Cross Attention Made Easy | Decoder Learns from Encoder скачать в хорошем качестве
Cross Attention Made Easy | Decoder Learns from Encoder
2 месяца назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Cross Attention Made Easy | Decoder Learns from Encoder в качестве 4k
У нас вы можете посмотреть бесплатно Cross Attention Made Easy | Decoder Learns from Encoder или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Cross Attention Made Easy | Decoder Learns from Encoder в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Cross Attention Made Easy | Decoder Learns from Encoder
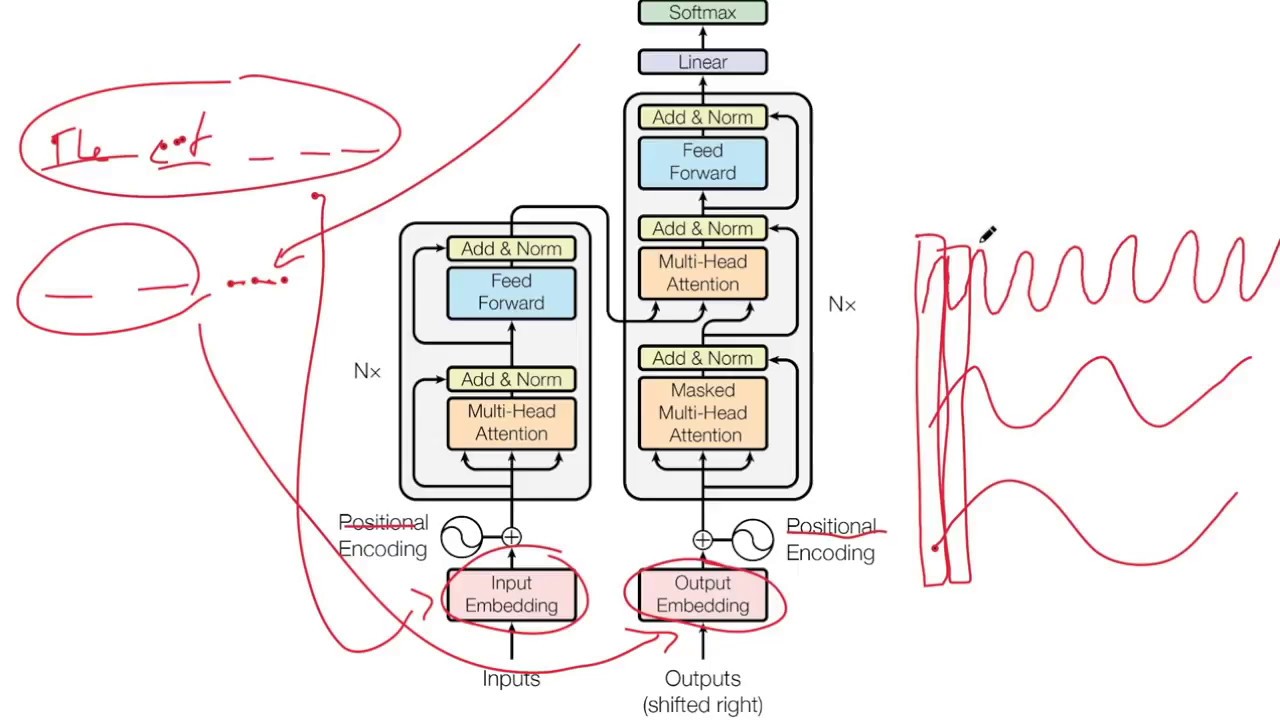
In this video, we explain Cross Attention in Transformers step by step using simple language and clear matrix shapes. You will learn: • Why cross attention is required in the transformer decoder • Difference between masked self-attention and cross-attention • How Query, Key, and Value are created • Why Query comes from the decoder and Key and Value come from the encoder • Matrix shapes used in cross-attention (4×3 and 3×3) • How Q × Kᵀ works with an easy intuitive explanation • Softmax explained with a simple numeric example • How attention weights multiply with the Value matrix • Why cross-attention output size always matches decoder length • Complete transformer decoder flow explained visually This video is perfect for beginners learning Transformers, NLP, LLMs, and Deep Learning, as well as students preparing for machine learning interviews. No heavy math. No confusion. Only clear intuition and correct theory. This video is part of the Transformer Architecture series. Next video: Feed Forward Network in Transformer Decoder. If this video helped you, please like, share, and subscribe to the channel. #CrossAttention #Transformer #TransformerDecoder #AttentionMechanism #SelfAttention #DeepLearning #MachineLearning #NLP #LLM #EncoderDecoder #QueryKeyValue #AI #NeuralNetworks
Comments