Accessing vLLM on HPC Alvis Through Tunneling | Supervision | Dr. Emre Süren скачать в хорошем качестве
Accessing vLLM on HPC Alvis Through Tunneling | Supervision | Dr. Emre Süren
7 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Accessing vLLM on HPC Alvis Through Tunneling | Supervision | Dr. Emre Süren в качестве 4k
У нас вы можете посмотреть бесплатно Accessing vLLM on HPC Alvis Through Tunneling | Supervision | Dr. Emre Süren или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Accessing vLLM on HPC Alvis Through Tunneling | Supervision | Dr. Emre Süren в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Accessing vLLM on HPC Alvis Through Tunneling | Supervision | Dr. Emre Süren
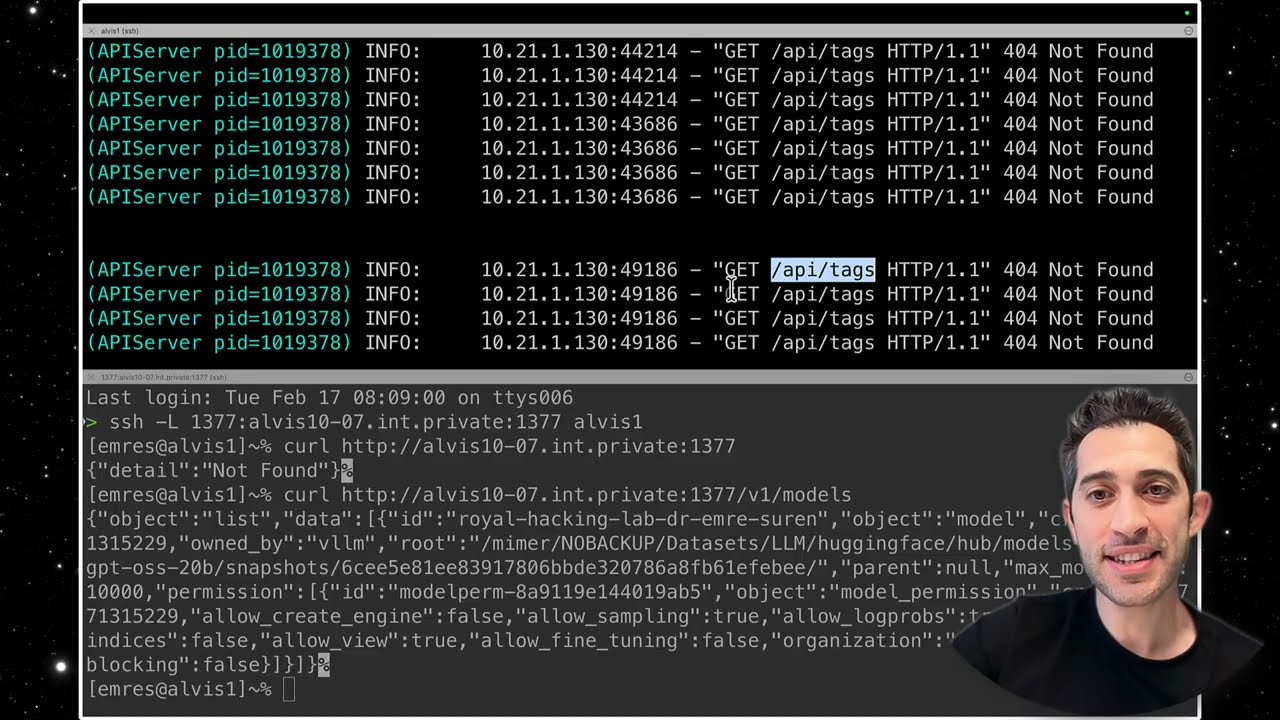
In this session, Dr. Emre Süren demonstrates how to bridge the gap between your local workstation and high-performance computing (HPC) resources. You will learn how to access a Large Language Model (LLM) running on a GPU node behind a private network on the *Alvis cluster**. The lab covers the essentials of SSH configuration, public-key authentication, and the use of **SSH Tunneling (Port Forwarding)* to expose remote VLLM services as local endpoints. Furthermore, the video explores using *LiteLLM* as a proxy to standardize API requests (like Ollama or OpenAI formats) for seamless integration with desktop client applications. --- *You will learn in this lab:* *SSH Optimization:* How to create a `.ssh/config` file to use aliases and maintain "heartbeat" connections to prevent timeouts. *Key-Based Authentication:* Generating RSA keys and using `ssh-copy-id` to enable passwordless login. *HPC Environment Setup:* Loading modules and creating isolated Python virtual environments on Alvis. *LLM Deployment:* Running an LLM inference server using `sbatch` and Slurm scripts. *SSH Local Port Forwarding:* Using the `-L` flag to map a remote private IP/port to your `localhost`. *API Interoperability:* Utilizing *LiteLLM* as a proxy to translate requests between different LLM API conventions (VLLM, Ollama, and OpenAI). --- *Homework Challenge* 1. *Configure your SSH Alias:* Set up a config file so that you can connect to your remote server by simply typing `ssh alvis1`. 2. *Establish a Tunnel:* Start a dummy web service (or an LLM) on a remote node, then use SSH Tunneling to view that service in your local Chrome or Firefox browser. 3. *Proxy Setup:* Install `litellm` in a virtual environment and attempt to map a non-standard model endpoint to a standard OpenAI-compatible `/v1/chat/completions` endpoint. 4. *Troubleshooting:* Identify why the MCP client in the video failed to recognize the `/api/tags` endpoint and propose a configuration fix in the `litellm_conf.yaml`. --- *Timestamps* *00:00* – Introduction: Accessing internal HPC resources from home. *01:15* – Setting up SSH Config and aliases for Alvis1. *02:30* – Public/Private key authentication and authorized_keys. *04:50* – Generating keys with `ssh-keygen` and using `ssh-copy-id`. *07:15* – Best practices for SSH directory permissions (700 and 600). *07:54* – Creating a Python Virtual Environment on the HPC. *10:28* – Submitting the LLM job via Slurm (`sbatch`). *11:33* – The need for a Proxy: VLLM vs. Ollama standards. *13:10* – *Deep Dive:* Executing the SSH Tunneling command (`ssh -L`). *14:24* – Verifying the connection via browser and `curl`. *15:10* – Connecting an MCP Desktop Assistant to the tunneled model. *17:10* – Configuring LiteLLM to act as an OpenAI-compatible gateway. *18:50* – Debugging endpoint errors and final thoughts. --- #PromptInjection #Jailbreaking #LLMSecurity #Spikee #RedTeaming #OffensiveSecurity #CyberSecurity #DrEmreSüren #GenerativeAI #AIHacking #VibeHacking #HPC #Alvis #SSHTunneling #VLLM #LiteLLM #CloudComputing #Supervison
Comments