T1PorEtapasHoH CAJA2SegmentosJPGyPDFNombreNegocio ConFiltro MacM4 20260210 скачать в хорошем качестве
T1PorEtapasHoH CAJA2SegmentosJPGyPDFNombreNegocio ConFiltro MacM4 20260210
1 месяц назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: T1PorEtapasHoH CAJA2SegmentosJPGyPDFNombreNegocio ConFiltro MacM4 20260210 в качестве 4k
У нас вы можете посмотреть бесплатно T1PorEtapasHoH CAJA2SegmentosJPGyPDFNombreNegocio ConFiltro MacM4 20260210 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон T1PorEtapasHoH CAJA2SegmentosJPGyPDFNombreNegocio ConFiltro MacM4 20260210 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
T1PorEtapasHoH CAJA2SegmentosJPGyPDFNombreNegocio ConFiltro MacM4 20260210
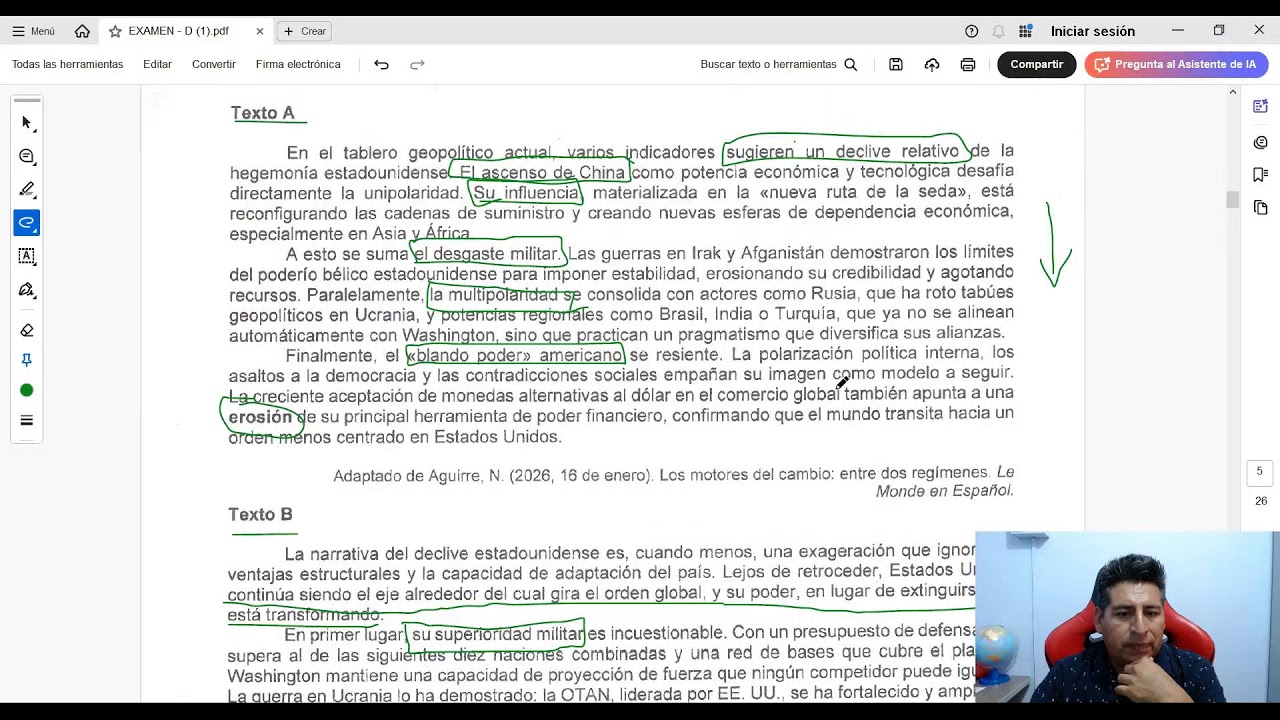
T1PorEtapasHoH CAJA2SegmentosJPGyPDFNombreNegocio ConFiltro MacM4 20260210 WebTeraMetaXtract4AI = Modelo WebTera MetaXtract 4 AI Modelo WebTera de Extracción de Metadatos para la Inteligencia Artificial. WebTeraMetaXtract4AI es una metodología de preparación para la Gobernanza de Grandes Volúmenes de Documentos utilizando sus METADATOS para instrumentar Servicios de Inteligencia Artificial con herramientas para la construcción de servicios de análisis, consulta y búsqueda Se realiza el análisis de archivos de un corpus de fojas, hoja física con Frente y Vuelta, escaneadas y almacenadas en formatos JPG En cada JPG se determina la Talla y MD5 Se buscan las páginas que contienen un SEPARADOR CON UNA IMAGEN CÓDIGO DE BARRAS de tipo CODE39 Se define una lista de Textos ('N01SEP01',...) que deben contener los SEPARADORES La lista se denomina ggListaCadenaCODIGOSEPARADOR En el Corpus se integran SEPARADORES GEMELO que indican que en ese lugar se tenian MAPAS que se escanearon de forma separada Este corpus de mapas se escanea en equipos especiales y se marca con los SEPARADORES GEMELO La lista se denomina ggListaCadenaCODIGOSEPARADORGEMELO ggListaCadenaCODIGOSEPARADORGEMELO = ['TWAIN001','TWAIN002','TWAIN003', ... Se segmenta el conjunto de imágenes JPG basado en los SEPARADORES CON UNA IMÁGEN CODIGO DE BARRAS CODE39 y se integra en un Documento de páginas denominada Segmento Se genera una representacion PDF de cada página, PDF Crudo X página y almacena en un directorio por SEGMENTO Se integran todos los archivos PDF DE UN SEGMENTO en un solo PDF denominado PDFCrudo Para cada imagen JPG se determina la Orientacion Cada imagen JPG que este Rotada de origen, se transforma para tener una imagen que sea horizontal para su preparacion para la extracción del texto. Se genera un PDF Orientado por Página Se integran todos los archivos PDF Orientado por Página DE UN SEGMENTO con Orientación adecuada en un solo PDF denominado PDFOrientado Se genera a partir del PDFOrientado un PDF Buscable Nota: estas 2 líneas nos dan acceso al Tesoro!!! miLlaveTesoroHoH = str(miArchivero)+''+str(miCaja)+''+str(miSegmento) miTesoroHoH = dicActualAlmacenada[miLlaveTesoroHoH]¶
Comments
-
 1 месяц назад
1 месяц назад
-
 3 месяца назад
3 месяца назад
-
 9 часов назад
9 часов назад
-
 23 часа назад
23 часа назад
-
 Трансляция закончилась 10 дней назад
Трансляция закончилась 10 дней назад
-
 3 месяца назад
3 месяца назад
-
 1 месяц назад
1 месяц назад
-
 11 дней назад
11 дней назад
-
 2 недели назад
2 недели назад
-
 3 месяца назад
3 месяца назад
-
 4 дня назад
4 дня назад
-
 4 дня назад
4 дня назад
-
 2 недели назад
2 недели назад
-
 1 месяц назад
1 месяц назад
-
 2 недели назад
2 недели назад
-
 22 часа назад
22 часа назад
-
 22 часа назад
22 часа назад
-
 2 недели назад
2 недели назад
-
 2 месяца назад
2 месяца назад
-
 9 часов назад
9 часов назад