GDPO: 다중 보상 강화학습 최적화 – 보상 신호 붕괴 해결 & GRPO 한계 극복 скачать в хорошем качестве
GDPO: 다중 보상 강화학습 최적화 – 보상 신호 붕괴 해결 & GRPO 한계 극복
2 дня назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: GDPO: 다중 보상 강화학습 최적화 – 보상 신호 붕괴 해결 & GRPO 한계 극복 в качестве 4k
У нас вы можете посмотреть бесплатно GDPO: 다중 보상 강화학습 최적화 – 보상 신호 붕괴 해결 & GRPO 한계 극복 или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон GDPO: 다중 보상 강화학습 최적화 – 보상 신호 붕괴 해결 & GRPO 한계 극복 в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
GDPO: 다중 보상 강화학습 최적화 – 보상 신호 붕괴 해결 & GRPO 한계 극복
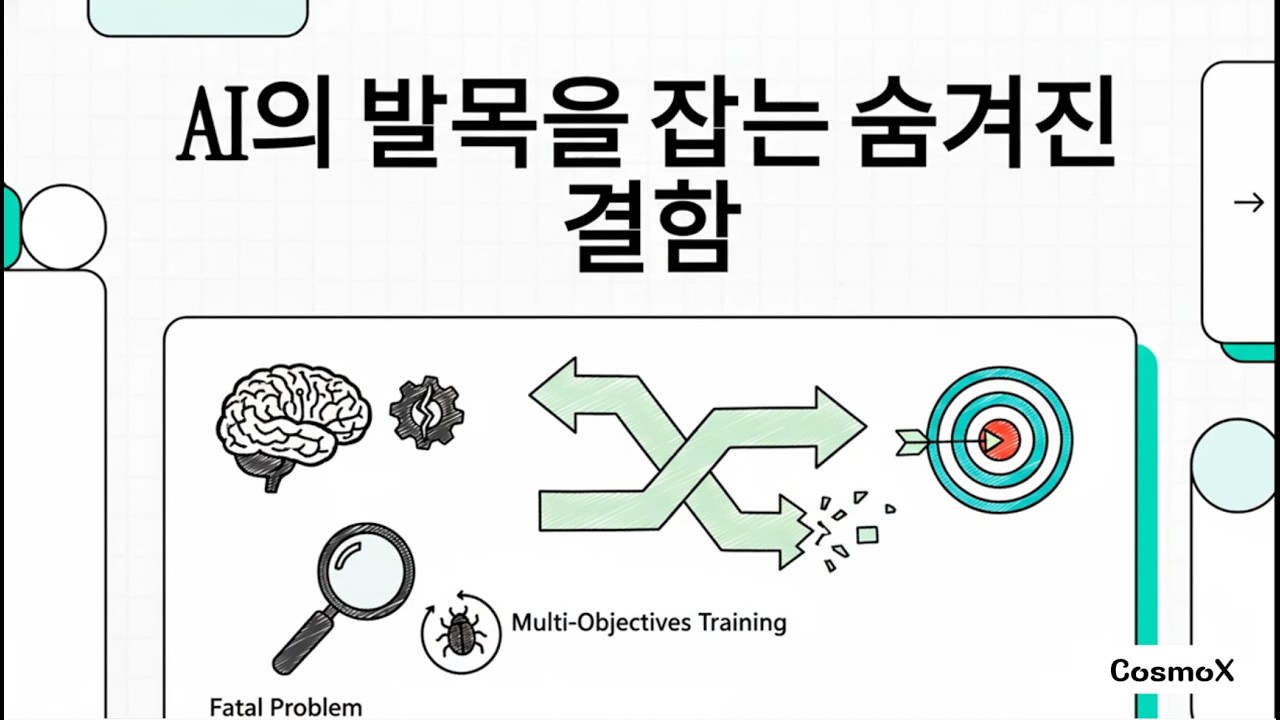
🧠 논문 “GDPO: Group reward-Decoupled Normalization Policy Optimization” 핵심 요약 🔍 다중 보상 강화학습(Multi-reward RL)에서 발생하는 GRPO 보상 신호 붕괴 문제 설명 💡 GDPO가 어떻게 보상 정규화(decoupled normalization) 를 분리해 해결하는지 🚀 다양한 태스크(도구 호출, 수학/코드 추론)에서의 GDPO vs GRPO 성능 비교 📈 GDPO가 더 안정적이고 높은 성능을 보여주는 이유 📚 연구 결과와 강화학습 최적화 적용 시사점 #강화학습 #ReinforcementLearning #GDPO #멀티보상 #MachineLearning #AI연구 #정책최적화
Comments
-
 2 дня назад
2 дня назад
-
 2 дня назад
2 дня назад
-
 4 месяца назад
4 месяца назад
-
 2 месяца назад
2 месяца назад
-
 2 года назад
2 года назад
-
![무시무시한 증시 급등락 그래도 7천피 가능합니다 - 홍춘욱 대표 (프리즘투자자문) [성공예감 이대호입니다] | KBS 260209 방송](https://imager.clipsaver.ru/JUm0D2aJUVw/max.jpg) 1 день назад
1 день назад
-
 5 месяцев назад
5 месяцев назад
-
 Трансляция закончилась 9 дней назад
Трансляция закончилась 9 дней назад
-
 7 месяцев назад
7 месяцев назад
-
 10 месяцев назад
10 месяцев назад
-
 Трансляция закончилась 1 час назад
Трансляция закончилась 1 час назад
-
 1 месяц назад
1 месяц назад
-
 8 месяцев назад
8 месяцев назад
-
 2 недели назад
2 недели назад
-
 2 месяца назад
2 месяца назад
-
 Трансляция закончилась 16 часов назад
Трансляция закончилась 16 часов назад
-
 12 дней назад
12 дней назад
-
 1 месяц назад
1 месяц назад
-
 3 месяца назад
3 месяца назад
-
 1 год назад
1 год назад