–Т–≤–µ–і–µ–љ–Є–µ –≤ Vision Transformer. –Ы–µ–Ї—Ж–Є—П 11. –У–ї—Г–±–Њ–Ї–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ —Б–Ї–∞—З–∞—В—М –≤ —Е–Њ—А–Њ—И–µ–Љ –Ї–∞—З–µ—Б—В–≤–µ
–Т–≤–µ–і–µ–љ–Є–µ –≤ Vision Transformer. –Ы–µ–Ї—Ж–Є—П 11. –У–ї—Г–±–Њ–Ї–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ
–Ґ—А–∞–љ—Б–ї—П—Ж–Є—П –Ј–∞–Ї–Њ–љ—З–Є–ї–∞—Б—М 3 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
–Э–µ —Г–і–∞–µ—В—Б—П –Ј–∞–≥—А—Г–Ј–Є—В—М Youtube-–њ–ї–µ–µ—А. –Я—А–Њ–≤–µ—А—М—В–µ –±–ї–Њ–Ї–Є—А–Њ–≤–Ї—Г Youtube –≤ –≤–∞—И–µ–є —Б–µ—В–Є.
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...
–Я–Њ–≤—В–Њ—А—П–µ–Љ –њ–Њ–њ—Л—В–Ї—Г...

–°–Ї–∞—З–∞—В—М –≤–Є–і–µ–Њ —Б —О—В—Г–± –њ–Њ —Б—Б—Л–ї–Ї–µ –Є–ї–Є —Б–Љ–Њ—В—А–µ—В—М –±–µ–Ј –±–ї–Њ–Ї–Є—А–Њ–≤–Њ–Ї –љ–∞ —Б–∞–є—В–µ: –Т–≤–µ–і–µ–љ–Є–µ –≤ Vision Transformer. –Ы–µ–Ї—Ж–Є—П 11. –У–ї—Г–±–Њ–Ї–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ –≤ –Ї–∞—З–µ—Б—В–≤–µ 4k
–£ –љ–∞—Б –≤—Л –Љ–Њ–ґ–µ—В–µ –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –±–µ—Б–њ–ї–∞—В–љ–Њ –Т–≤–µ–і–µ–љ–Є–µ –≤ Vision Transformer. –Ы–µ–Ї—Ж–Є—П 11. –У–ї—Г–±–Њ–Ї–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ –Є–ї–Є —Б–Ї–∞—З–∞—В—М –≤ –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–Љ –і–Њ—Б—В—Г–њ–љ–Њ–Љ –Ї–∞—З–µ—Б—В–≤–µ, –≤–Є–і–µ–Њ –Ї–Њ—В–Њ—А–Њ–µ –±—Л–ї–Њ –Ј–∞–≥—А—Г–ґ–µ–љ–Њ –љ–∞ —О—В—Г–±. –Ф–ї—П –Ј–∞–≥—А—Г–Ј–Ї–Є –≤—Л–±–µ—А–Є—В–µ –≤–∞—А–Є–∞–љ—В –Є–Ј —Д–Њ—А–Љ—Л –љ–Є–ґ–µ:
-
–Ш–љ—Д–Њ—А–Љ–∞—Ж–Є—П –њ–Њ –Ј–∞–≥—А—Г–Ј–Ї–µ:
–°–Ї–∞—З–∞—В—М mp3 —Б —О—В—Г–±–∞ –Њ—В–і–µ–ї—М–љ—Л–Љ —Д–∞–є–ї–Њ–Љ. –С–µ—Б–њ–ї–∞—В–љ—Л–є —А–Є–љ–≥—В–Њ–љ –Т–≤–µ–і–µ–љ–Є–µ –≤ Vision Transformer. –Ы–µ–Ї—Ж–Є—П 11. –У–ї—Г–±–Њ–Ї–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ –≤ —Д–Њ—А–Љ–∞—В–µ MP3:
–Х—Б–ї–Є –Ї–љ–Њ–њ–Ї–Є —Б–Ї–∞—З–Є–≤–∞–љ–Є—П –љ–µ
–Ј–∞–≥—А—Г–Ј–Є–ї–Є—Б—М
–Э–Р–Ц–Ь–Ш–Ґ–Х –Ч–Ф–Х–°–ђ –Є–ї–Є –Њ–±–љ–Њ–≤–Є—В–µ —Б—В—А–∞–љ–Є—Ж—Г
–Х—Б–ї–Є –≤–Њ–Ј–љ–Є–Ї–∞—О—В –њ—А–Њ–±–ї–µ–Љ—Л —Б–Њ —Б–Ї–∞—З–Є–≤–∞–љ–Є–µ–Љ –≤–Є–і–µ–Њ, –њ–Њ–ґ–∞–ї—Г–є—Б—В–∞ –љ–∞–њ–Є—И–Є—В–µ –≤ –њ–Њ–і–і–µ—А–ґ–Ї—Г –њ–Њ –∞–і—А–µ—Б—Г –≤–љ–Є–Ј—Г
—Б—В—А–∞–љ–Є—Ж—Л.
–°–њ–∞—Б–Є–±–Њ –Ј–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —Б–µ—А–≤–Є—Б–∞ ClipSaver.ru
–Т–≤–µ–і–µ–љ–Є–µ –≤ Vision Transformer. –Ы–µ–Ї—Ж–Є—П 11. –У–ї—Г–±–Њ–Ї–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ
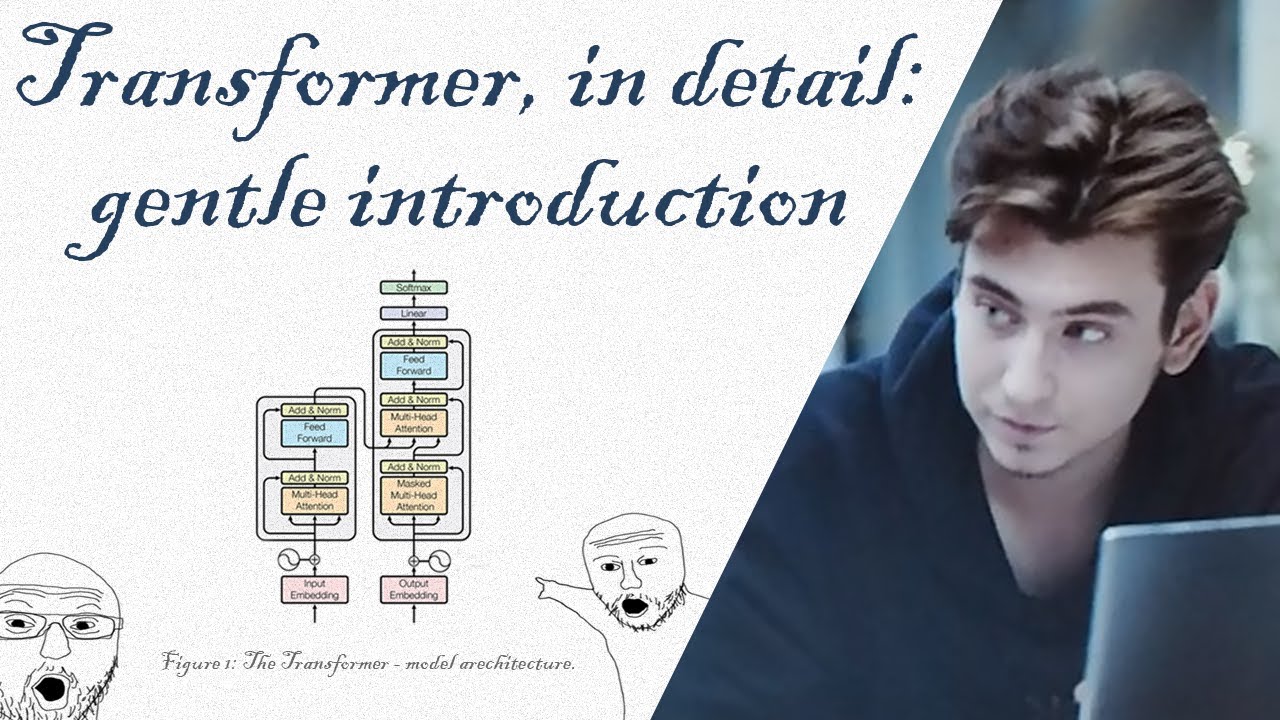
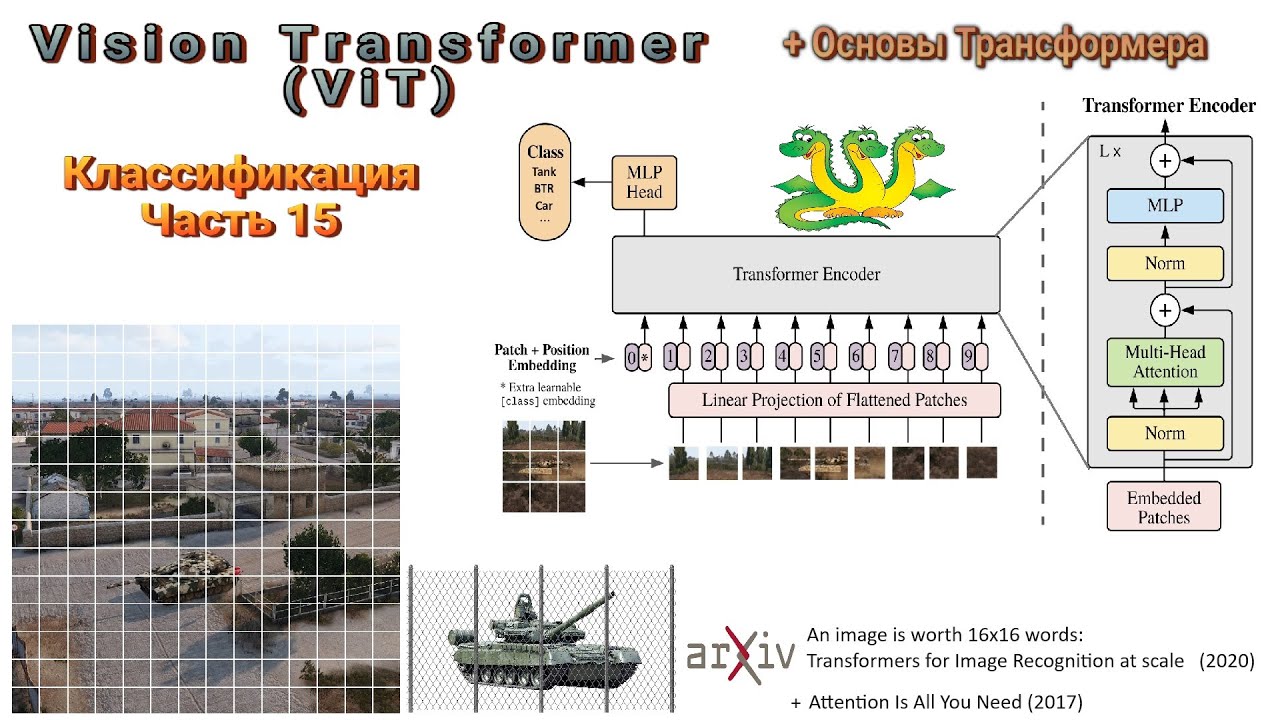
–Т —А–∞–Љ–Ї–∞—Е –ї–µ–Ї—Ж–Є–Є –Љ—Л —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞–µ–Љ –≤–∞–ґ–љ—Г—О –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г вАУ Vision Transformer (ViT). ViT –њ–Њ–Ї–∞–Ј–∞–ї –≤—Л–і–∞—О—Й–Є–µ—Б—П —А–µ–Ј—Г–ї—М—В–∞—В—Л –љ–∞ –Љ–љ–Њ–≥–Є—Е –і–∞—В–∞—Б–µ—В–∞—Е, –њ—А–Є —Н—В–Њ–Љ —Б–∞–Љ–∞ –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ –њ–Њ—З—В–Є –±–µ–Ј –Є–Ј–Љ–µ–љ–µ–љ–Є–є –Ј–∞–Є–Љ—Б—В–≤–Њ–≤–∞–љ–∞ –Є–Ј NLP. –Ґ—А–∞–љ—Б—Д–Њ—А–Љ–µ—А –љ–µ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –љ–Є —Б–≤–µ—А—В–Ї–Є, –љ–Є —А–µ–Ї—Г—А—А–µ–љ—В–љ–Њ—Б—В—М, –∞ –њ–Њ–ї–љ–Њ—Б—В—М—О –њ–Њ–ї–∞–≥–∞–µ—В—Б—П –љ–∞ –Љ–µ—Е–∞–љ–Є–Ј–Љ –≤–љ–Є–Љ–∞–љ–Є—П, –≠—В–Њ –њ–µ—А–≤–∞—П –Є–Ј –і–≤—Г—Е –ї–µ–Ї—Ж–Є–є –љ–∞ —Н—В—Г —В–µ–Љ—Г. –Т —А–∞–Љ–Ї–∞—Е –ї–µ–Ї—Ж–Є–Є —А–∞—Б—Б–Љ–Њ—В—А–µ–љ—Л –Њ—Б–љ–Њ–≤–љ—Л–µ —Б—В—А–Њ–Є—В–µ–ї—М–љ—Л–µ –±–ї–Њ–Ї–Є ViT: Layer Normalization; Scaled Dot-Product Attention (SDPA); Multi-Head Attention (MHA); Feed-Forward Layer. –Э–∞ —Б–ї–µ–і—Г—О—Й–µ–є –ї–µ–Ї—Ж–Є–Є –Љ—Л –Є—Е —Н—В–Є—Е –±–ї–Њ–Ї–Њ–≤ —Б–Њ–±–µ—А—С–Љ –∞—А—Е–Є—В–µ–Ї—В—Г—А—Г ViT :) –Х–≤–≥–µ–љ–Є–є –†–∞–Ј–Є–љ–Ї–Њ–≤ -- –Ї.—Д.-–Љ.–љ., –і–Є—А–µ–Ї—В–Њ—А –њ–Њ –љ–∞—Г–Ї–µ –Ї–Њ–Љ–њ–∞–љ–Є–Є Pr3vision Technologies, –Њ—Б–љ–Њ–≤–∞—В–µ–ї—М –њ–∞—А—Д—О–Љ–µ—А–љ–Њ–≥–Њ AI-–њ—А–Њ–µ–Ї—В–∞ http://scented.ai, —А—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М –Њ—В–і–µ–ї–∞ –Љ–∞—И–Є–љ–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П –Є –Ї–Њ–Љ–њ—М—О—В–µ—А–љ–Њ–≥–Њ –Ј—А–µ–љ–Є—П –У—А—Г–њ–њ—Л –Ї–Њ–Љ–њ–∞–љ–Є–є FIX. Tailor-made AI solutions for unique challenges: https://pr3vision.com –Ш–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Њ –ї–µ–Ї—Ж–Є—П—Е: https://razinkov.ai –Ґ–µ–ї–µ–≥—А–∞–Љ-–Ї–∞–љ–∞–ї —Б –∞–љ–Њ–љ—Б–∞–Љ–Є –ї–µ–Ї—Ж–Є–є –Є –Љ–∞—В–µ—А–Є–∞–ї–∞–Љ–Є –њ–Њ –Љ–∞—И–Є–љ–љ–Њ–Љ—Г –Њ–±—Г—З–µ–љ–Є—О: https://t.me/razinkov_ai
Comments
-
 –Ґ—А–∞–љ—Б–ї—П—Ж–Є—П –Ј–∞–Ї–Њ–љ—З–Є–ї–∞—Б—М 3 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
–Ґ—А–∞–љ—Б–ї—П—Ж–Є—П –Ј–∞–Ї–Њ–љ—З–Є–ї–∞—Б—М 3 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 2 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
2 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 17 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
17 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
-
 6 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
6 —З–∞—Б–Њ–≤ –љ–∞–Ј–∞–і
-
 4 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
4 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 1 –і–µ–љ—М –љ–∞–Ј–∞–і
1 –і–µ–љ—М –љ–∞–Ј–∞–і
-
 3 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
3 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 1 –≥–Њ–і –љ–∞–Ј–∞–і
1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
-
 4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
4 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 5 –і–љ–µ–є –љ–∞–Ј–∞–і
5 –і–љ–µ–є –љ–∞–Ј–∞–і
-
 –Ґ—А–∞–љ—Б–ї—П—Ж–Є—П –Ј–∞–Ї–Њ–љ—З–Є–ї–∞—Б—М 1 –≥–Њ–і –љ–∞–Ј–∞–і
–Ґ—А–∞–љ—Б–ї—П—Ж–Є—П –Ј–∞–Ї–Њ–љ—З–Є–ї–∞—Б—М 1 –≥–Њ–і –љ–∞–Ј–∞–і
-
 2 –і–љ—П –љ–∞–Ј–∞–і
2 –і–љ—П –љ–∞–Ј–∞–і
-
 3 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
3 –≥–Њ–і–∞ –љ–∞–Ј–∞–і
-
 2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
2 –Љ–µ—Б—П—Ж–∞ –љ–∞–Ј–∞–і
-
 1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
1 –Љ–µ—Б—П—Ж –љ–∞–Ј–∞–і
-
 3 –і–љ—П –љ–∞–Ј–∞–і
3 –і–љ—П –љ–∞–Ј–∞–і