Near Real Time Analytics with Apache Spark: Ingestion, ETL, and Interactive QueriesBrandon Hamric Ev скачать в хорошем качестве
Near Real Time Analytics with Apache Spark: Ingestion, ETL, and Interactive QueriesBrandon Hamric Ev
6 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Near Real Time Analytics with Apache Spark: Ingestion, ETL, and Interactive QueriesBrandon Hamric Ev в качестве 4k
У нас вы можете посмотреть бесплатно Near Real Time Analytics with Apache Spark: Ingestion, ETL, and Interactive QueriesBrandon Hamric Ev или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Near Real Time Analytics with Apache Spark: Ingestion, ETL, and Interactive QueriesBrandon Hamric Ev в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Near Real Time Analytics with Apache Spark: Ingestion, ETL, and Interactive QueriesBrandon Hamric Ev
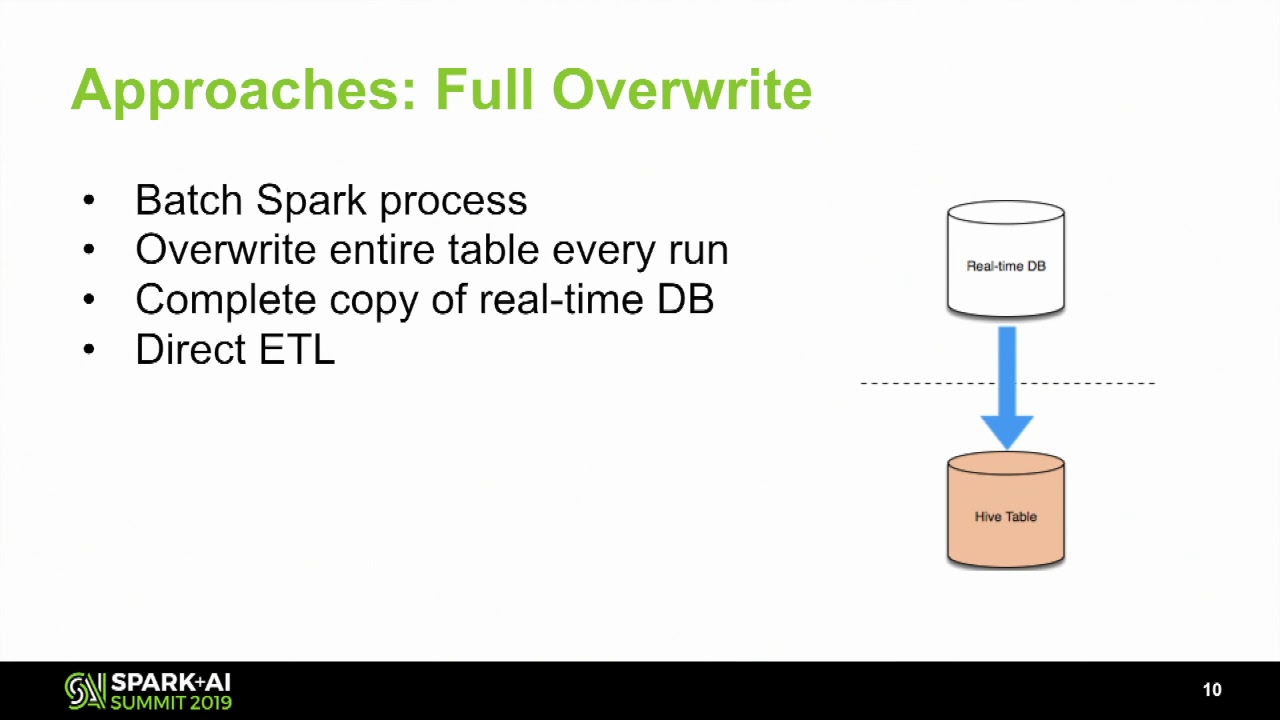
Near real-time analytics has become a common requirement for many data teams as the technology has caught up to the demand. One of the hardest aspects of enabling near-realtime analytics is making sure the source data is ingested and deduplicated often enough to be useful to analysts while writing the data in a format that is usable by your analytics query engine. This is usually the domain of many tools since there are three different aspects of the problem: streaming ingestion of data, deduplication using an ETL process, and interactive analytics. With Spark, this can be done with one tool. This talk with walk you through how to use Spark Streaming to ingest change-log data, use Spark batch jobs to perform major and minor compaction, and query the results with Spark.SQL. At the end of this talk you will know what is required to setup near-realtime analytics at your organization, the common gotchas including file formats and distributed file systems, and how to handle data the unique data integrity issues that arise from near-realtime analytics. About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business. Read more here: https://databricks.com/product/unifie... Connect with us: Website: https://databricks.com Facebook: / databricksinc Twitter: / databricks LinkedIn: / databricks Instagram: / databricksinc Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here. https://databricks.com/databricks-nam...
Comments



















