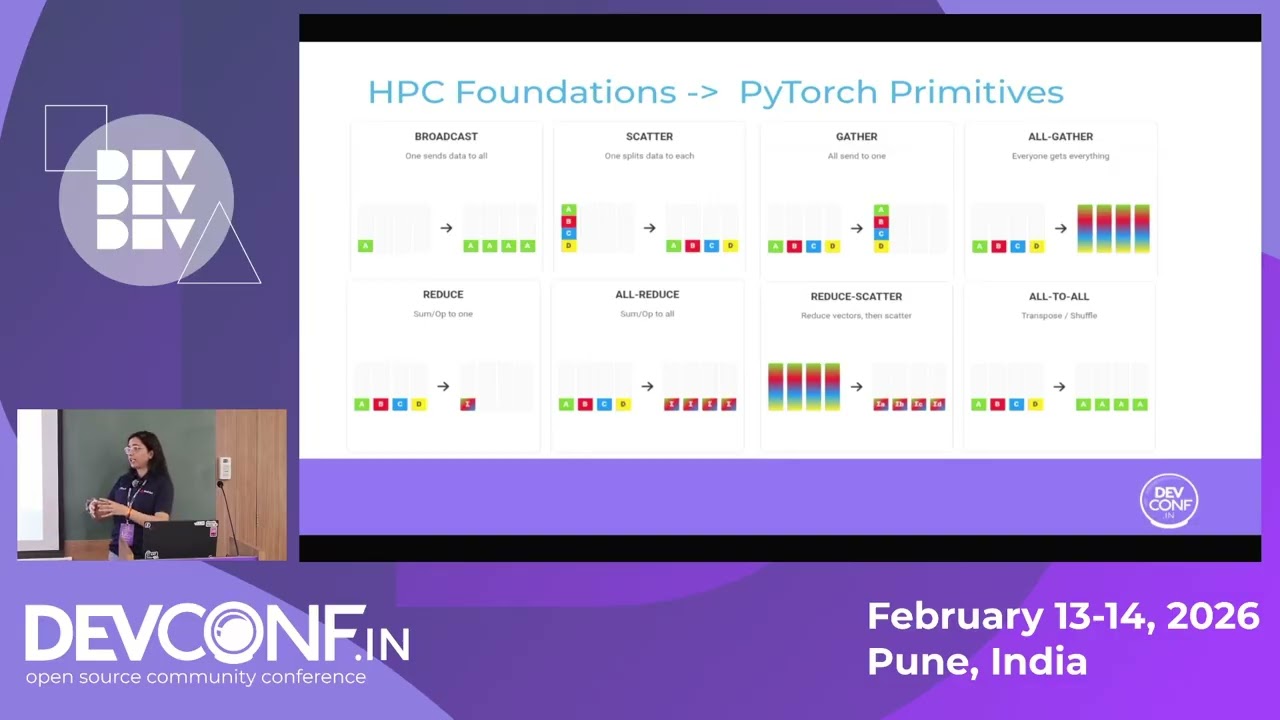
Title: MPI Meets Machine Learning: Unlocking PyTorch distributed for scaling AI workloads Speaker(s): Mansi Agarwal --- The world of High-Performance Computing (HPC) and modern deep learning share a core DNA: the demand for near-linear scaling across hundreds of nodes. The core challenges remain the same—managing communication, balancing load, and coordinating resources but the abstractions and tooling are now defined by PyTorch Distributed. This talk bridges the gap between traditional HPC paradigms and PyTorch's distributed computing ecosystem, designed specifically for deep learning workloads. We'll explore how familiar HPC concepts like collective operations, point-to-point communication, and process groups, manifest in PyTorch's distributed APIs. We'll discover how PyTorch builds upon battle-tested communication backends (NCCL, Gloo, MPI) while introducing novel primitives optimized for gradient synchronization and model parallelism. We then move beyond basic data parallelism to explore advanced memory-saving techniques like Fully Sharded Data Parallel (FSDP), PyTorch's native answer to memory scaling and touch upon the nascent Tensor and Pipeline Parallelism APIs, demonstrating how these techniques compose to train massive models. This session equips you with a comprehensive understanding of PyTorch's distributed architecture and reveals the inner workings of one of the most actively developed areas in modern ML infrastructure. By mapping distributed systems concepts to PyTorch's implementation, you'll see how familiar patterns from parallel computing manifest in PyTorch's ecosystem and where there is still room for innovation and improvement. --- Full schedule, including slides and other resources: https://pretalx.devconf.info/devconf-...
Comments