–Ъ–Њ–љ—В–µ–Ї—Б—В–љ–Њ–µ –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ: –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞ —Б–Ї–∞—З–∞—В—М –≤ —Е–Њ—А–Њ—И–µ–Љ –Ї–∞—З–µ—Б—В–≤–µ
–Ъ–Њ–љ—В–µ–Ї—Б—В–љ–Њ–µ –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ: –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
–Э–µ —Г–і–∞–µ—В—Б—П –Ј–∞–≥—А—Г–Ј–Є—В—М Youtube-–њ–ї–µ–µ—А. –Я—А–Њ–≤–µ—А—М—В–µ –±–ї–Њ–Ї–Є—А–Њ–≤–Ї—Г Youtube –≤ –≤–∞—И–µ–є —Б–µ—В–Є.
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...
–°–Ї–∞—З–∞—В—М –≤–Є–і–µ–Њ —Б —О—В—Г–± –њ–Њ —Б—Б—Л–ї–Ї–µ –Є–ї–Є —Б–Љ–Њ—В—А–µ—В—М –±–µ–Ј –±–ї–Њ–Ї–Є—А–Њ–≤–Њ–Ї –љ–∞ —Б–∞–є—В–µ: –Ъ–Њ–љ—В–µ–Ї—Б—В–љ–Њ–µ –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ: –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞ –≤ –Ї–∞—З–µ—Б—В–≤–µ 4k
–£ –љ–∞—Б –≤—Л –Љ–Њ–ґ–µ—В–µ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –±–µ—Б–њ–ї–∞—В–љ–Њ –Ъ–Њ–љ—В–µ–Ї—Б—В–љ–Њ–µ –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ: –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞ –Є–ї–Є —Б–Ї–∞—З–∞—В—М –≤ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–Љ –і–Њ—Б—В—Г–њ–љ–Њ–Љ –Ї–∞—З–µ—Б—В–≤–µ, –≤–Є–і–µ–Њ –Ї–Њ—В–Њ—А–Њ–µ –±—Л–ї–Њ –Ј–∞–≥—А—Г–ґ–µ–љ–Њ –љ–∞ —О—В—Г–±. –Ф–ї—П –Ј–∞–≥—А—Г–Ј–Ї–Є –≤—Л–±–µ—А–Є—В–µ –≤–∞—А–Є–∞–љ—В –Є–Ј —Д–Њ—А–Љ—Л –љ–Є–ґ–µ:
-
–Ш–љ—Д–Њ—А–Љ–∞—Ж–Є—П –њ–Њ –Ј–∞–≥—А—Г–Ј–Ї–µ:
–°–Ї–∞—З–∞—В—М mp3 —Б —О—В—Г–±–∞ –Њ—В–і–µ–ї—М–љ—Л–Љ —Д–∞–є–ї–Њ–Љ. –С–µ—Б–њ–ї–∞—В–љ—Л–є —А–Є–љ–≥—В–Њ–љ –Ъ–Њ–љ—В–µ–Ї—Б—В–љ–Њ–µ –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ: –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞ –≤ —Д–Њ—А–Љ–∞—В–µ MP3:
–Х—Б–ї–Є –Ї–љ–Њ–њ–Ї–Є —Б–Ї–∞—З–Є–≤–∞–љ–Є—П –љ–µ
–Ј–∞–≥—А—Г–Ј–Є–ї–Є—Б—М
–Э–Р–Ц–Ь–Ш–Ґ–Х –Ч–Ф–Х–°–ђ –Є–ї–Є –Њ–±–љ–Њ–≤–Є—В–µ —Б—В—А–∞–љ–Є—Ж—Г
–Х—Б–ї–Є –≤–Њ–Ј–љ–Є–Ї–∞—О—В –њ—А–Њ–±–ї–µ–Љ—Л —Б–Њ —Б–Ї–∞—З–Є–≤–∞–љ–Є–µ–Љ –≤–Є–і–µ–Њ, –њ–Њ–ґ–∞–ї—Г–є—Б—В–∞ –љ–∞–њ–Є—И–Є—В–µ –≤ –њ–Њ–і–і–µ—А–ґ–Ї—Г –њ–Њ –∞–і—А–µ—Б—Г –≤–љ–Є–Ј—Г
—Б—В—А–∞–љ–Є—Ж—Л.
–°–њ–∞—Б–Є–±–Њ –Ј–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —Б–µ—А–≤–Є—Б–∞ ClipSaver.ru
–Ъ–Њ–љ—В–µ–Ї—Б—В–љ–Њ–µ –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ: –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞
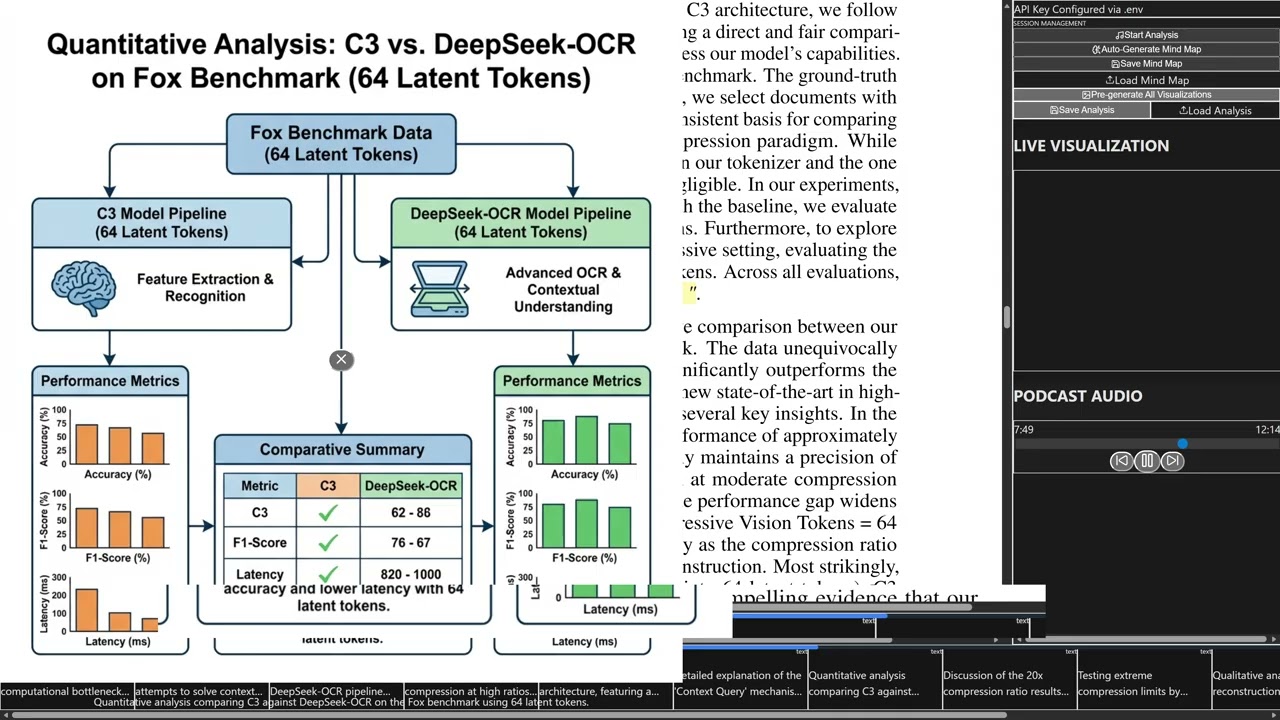
–Ъ–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ –Ї–Њ–љ—В–µ–Ї—Б—В–∞: –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞ –§–∞–љ—М—Д–∞–љ—М –Ы—О, –•–∞–є–±–Њ –¶—О –Т—Е–Њ–і–љ—Л–µ –і–∞–љ–љ—Л–µ –і–ї–Є–љ–Њ–є –≤ –Љ–Є–ї–ї–Є–Њ–љ —В–Њ–Ї–µ–љ–Њ–≤ –≤ –Ј–∞–і–∞—З–∞—Е —Б –і–ї–Є–љ–љ—Л–Љ –Ї–Њ–љ—В–µ–Ї—Б—В–Њ–Љ —Б–Њ–Ј–і–∞—О—В –Ј–љ–∞—З–Є—В–µ–ї—М–љ—Л–µ –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л–µ –Є —А–µ—Б—Г—А—Б–Њ—С–Љ–Ї–Є–µ –Ј–∞–і–∞—З–Є –і–ї—П –±–Њ–ї—М—И–Є—Е —П–Ј—Л–Ї–Њ–≤—Л—Е –Љ–Њ–і–µ–ї–µ–є (LLM). –Э–µ–і–∞–≤–љ–Њ –Ї–Њ–Љ–њ–∞–љ–Є—П DeepSeek-OCR –њ—А–Њ–≤–µ–ї–∞ –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є –Њ–њ—В–Є—З–µ—Б–Ї–Њ–≥–Њ —Б–ґ–∞—В–Є—П –Ї–Њ–љ—В–µ–Ї—Б—В–∞ –Є –њ–Њ–ї—Г—З–Є–ї–∞ –њ—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ—Л–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л. –Т–і–Њ—Е–љ–Њ–≤–ї—С–љ–љ—Л–µ —Н—В–Є–Љ –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ–Љ, –Љ—Л –њ—А–µ–і—Б—В–∞–≤–ї—П–µ–Љ –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ –Ї–Њ–љ—В–µ–Ї—Б—В–∞ C3 –і–ї—П –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є—П –≤–µ—А—Е–љ–Є—Е –њ—А–µ–і–µ–ї–Њ–≤ —Б–ґ–∞—В–Є—П —В–µ–Ї—Б—В–∞. –Э–∞—И –Љ–µ—В–Њ–і –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –Ї–∞—Б–Ї–∞–і–љ–Њ–µ —Б–ґ–∞—В–Є–µ –Ї–Њ–љ—В–µ–Ї—Б—В–∞ –і–≤—Г—Е LLM —А–∞–Ј–љ–Њ–≥–Њ —А–∞–Ј–Љ–µ—А–∞ –і–ї—П –≤—Л–њ–Њ–ї–љ–µ–љ–Є—П –Ј–∞–і–∞—З —Б–ґ–∞—В–Є—П –Є –і–µ–Ї–Њ–і–Є—А–Њ–≤–∞–љ–Є—П. –Т —З–∞—Б—В–љ–Њ—Б—В–Є, –Љ–∞–ї—Л–є LLM, –≤—Л—Б—В—Г–њ–∞—О—Й–Є–є –≤ –Ї–∞—З–µ—Б—В–≤–µ –њ–µ—А–≤–Њ–≥–Њ —Н—В–∞–њ–∞, –≤—Л–њ–Њ–ї–љ—П–µ—В —Б–ґ–∞—В–Є–µ —В–µ–Ї—Б—В–∞, —Б–ґ–Є–Љ–∞—П –і–ї–Є–љ–љ—Л–є –Ї–Њ–љ—В–µ–Ї—Б—В –≤ –љ–∞–±–Њ—А —Б–Ї—А—Л—В—Л—Е —В–Њ–Ї–µ–љ–Њ–≤ (–љ–∞–њ—А–Є–Љ–µ—А, –і–ї–Є–љ–Њ–є 32 –Є–ї–Є 64), –і–Њ—Б—В–Є–≥–∞—П –≤—Л—Б–Њ–Ї–Њ–≥–Њ —Б–Њ–Њ—В–љ–Њ—И–µ–љ–Є—П –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ —В–µ–Ї—Б—В–Њ–≤—Л—Е —В–Њ–Ї–µ–љ–Њ–≤ –Ї –Ї–Њ–ї–Є—З–µ—Б—В–≤—Г —Б–Ї—А—Л—В—Л—Е —В–Њ–Ї–µ–љ–Њ–≤. –С–Њ–ї—М—И–Њ–є LLM, –≤—Л—Б—В—Г–њ–∞—О—Й–Є–є –≤ –Ї–∞—З–µ—Б—В–≤–µ –≤—В–Њ—А–Њ–≥–Њ —Н—В–∞–њ–∞, –Ј–∞—В–µ–Љ –≤—Л–њ–Њ–ї–љ—П–µ—В –Ј–∞–і–∞—З—Г –і–µ–Ї–Њ–і–Є—А–Њ–≤–∞–љ–Є—П —Н—В–Њ–≥–Њ —Б–ґ–∞—В–Њ–≥–Њ –Ї–Њ–љ—В–µ–Ї—Б—В–∞. –≠–Ї—Б–њ–µ—А–Є–Љ–µ–љ—В—Л –њ–Њ–Ї–∞–Ј—Л–≤–∞—О—В, —З—В–Њ –њ—А–Є 20-–Ї—А–∞—В–љ–Њ–Љ —Б–ґ–∞—В–Є–Є (–Ї–Њ–≥–і–∞ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —В–µ–Ї—Б—В–Њ–≤—Л—Е —В–Њ–Ї–µ–љ–Њ–≤ –≤ 20 —А–∞–Ј –њ—А–µ–≤—Л—И–∞–µ—В –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Б–Ї—А—Л—В—Л—Е —В–Њ–Ї–µ–љ–Њ–≤) –љ–∞—И–∞ –Љ–Њ–і–µ–ї—М –і–Њ—Б—В–Є–≥–∞–µ—В —В–Њ—З–љ–Њ—Б—В–Є –і–µ–Ї–Њ–і–Є—А–Њ–≤–∞–љ–Є—П 98% –њ–Њ —Б—А–∞–≤–љ–µ–љ–Є—О —Б –њ—А–Є–Љ–µ—А–љ–Њ 60% –і–ї—П DeepSeek-OCR. –Я—А–Є –і–∞–ї—М–љ–µ–є—И–µ–Љ —Г–≤–µ–ї–Є—З–µ–љ–Є–Є —Б—В–µ–њ–µ–љ–Є —Б–ґ–∞—В–Є—П –і–Њ 40x —В–Њ—З–љ–Њ—Б—В—М —Б–Њ—Е—А–∞–љ—П–µ—В—Б—П –љ–∞ —Г—А–Њ–≤–љ–µ –Њ–Ї–Њ–ї–Њ 93%. –≠—В–Њ —Г–Ї–∞–Ј—Л–≤–∞–µ—В –љ–∞ —В–Њ, —З—В–Њ –≤ –Њ–±–ї–∞—Б—В–Є –Ї–Њ–љ—В–µ–Ї—Б—В–љ–Њ–≥–Њ —Б–ґ–∞—В–Є—П —Б–ґ–∞—В–Є–µ C3 –і–µ–Љ–Њ–љ—Б—В—А–Є—А—Г–µ—В –њ—А–µ–≤–Њ—Б—Е–Њ–і–љ—Г—О –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М –Є –њ—А–∞–Ї—В–Є—З–µ—Б–Ї—Г—О –њ—А–Є–Љ–µ–љ–Є–Љ–Њ—Б—В—М –њ–Њ —Б—А–∞–≤–љ–µ–љ–Є—О —Б –Њ–њ—В–Є—З–µ—Б–Ї–Є–Љ —Б–ґ–∞—В–Є–µ–Љ —Б–Є–Љ–≤–Њ–ї–Њ–≤. C3 –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –±–Њ–ї–µ–µ –њ—А–Њ—Б—В–Њ–є –Ї–Њ–љ–≤–µ–є–µ—А –Њ–±—А–∞–±–Њ—В–Ї–Є —З–Є—Б—В–Њ–≥–Њ —В–µ–Ї—Б—В–∞, –Ї–Њ—В–Њ—А—Л–є –Є–≥–љ–Њ—А–Є—А—Г–µ—В —В–∞–Ї–Є–µ —Д–∞–Ї—В–Њ—А—Л, –Ї–∞–Ї —А–∞—Б–њ–Њ–ї–Њ–ґ–µ–љ–Є–µ, —Ж–≤–µ—В –Є –њ–Њ—В–µ—А—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –≤ –≤–Є–Ј—Г–∞–ї—М–љ–Њ–Љ –Ї–Њ–і–Є—А–Њ–≤—Й–Є–Ї–µ. –≠—В–Њ —В–∞–Ї–ґ–µ —Г–Ї–∞–Ј—Л–≤–∞–µ—В –љ–∞ –њ–Њ—В–µ–љ—Ж–Є–∞–ї—М–љ—Г—О –≤–µ—А—Е–љ—О—О –≥—А–∞–љ–Є—Ж—Г –і–ї—П –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В–Њ–≤ —Б–ґ–∞—В–Є—П –≤ –±—Г–і—Г—Й–Є—Е –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є—П—Е –Њ–њ—В–Є—З–µ—Б–Ї–Њ–≥–Њ —Б–ґ–∞—В–Є—П —Б–Є–Љ–≤–Њ–ї–Њ–≤, OCR –Є —Б–Љ–µ–ґ–љ—Л—Е –Њ–±–ї–∞—Б—В—П—Е. –Ъ–Њ–і—Л –Є –≤–µ—Б–∞ –Љ–Њ–і–µ–ї–µ–є –і–Њ—Б—В—Г–њ–љ—Л –≤ –Њ—В–Ї—А—Л—В–Њ–Љ –і–Њ—Б—В—Г–њ–µ –њ–Њ —Б—Б—Л–ї–Ї–µ https: https://github.com/liufanfanlff/C3-Co...
Comments
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
![–Ъ–∞–Ї –≤–љ–Є–Љ–∞–љ–Є–µ —Б—В–∞–ї–Њ –љ–∞—Б—В–Њ–ї—М–Ї–Њ —Н—Д—Д–µ–Ї—В–Є–≤–љ—Л–Љ [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg) 2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 6 –Љ–µ—Б—П—Ж–µ–≤ –љ–∞–Ј–∞–і
6 –Љ–µ—Б—П—Ж–µ–≤ –љ–∞–Ј–∞–і
-
 3 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
3 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
-
 1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
-
 2 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
2 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 5 –ї–µ—В –љ–∞–Ј–∞–і
5 –ї–µ—В –љ–∞–Ј–∞–і
-
 4 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
4 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
-
 15 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
15 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
-
 3 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
3 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
-
 11 –Љ–µ—Б—П—Ж–µ–≤ –љ–∞–Ј–∞–і
11 –Љ–µ—Б—П—Ж–µ–≤ –љ–∞–Ј–∞–і
-
 3 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
3 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 2 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і
2 –љ–µ–і–µ–ї–Є –љ–∞–Ј–∞–і