Expectation Maximization (EM) for MEME Motif Discovery in Bioinformatics (Part 1 of 3) скачать в хорошем качестве
Expectation Maximization (EM) for MEME Motif Discovery in Bioinformatics (Part 1 of 3)
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Expectation Maximization (EM) for MEME Motif Discovery in Bioinformatics (Part 1 of 3) в качестве 4k
У нас вы можете посмотреть бесплатно Expectation Maximization (EM) for MEME Motif Discovery in Bioinformatics (Part 1 of 3) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Expectation Maximization (EM) for MEME Motif Discovery in Bioinformatics (Part 1 of 3) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Expectation Maximization (EM) for MEME Motif Discovery in Bioinformatics (Part 1 of 3)
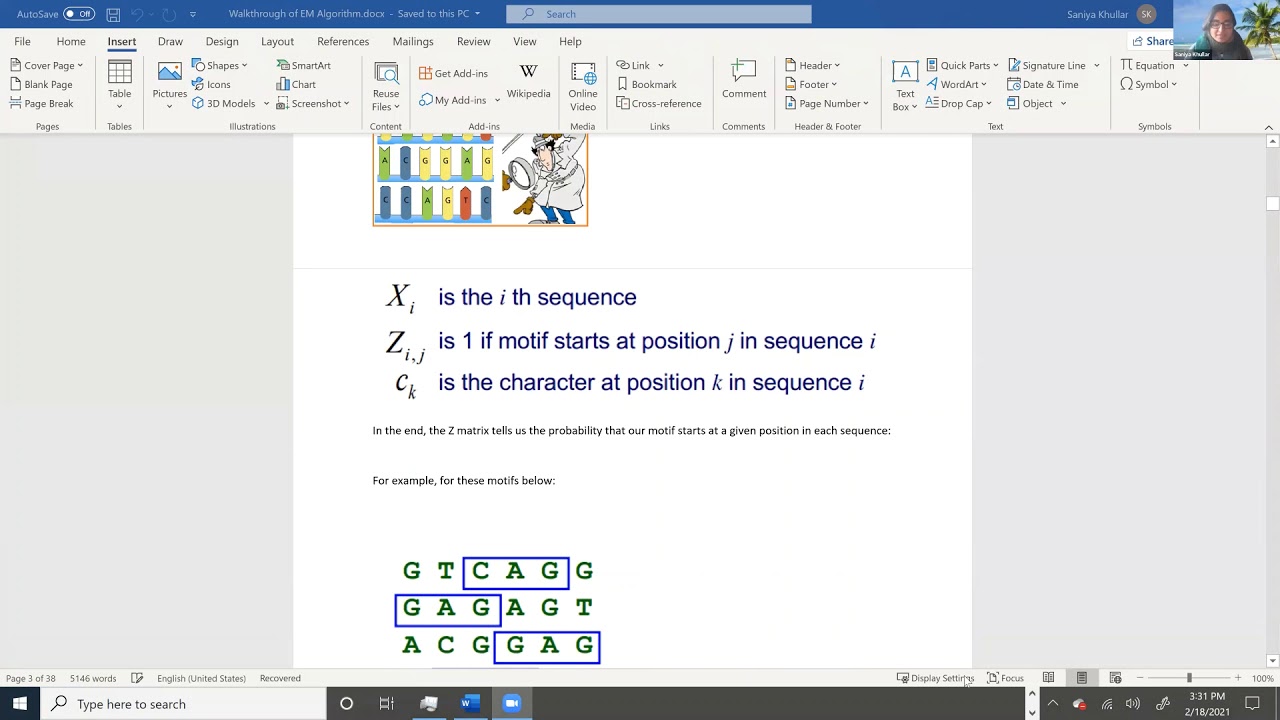
Please note: MEME is Multiple Expectation maximizations for Motif Elicitation. In bioinformatics, motifs typically are sequence patterns that occur many times in a group of related protein or DNA sequences. Typically, motifs are associated with some biological function (e.g. Transcription Factor Binding Sites where Transcription Factors bind to regulatory elements like promoters/enhancers). Saniya goes through a detailed toy example of applying MEME algorithm to learn a Position Weight Matrix (PWM) and associated motif occurrences. Please note this is the 1st of 3 detailed videos walking through an example of using MEME to discover motifs for TF binding. Part 1 of 3 (current video): • Expectation Maximization (EM) for MEME Mot... Part 2 of 3: • Expectation Maximization (EM) for MEME Mot... Part 3 of 3: • Expectation Maximization (EM) for MEME Mot... Please note PWM should actually be called the Position Weighted Matrix and not Probability Weighted Matrix. Sorry about that! Also, Saniya made a mistake! There are 11 unique motifs that are found across all 4 sequences :) GTC, TCA, CAG, AGG, GAG, AGA, AGT, ACG, CGG, GGA, CCA. Alas, Saniya could not put this correction into the video and mistakenly said 9 motifs, when there really are 11! :( Please reach out with any and all questions and please subscribe to Saniya's YouTube channel for more updates. ************ Please note this toy example: ************ L = 6 bases (length of the DNA sequence) W = 3 bases (motif bases); please note this is a parameter we selected. N = 4 sequences Please note these 4 DNA sequences: 1. GTCAGG 2. GAGAGT 3. ACGGAG 4. CCAGTC Using MEME algorithm, please find the Position Weight Matrix (PWM) including background (non-motif) probabilities. Please also find the occurrences of the motifs in these 4 sequences. :) ************************************************************************ TIME STAMPS: 00:00 Expectation Maximization (EM) for MEME Motif Discovery in Bioinformatics (Part 1 of 3) 00:21 Transcription Factors (TFs) bind to sequence-specific motifs along DNA: to their respective Transcription Factor Binding Sites (TFBSs) 01:21 Motif Model Learning Task (Multiple Expectation maximizations for Motif Elicitation) 02:35 What is Expectation Maximization (EM)? ============================ The example problem we will work on in these next 3 videos :) =========================== 02:57 The problem: Finding Motifs of Width 3 in 4 DNA sequences of Length L = 6 Bases 04:06 Finding the possible starting positions for the motifs in the sequences (based on W and L: motif width versus sequence length): m = 4 possible starting positions ======== Finding all of the unique motifs that are possible 04:52 Finding possible motifs for Sequence 1: GTC, TCA, CAG, AGG 05:31 Finding possible motifs for Sequence 2: GAG, AGA, AGT 05:56 Finding possible motifs for Sequence 3: ACG, CGG, GGA, GAG 06:10 Finding possible motifs for Sequence 4: CCA, CAG, AGT, GTC 06:38 The 11 total unique motifs: GTC, TCA, CAG, AGG, GAG, AGA, AGT, ACG, CGG, GGA, CCA (please note 9 was a mistake; there are actually 11 motifs across all 4 sequences) 07:05 Understanding the Z matrix: probability of the motif starting in a given position in each sequence. Z matrix has N rows (1 for each sequence) and m columns (1 for each possible start position for the motif) 12:08 How to initialize the Z matrix (setting equally likely probability values): values of 1/m for each entry in Z matrix. 12:53 Using Subsequences as Starting Points for EM (Initializing a PWM for a given motif) 15:18 Assumptions about background (non-motif probabilities) in the initial PWMs: backgrounds are initially 25% for each DNA base.
Comments