Privacy Amplification from Structured Algorithmic Randomness скачать в хорошем качестве
Privacy Amplification from Structured Algorithmic Randomness
Трансляция закончилась 9 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Privacy Amplification from Structured Algorithmic Randomness в качестве 4k
У нас вы можете посмотреть бесплатно Privacy Amplification from Structured Algorithmic Randomness или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Privacy Amplification from Structured Algorithmic Randomness в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Privacy Amplification from Structured Algorithmic Randomness
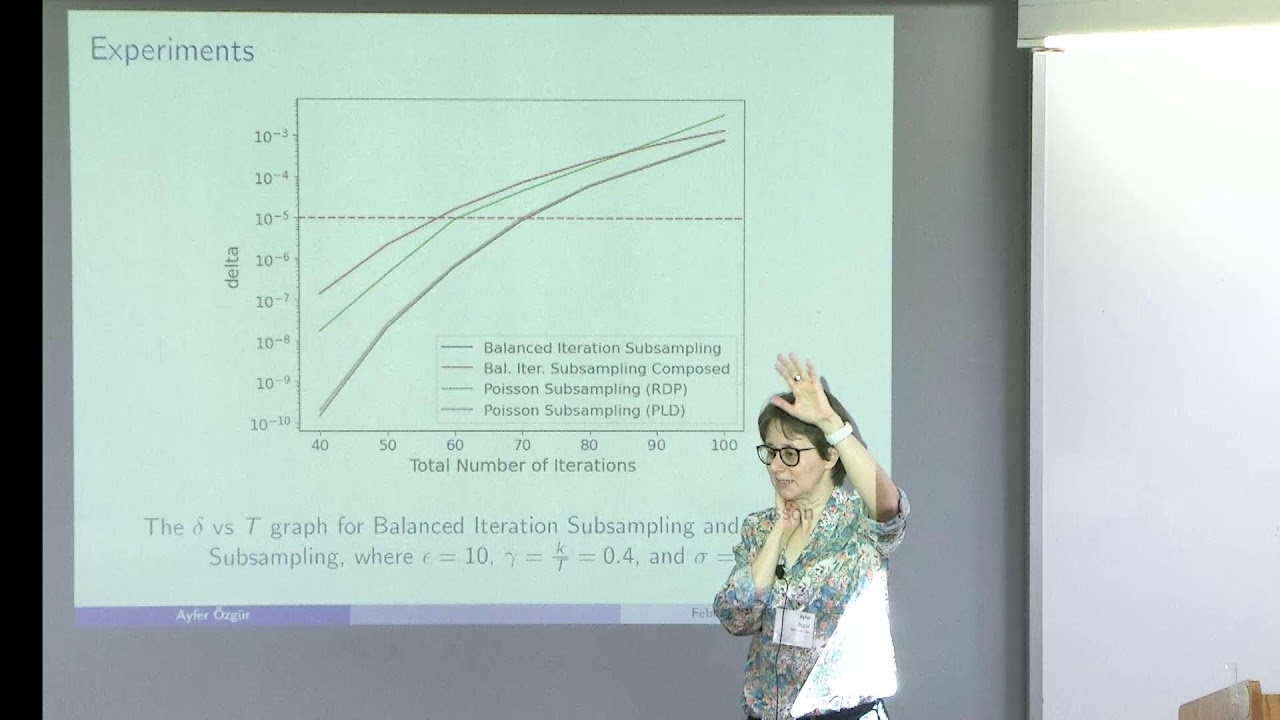
Ayfer Ozgur (Stanford University) https://simons.berkeley.edu/talks/ayf... Learning from Heterogeneous Sources Differentially private training methods typically rely on injecting external noise at each iteration, as in DP-SGD, to limit the influence of individual data points. In this talk, we will explore how inherent algorithmic randomness already embedded in modern AI training pipelines for non-privacy reasons can be harnessed for privacy amplification, thereby reducing reliance on externally injected noise. Prior work has studied privacy amplification through user or data subsampling, but largely under idealized assumptions such as independent Poisson subsampling. In practice, training pipelines exhibit more structured, system-driven forms of randomness. The goal of this talk is twofold: first, to move beyond idealized subsampling models toward structured sampling mechanisms that better reflect real-world constraints; and second, to investigate additional sources of algorithmic randomness, including model partitioning, dropout, and compression, that naturally limit how much information any single sample or user contributes to the final model. We will discuss how these mechanisms can be rigorously quantified to strengthen privacy guarantees at scale.
Comments
-
 Трансляция закончилась 8 дней назад
Трансляция закончилась 8 дней назад
-
 Трансляция закончилась 7 дней назад
Трансляция закончилась 7 дней назад
-
 Трансляция закончилась 9 дней назад
Трансляция закончилась 9 дней назад
-
 Трансляция закончилась 8 дней назад
Трансляция закончилась 8 дней назад
-
 Трансляция закончилась 7 дней назад
Трансляция закончилась 7 дней назад
-
 8 дней назад
8 дней назад
-
 8 дней назад
8 дней назад
-
 1 день назад
1 день назад
-
 2 месяца назад
2 месяца назад
-
 Трансляция закончилась 2 дня назад
Трансляция закончилась 2 дня назад
-
 Трансляция закончилась 7 дней назад
Трансляция закончилась 7 дней назад
-
 20 часов назад
20 часов назад
-
 4 месяца назад
4 месяца назад
-
 Трансляция закончилась 19 часов назад
Трансляция закончилась 19 часов назад
-
 6 месяцев назад
6 месяцев назад
-
 5 дней назад
5 дней назад
-
 7 дней назад
7 дней назад
-
 1 месяц назад
1 месяц назад
-
 6 лет назад
6 лет назад
-
 3 месяца назад
3 месяца назад