Contrastive Language-Image Pre-training (CLIP) скачать в хорошем качестве
Contrastive Language-Image Pre-training (CLIP)
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Contrastive Language-Image Pre-training (CLIP) в качестве 4k
У нас вы можете посмотреть бесплатно Contrastive Language-Image Pre-training (CLIP) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Contrastive Language-Image Pre-training (CLIP) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Contrastive Language-Image Pre-training (CLIP)
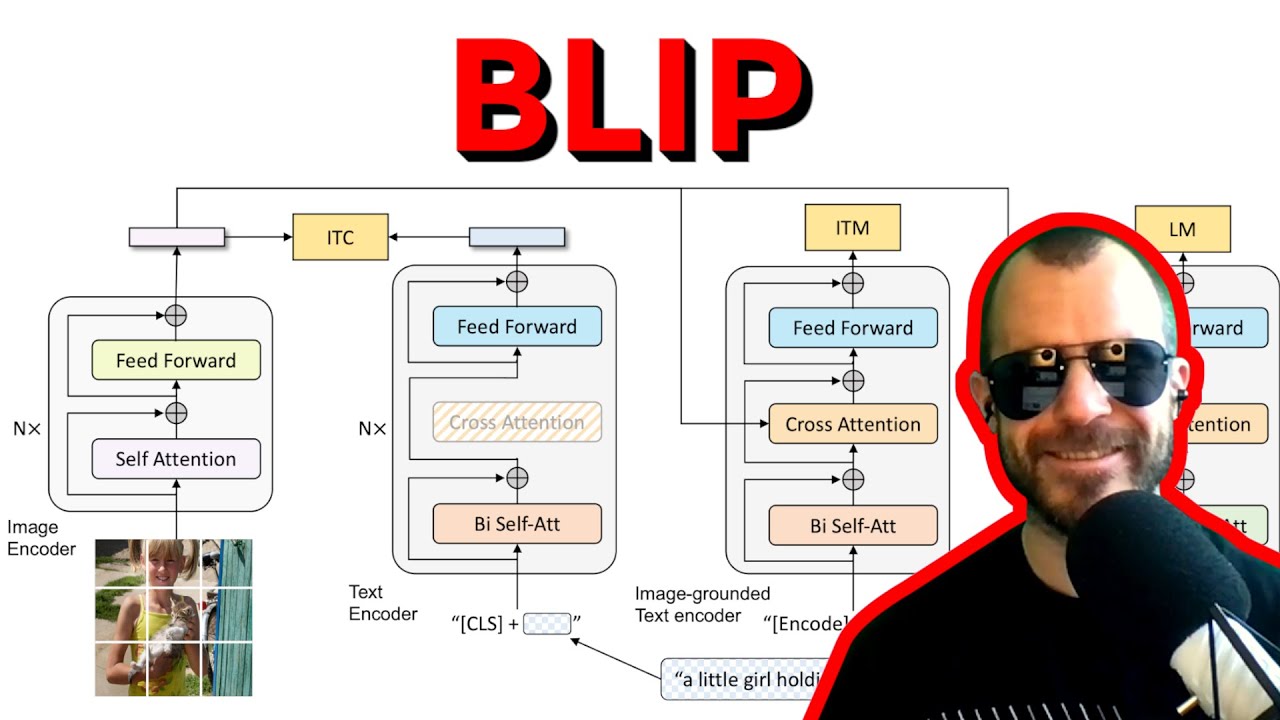
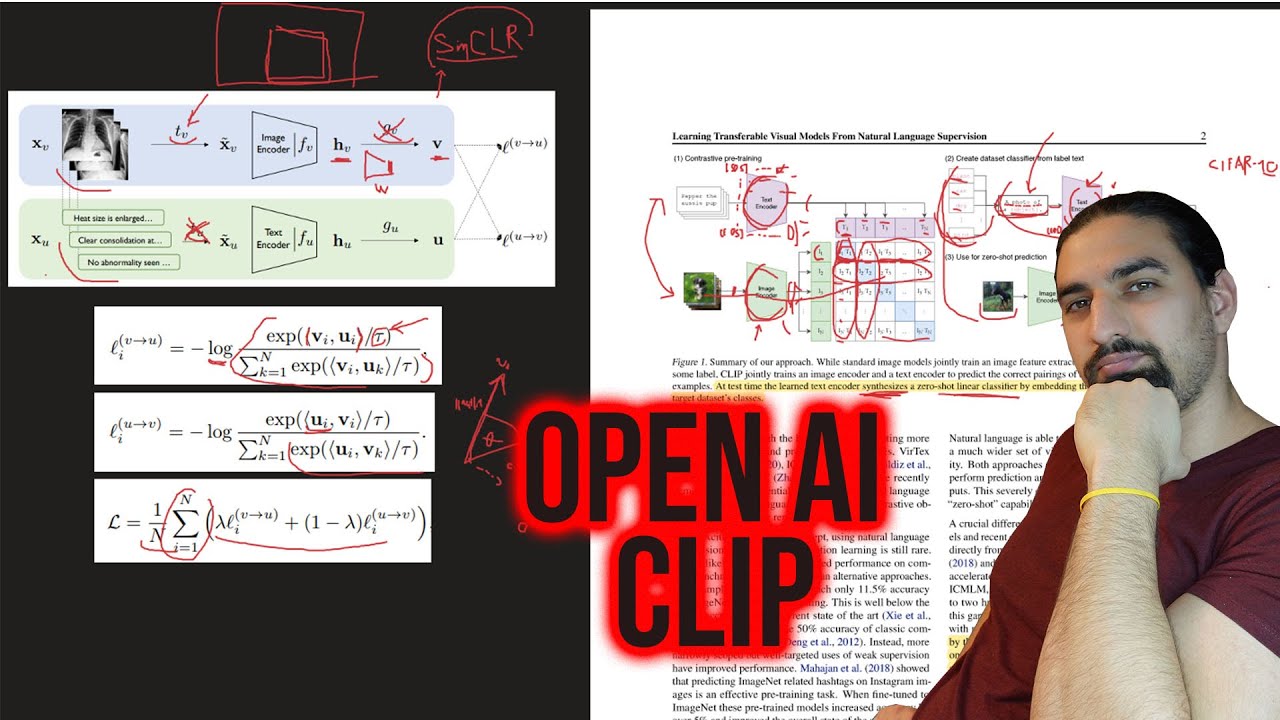
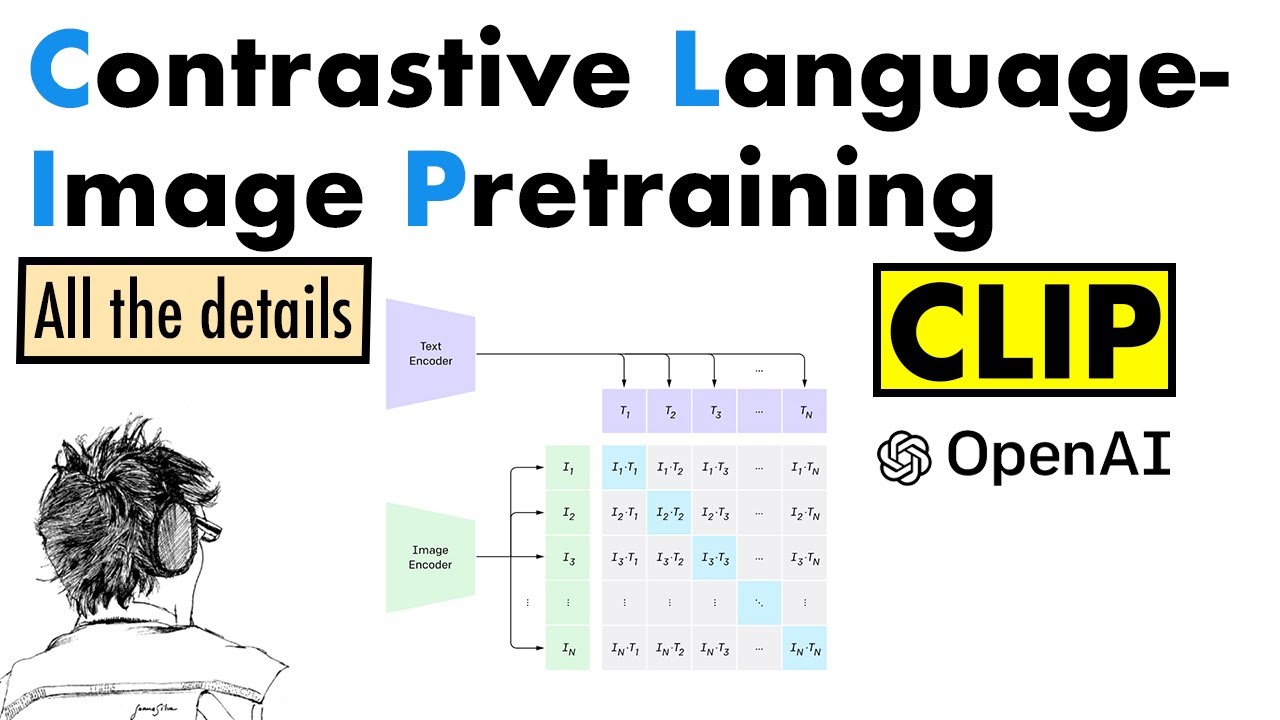
CLIP was introduced in the work "Learning transferable visual models from natural language supervision" by A. Radford et al. at ICML in 2021. This video describes the details. Timestamps: 00:00 - Contrastive Language-Image Pre-training 00:26 - Outline 01:02 - Motivation 03:46 - Building Blocks 07:39 - Contrastive Pre-training 12:34 - Training - nuts and bolts 14:56 - Experiments 17:58 - Using CLIP for Zero-shot Transfer 20:30 - Initial zero-shot transfer experiments/prompting 24:43 - Zero-shot analysis 28:28 - Zero-shot vs few-shot 31:28 - Zero-shot optimality and model scaling 33:38 - Representation Learning 37:03 - Robustness to natural distribution shifts 39:37 - Robustness to anatural distribution shifts (qualitative) 40:50 - How does ImageNet adaptation affect robustness? 45:19 - Comparison to Human Performance 47:17 - Downstream applications 51:17 - Data Overlap Analysis: Approach 54:21 - Data Overlap Analysis: Results 57:39 - Limitations 01:01:25 - Broader Impacts 01:03:52 - Broader Impacts - analysis 1:07:00 - Broader Impacts - surveillance 1:09:17 - Related Work 1:12:40 - Summary Detailed description: We begin by noting the motivations for CLIP: increased flexibility from zero-shot transfer, the desire to leverage the data efficiency of natural language and the suggestion that web text may enable continued vision scaling. We next describe how the 400M image-text pair dataset for CLIP was created and how the contrastive pre-training approach was selected. We discuss the implementation of the loss, the size of the image and text encoders and the optimisation details used for training. We then turn to the experiments, which focus heavily on CLIP's ability to perform zero-shot transfer, but also evaluate its features under traditional representation learning and robustness evaluation protocols. Zero-shot CLIP is found to work well across a suite of 27 datasets, often proving competitive with supervised linear probes on ResNet-50 features Performance scales fairly smoothly with model size (following a log-linear trend), with larger models performing better. We examine a comparison between CLIP and human performance on the Oxford IIT Pets dataset (37-way dog/cat breed classification), where it is found, among other observations, that images that are hard for CLIP are also hard for humans. Several downstream applications are identified including text and image retrieval, optical character recognition, action recognition and geolocalisation. We next describe the data overlap analysis conducted by the CLIP authors, which suggests that data contamination does not have a major effect on results. We discuss the limitations of the model, touching on zero-shot performance, flexibility, data efficiency, methodology, the use of uncurated (biased) data and room for few-shot improvement. Broader impacts are also discussed, with an accompanying analysis on Fairface, a gender study on congress, and an exploration of CLIP's uses for surveillance. We conclude with a summary of related work on image-to-word transformation, webly-supervised learning, vision/language pre-training and shared vision and language models, and a final summary. Topics: #computervision, #machinelearning, #clip Slides (pdf): https://samuelalbanie.com/files/diges... A full list of the references for the video can be found at http://samuelalbanie.com/digests/2022... For related content: YouTube: / @samuelalbanie1 Twitter: / samuelalbanie For (optional) coffee donations: https://www.buymeacoffee.com/samuelal... / samuel_albanie
Comments


![[EEML'24] Jovana Mitrović - Vision Language Models](https://imager.clipsaver.ru/rUQUv4u7jFs/max.jpg)