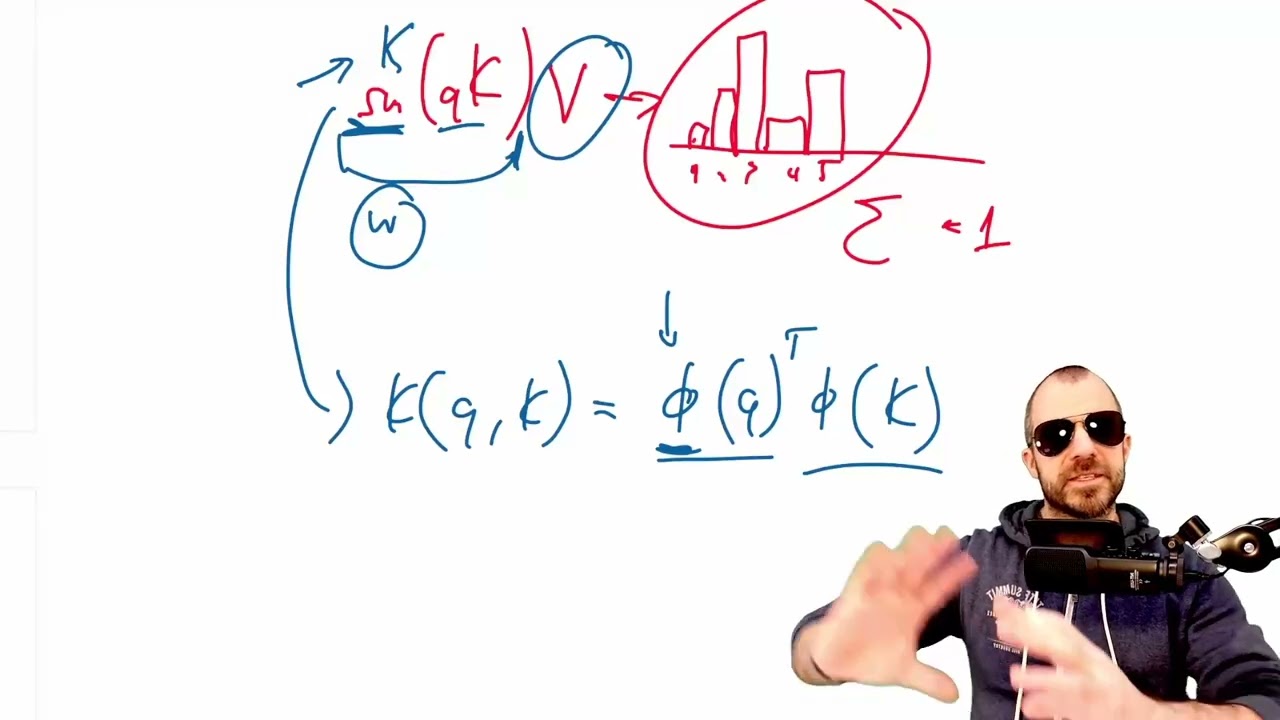Expire-Span: Not All Memories are Created Equal: Learning to Forget by Expiring (Paper Explained) скачать в хорошем качестве
Expire-Span: Not All Memories are Created Equal: Learning to Forget by Expiring (Paper Explained)
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Expire-Span: Not All Memories are Created Equal: Learning to Forget by Expiring (Paper Explained) в качестве 4k
У нас вы можете посмотреть бесплатно Expire-Span: Not All Memories are Created Equal: Learning to Forget by Expiring (Paper Explained) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Expire-Span: Not All Memories are Created Equal: Learning to Forget by Expiring (Paper Explained) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Expire-Span: Not All Memories are Created Equal: Learning to Forget by Expiring (Paper Explained)
#expirespan #nlp #facebookai Facebook AI (FAIR) researchers present Expire-Span, a variant of Transformer XL that dynamically assigns expiration dates to previously encountered signals. Because of this, Expire-Span can handle sequences of many thousand tokens, while keeping the memory and compute requirements at a manageable level. It severely matches or outperforms baseline systems, while consuming much less resources. We discuss its architecture, advantages, and shortcomings. OUTLINE: 0:00 - Intro & Overview 2:30 - Remembering the past in sequence models 5:45 - Learning to expire past memories 8:30 - Difference to local attention 10:00 - Architecture overview 13:45 - Comparison to Transformer XL 18:50 - Predicting expiration masks 32:30 - Experimental Results 40:00 - Conclusion & Comments Paper: https://arxiv.org/abs/2105.06548 Code: https://github.com/facebookresearch/t... ADDENDUM: I mention several times that the gradient signal of the e quantity only occurs inside the R ramp. By that, I mean the gradient stemming from the model loss. The regularization loss acts also outside the R ramp. Abstract: Attention mechanisms have shown promising results in sequence modeling tasks that require long-term memory. Recent work investigated mechanisms to reduce the computational cost of preserving and storing memories. However, not all content in the past is equally important to remember. We propose Expire-Span, a method that learns to retain the most important information and expire the irrelevant information. This forgetting of memories enables Transformers to scale to attend over tens of thousands of previous timesteps efficiently, as not all states from previous timesteps are preserved. We demonstrate that Expire-Span can help models identify and retain critical information and show it can achieve strong performance on reinforcement learning tasks specifically designed to challenge this functionality. Next, we show that Expire-Span can scale to memories that are tens of thousands in size, setting a new state of the art on incredibly long context tasks such as character-level language modeling and a frame-by-frame moving objects task. Finally, we analyze the efficiency of Expire-Span compared to existing approaches and demonstrate that it trains faster and uses less memory. Authors: Sainbayar Sukhbaatar, Da Ju, Spencer Poff, Stephen Roller, Arthur Szlam, Jason Weston, Angela Fan Links: TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick YouTube: / yannickilcher Twitter: / ykilcher Discord: / discord BitChute: https://www.bitchute.com/channel/yann... Minds: https://www.minds.com/ykilcher Parler: https://parler.com/profile/YannicKilcher LinkedIn: / yannic-kilcher-488534136 BiliBili: https://space.bilibili.com/1824646584 If you want to support me, the best thing to do is to share out the content :) If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this): SubscribeStar: https://www.subscribestar.com/yannick... Patreon: / yannickilcher Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2 Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Comments