Pre-training YOLOv11 by Distilling DINOv3 скачать в хорошем качестве
Pre-training YOLOv11 by Distilling DINOv3
5 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Pre-training YOLOv11 by Distilling DINOv3 в качестве 4k
У нас вы можете посмотреть бесплатно Pre-training YOLOv11 by Distilling DINOv3 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Pre-training YOLOv11 by Distilling DINOv3 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Pre-training YOLOv11 by Distilling DINOv3
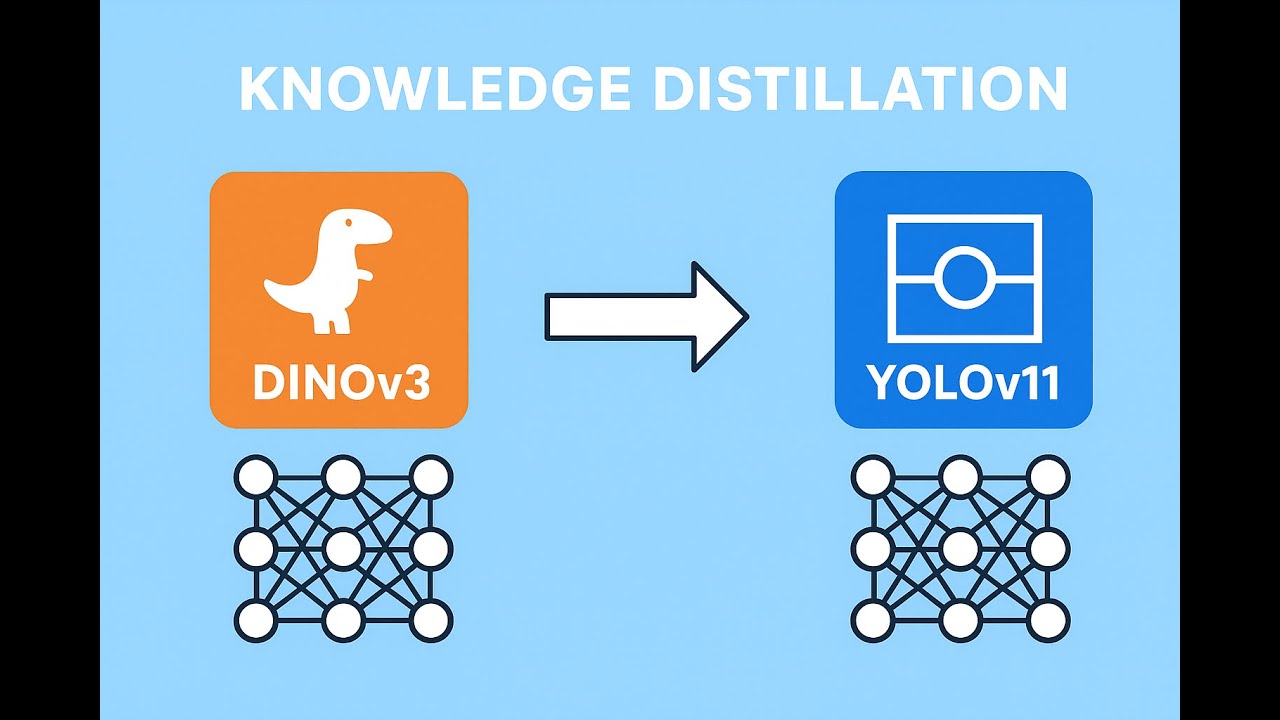
Meta has open-sourced DINOv3’s code and model weights (21M up to 7B parameters) under a generous license. You can load pre-trained DINOv3 backbones via PyTorch or Hugging Face and use for your tasks. DINOv3 (Distillation with No Labels v3) is self-supervised Vision Transformer (ViT), and knowledge distillation can be done without human annotations via LightlyTrain framework. Transfer the rich, general-purpose visual understanding of DINOv3 "teacher" model to a lightweight, efficient YOLOv11 "student" model 🚀. This pre-training step gives the YOLO model a significant head start, leading to better performance, faster convergence, and improved data efficiency when you later fine-tune it on your specific (and smaller) labeled dataset. Image shows mAP50:95(P) and FPS for INT8 and FP16 quantized YOLOv11 (large and nano) models after distillation and fine-tuning. Nano models achive close to 700FPS at mAP50:95(P) of 0.91 🤯🚀🚀 Check out the Python code if you want to pre-train your own YOLOv11 model with DINOv3's knowledge: Github Repo: https://github.com/farhanaugustine/DI...
Comments

![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)


![How AI Taught Itself to See [DINOv3]](https://imager.clipsaver.ru/oGTasd3cliM/max.jpg)