Вопрос для собеседования JLL Pyspark: узнайте о трёх лучших местах выдачи заказов скачать в хорошем качестве
Вопрос для собеседования JLL Pyspark: узнайте о трёх лучших местах выдачи заказов
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Вопрос для собеседования JLL Pyspark: узнайте о трёх лучших местах выдачи заказов в качестве 4k
У нас вы можете посмотреть бесплатно Вопрос для собеседования JLL Pyspark: узнайте о трёх лучших местах выдачи заказов или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Вопрос для собеседования JLL Pyspark: узнайте о трёх лучших местах выдачи заказов в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Вопрос для собеседования JLL Pyspark: узнайте о трёх лучших местах выдачи заказов
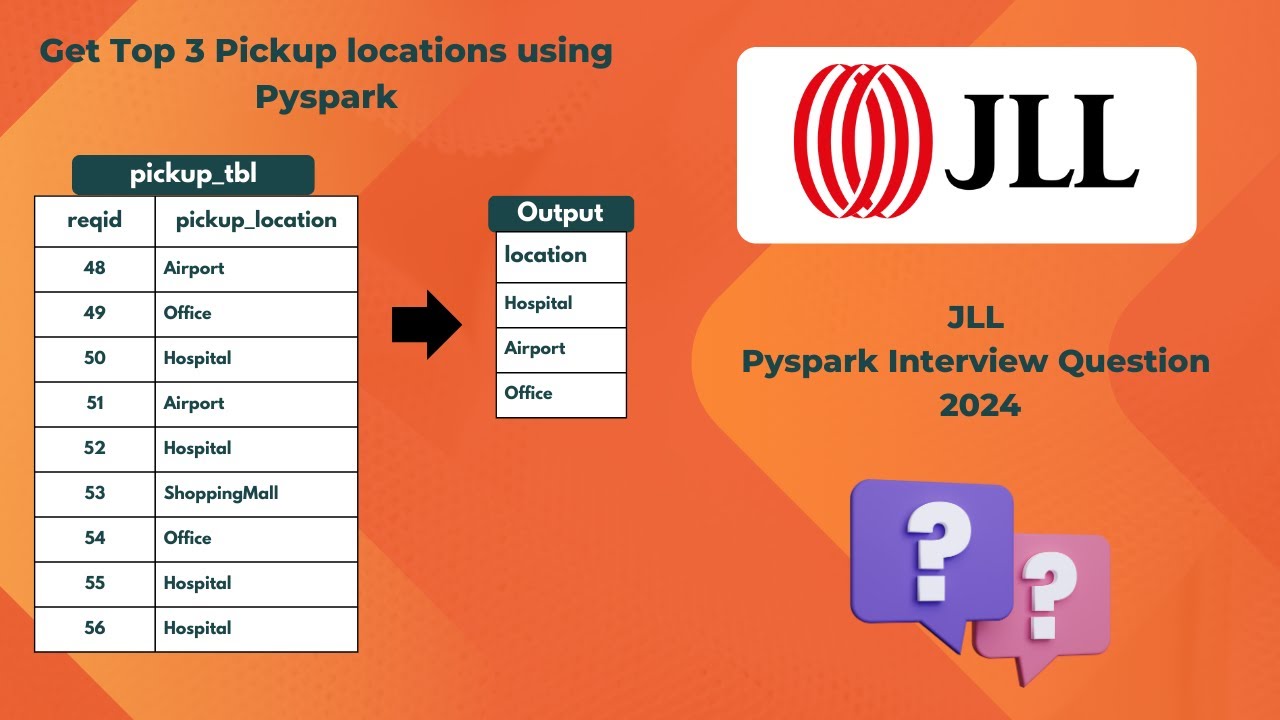
Один из вопросов, недавно заданных на собеседовании в Pyspark на собеседовании JLL: Нам нужно получить топ-3 пунктов самовывоза. Давайте посмотрим, как этого добиться, используя GroupBy по количеству и лимиту. Упоминание деталей фрейма данных здесь from pyspark.sql.types import StructType, StructField, StringType, IntegerType Определить схему schema = StructType([ StructField("reqid", IntegerType(), True), StructField("pickup_location", StringType(), True) ]) Создать фрейм данных с заданной схемой data = [(48, "Airport"), (49, "Office"),(50, "Hospital"),(51, "Airport"),(52, "Hospital"),(53, "Shoppingmall"),(54, "Office"),(55, "Hospital"),(56, "Hospital")] pickup_df = spark.createDataFrame(data, schema) pickup_df.display() Ещё больше вопросов для собеседования по Azure Data Bricks можно найти в нашем плейлисте. • DataBricks and PySpark Interview Questions Свяжитесь с нами: info@cloudchallengers.com Подпишитесь на нас в Instagram: instagram.com/cloudchallengers Facebook: facebook.com/cloudchallengers LinkedIn: linkedin.com/company/cloudchallengers
Comments










![Почему работает теория шести рукопожатий? [Veritasium]](https://imager.clipsaver.ru/ggI1xKzoANs/max.jpg)








