Learning to summarize from human feedback (Paper Explained) скачать в хорошем качестве
Learning to summarize from human feedback (Paper Explained)
5 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Learning to summarize from human feedback (Paper Explained) в качестве 4k
У нас вы можете посмотреть бесплатно Learning to summarize from human feedback (Paper Explained) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Learning to summarize from human feedback (Paper Explained) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Learning to summarize from human feedback (Paper Explained)
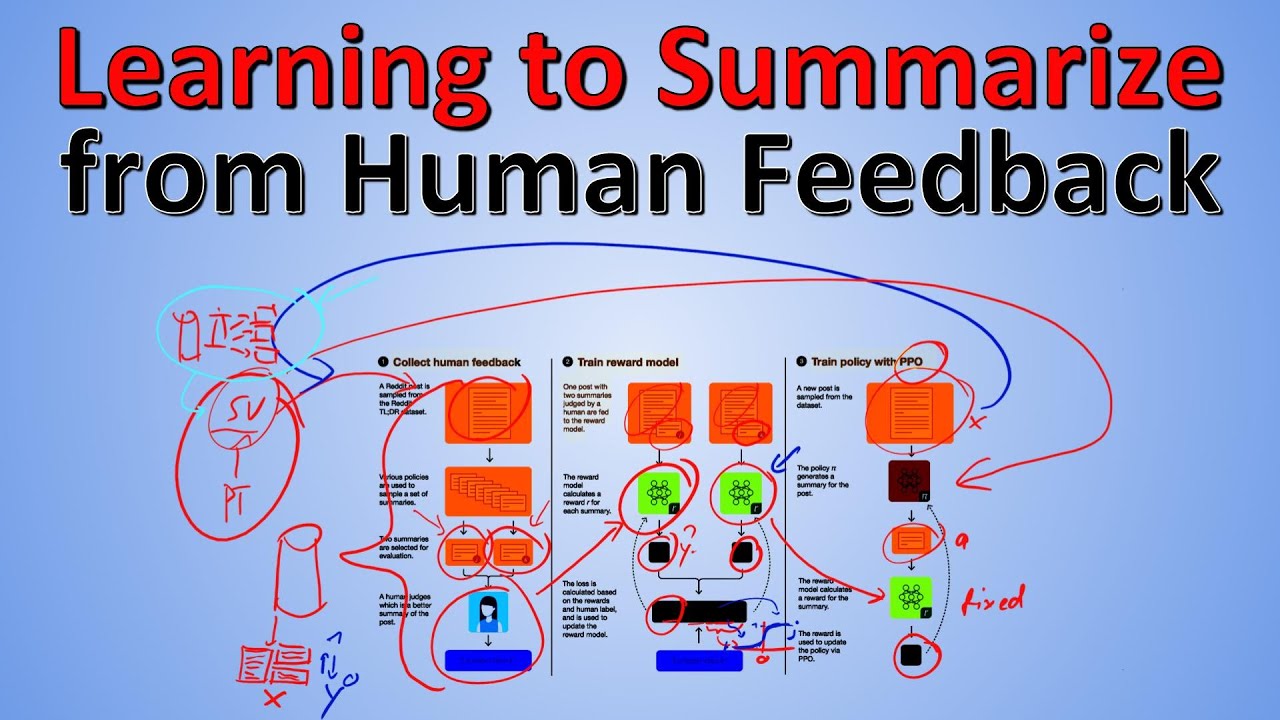
#summarization #gpt3 #openai Text Summarization is a hard task, both in training and evaluation. Training is usually done maximizing the log-likelihood of a human-generated reference summary, while evaluation is performed using overlap-based metrics like ROUGE. Both significantly undervalue the breadth and intricacies of language and the nature of the information contained in text summaries. This paper by OpenAI includes direct human feedback both in evaluation and - via reward model proxies - in training. The final model even outperforms single humans when judged by other humans and is an interesting application of using reinforcement learning together with humans in the loop. OUTLINE: 0:00 - Intro & Overview 5:35 - Summarization as a Task 7:30 - Problems with the ROUGE Metric 10:10 - Training Supervised Models 12:30 - Main Results 16:40 - Including Human Feedback with Reward Models & RL 26:05 - The Unknown Effect of Better Data 28:30 - KL Constraint & Connection to Adversarial Examples 37:15 - More Results 39:30 - Understanding the Reward Model 41:50 - Limitations & Broader Impact Paper: https://arxiv.org/abs/2009.01325 Blog: https://openai.com/blog/learning-to-s... Code: https://github.com/openai/summarize-f... Samples: https://openaipublic.blob.core.window... My Video on GPT-3: • GPT-3: Language Models are Few-Shot Learne... My Video on GPT-2: • GPT-2: Language Models are Unsupervised Mu... Abstract: As language models become more powerful, training and evaluation are increasingly bottlenecked by the data and metrics used for a particular task. For example, summarization models are often trained to predict human reference summaries and evaluated using ROUGE, but both of these metrics are rough proxies for what we really care about---summary quality. In this work, we show that it is possible to significantly improve summary quality by training a model to optimize for human preferences. We collect a large, high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary, and use that model as a reward function to fine-tune a summarization policy using reinforcement learning. We apply our method to a version of the TL;DR dataset of Reddit posts and find that our models significantly outperform both human reference summaries and much larger models fine-tuned with supervised learning alone. Our models also transfer to CNN/DM news articles, producing summaries nearly as good as the human reference without any news-specific fine-tuning. We conduct extensive analyses to understand our human feedback dataset and fine-tuned models. We establish that our reward model generalizes to new datasets, and that optimizing our reward model results in better summaries than optimizing ROUGE according to humans. We hope the evidence from our paper motivates machine learning researchers to pay closer attention to how their training loss affects the model behavior they actually want. Authors: Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano Links: YouTube: / yannickilcher Twitter: / ykilcher Discord: / discord BitChute: https://www.bitchute.com/channel/yann... Minds: https://www.minds.com/ykilcher Parler: https://parler.com/profile/YannicKilcher LinkedIn: / yannic-kilcher-488534136 If you want to support me, the best thing to do is to share out the content :) If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this): SubscribeStar: https://www.subscribestar.com/yannick... Patreon: / yannickilcher Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2 Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Comments