Наборы данных для обучения с подкреплением на основе данных скачать в хорошем качестве
Наборы данных для обучения с подкреплением на основе данных
5 лет назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Наборы данных для обучения с подкреплением на основе данных в качестве 4k
У нас вы можете посмотреть бесплатно Наборы данных для обучения с подкреплением на основе данных или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Наборы данных для обучения с подкреплением на основе данных в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Наборы данных для обучения с подкреплением на основе данных
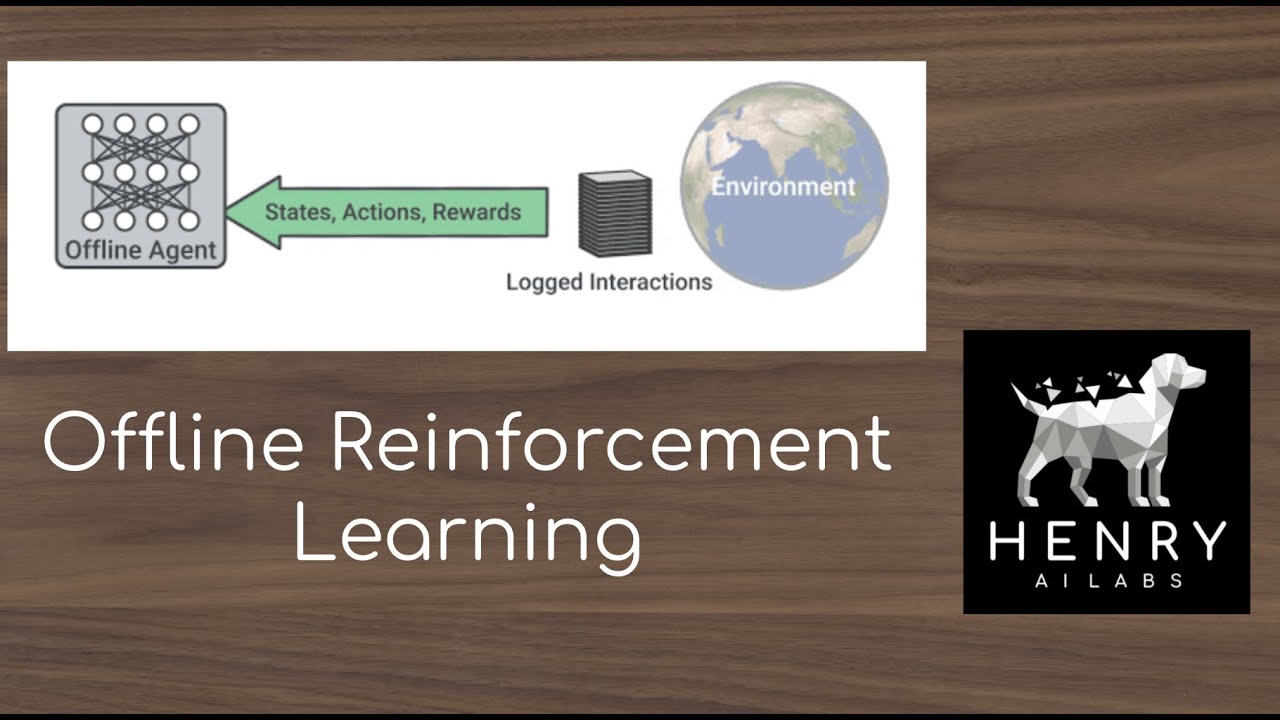
В последнее время офлайн-обучение с подкреплением (RL) становится всё более популярным в областях, где классические алгоритмы RL, основанные на политике, не могут быть обучены, например, для задач, критически важных для безопасности, или обучения на основе демонстраций экспертов. В данной статье представлен обширный сравнительный анализ для оценки офлайн-алгоритмов RL в различных условиях. Документ: https://arxiv.org/abs/2004.07219 Код: https://github.com/rail-berkeley/offl... Аннотация: Проблема офлайн-обучения с подкреплением (RL), также называемая пакетным RL, относится к ситуации, когда политика обучения должна быть изучена на основе набора ранее собранных данных без дополнительного сбора данных онлайн. В контролируемом обучении большие наборы данных и сложные глубокие нейронные сети обеспечили впечатляющий прогресс, в то время как традиционные алгоритмы RL должны собирать большие объёмы данных, основанных на политике, и не добились успеха в использовании ранее собранных наборов данных. В результате существующие тесты обучения с подкреплением плохо подходят для офлайн-обучения, что затрудняет оценку прогресса в этой области. Чтобы разработать тест, адаптированный для офлайн-обучения с подкреплением, мы начинаем с описания ключевых свойств наборов данных, важных для приложений офлайн-обучения с подкреплением. Основываясь на этих свойствах, мы разрабатываем набор тестовых задач и наборов данных, которые оценивают алгоритмы офлайн-обучения с подкреплением в этих условиях. Примерами таких свойств являются: наборы данных, сгенерированные с помощью вручную разработанных контроллеров и демонстраторов-людей, многоцелевые наборы данных, где агент может выполнять различные задачи в одной и той же среде, и наборы данных, состоящие из гетерогенного сочетания траекторий высокого и низкого качества. Разрабатывая тестовые задачи и наборы данных, отражающие свойства реальных задач офлайн-обучения с подкреплением, наш тест сосредоточит исследовательские усилия на методах, которые обеспечивают существенные улучшения не только в смоделированных тестах, но и, в конечном итоге, в тех типах реальных задач, где офлайн-обучение с подкреплением окажет наибольшее влияние. Авторы: Джастин Фу, Авирал Кумар, Офир Нахум, Джордж Такер, Сергей Левин Ссылки: YouTube: / yannickilcher Twitter: / ykilcher BitChute: https://www.bitchute.com/channel/yann... Minds: https://www.minds.com/ykilcher
Comments















![Что ошибочно пишут в книгах об ИИ [Двойной спуск]](https://imager.clipsaver.ru/z64a7USuGX0/max.jpg)


