Недостающее звено во многих конвейерах данных скачать в хорошем качестве
Недостающее звено во многих конвейерах данных
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Недостающее звено во многих конвейерах данных в качестве 4k
У нас вы можете посмотреть бесплатно Недостающее звено во многих конвейерах данных или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Недостающее звено во многих конвейерах данных в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Недостающее звено во многих конвейерах данных
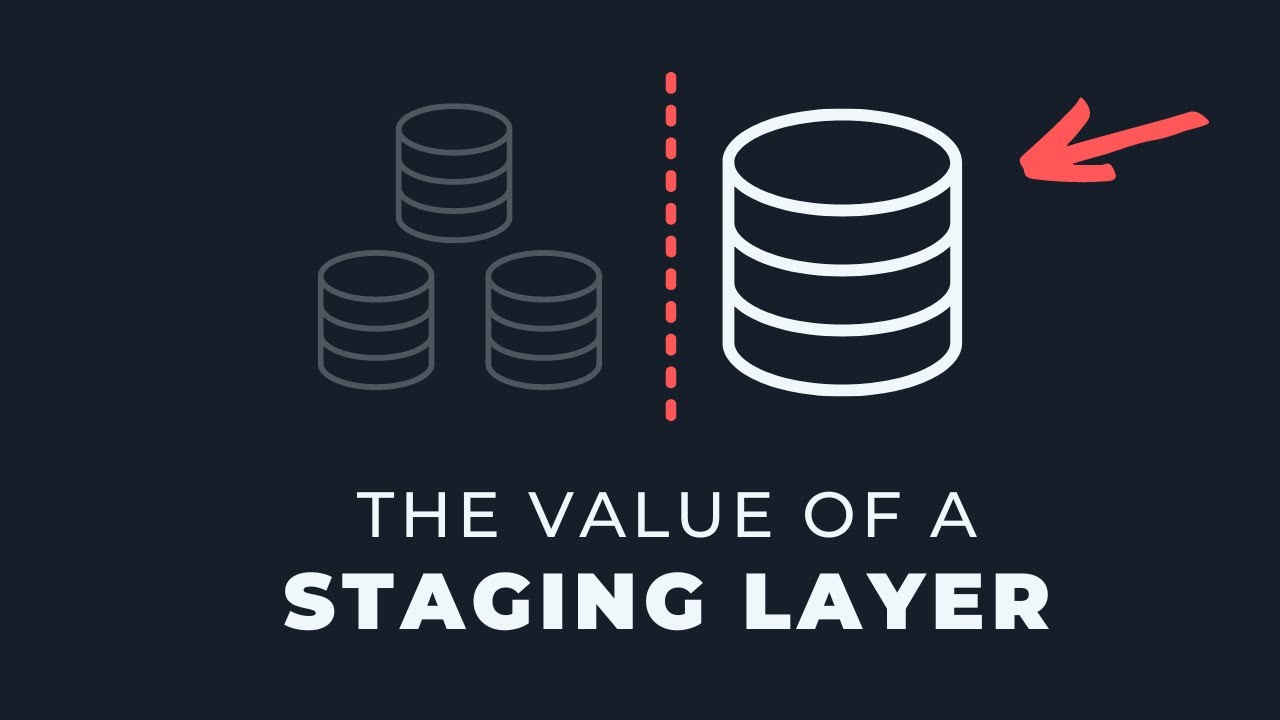
Все мои БЕСПЛАТНЫЕ ресурсы: https://www.skool.com/moderndata/about Консультационные услуги: https://go.kahandatasolutions.com ----- Все команды, работающие с данными (большие и малые), имеют как минимум одну общую черту. Исходные данные. Но не все обрабатывают их одинаково в своих конвейерах. Некоторые напрямую ссылаются на исходные таблицы во многих запросах. Другие создают специальные пользовательские таблицы для обработки незначительных изменений форматирования. Но без какой-либо общей стратегии или последовательного именования. Хотя более популярной темой является моделирование данных (например, модель Кимбалла, одна большая таблица и т. д.), я считаю, что не менее важной областью является то, что вы делаете ДО того, как начнете создавать эти основные модели данных. Для многих этот «предварительный» слой вообще отсутствует. В предыдущих видео я говорил о трехслойной модели данных. Сегодня я хочу сосредоточиться исключительно на первом уровне, который рассматривает эту концепцию. Он называется «промежуточным» уровнем. При правильном подходе он может помочь вам создать надежные конвейеры обработки данных с самого начала. Временные метки: 00:00 - Введение 00:52 - Что такое промежуточный уровень? 03:23 - Причина № 1: Модульность 05:03 - Причина № 2: Согласованность 07:21 - Причина № 3: Ясность Заголовок и теги: Недостающий элемент во многих конвейерах обработки данных #kahandatasolutions #dataengineering #datamodeling
Comments