Mastering Amazon Athena: SQL on S3, AWS Glue Integration, and Automated Schema Management скачать в хорошем качестве
Mastering Amazon Athena: SQL on S3, AWS Glue Integration, and Automated Schema Management
3 дня назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Mastering Amazon Athena: SQL on S3, AWS Glue Integration, and Automated Schema Management в качестве 4k
У нас вы можете посмотреть бесплатно Mastering Amazon Athena: SQL on S3, AWS Glue Integration, and Automated Schema Management или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Mastering Amazon Athena: SQL on S3, AWS Glue Integration, and Automated Schema Management в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Mastering Amazon Athena: SQL on S3, AWS Glue Integration, and Automated Schema Management
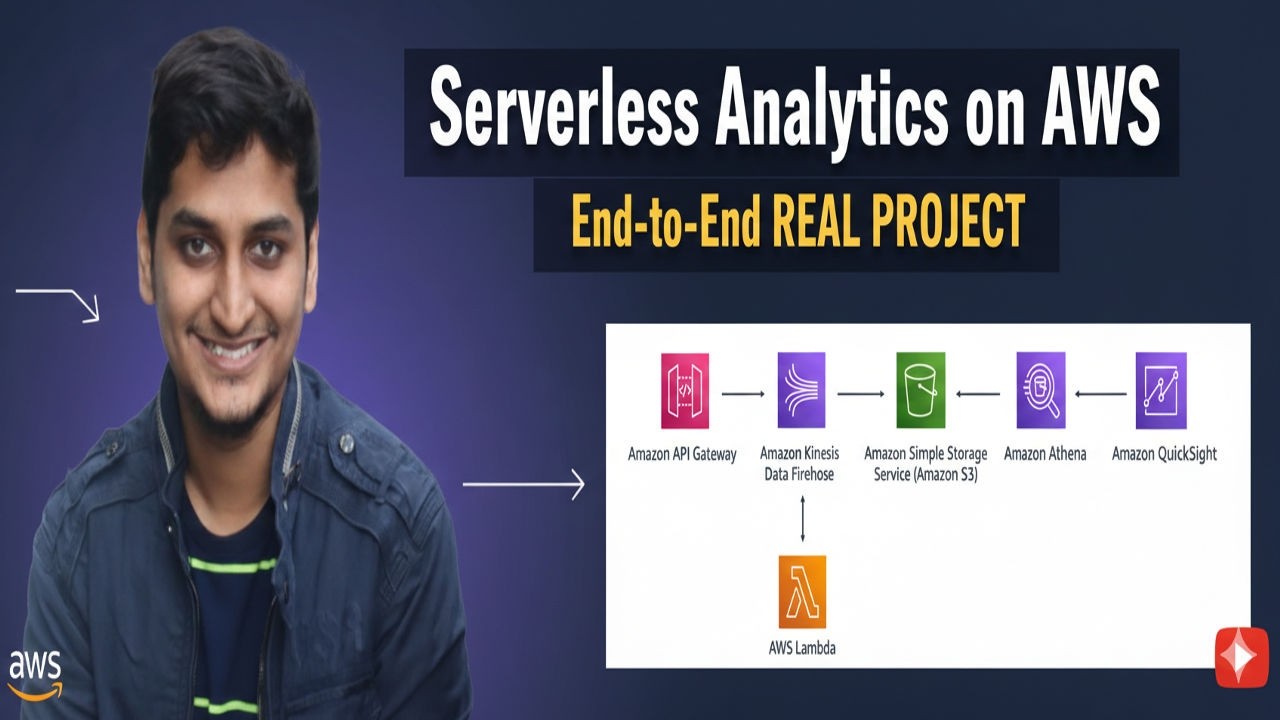
Stop moving your data and start querying it! 🚀 In this tutorial, we dive deep into Amazon Athena, the serverless interactive query service that lets you analyze data directly in Amazon S3 using standard SQL. We cover everything from setting up your first database to handling complex CSV headers and preparing for automated schema discovery with AWS Glue. In this video, you will learn: ✅ Athena Federated Queries: How to query data across different sources without moving it. ✅ Setting up Athena: Configuring S3 query result locations for better data management. ✅ SQL Deep Dive: Creating databases and External Tables in Athena. ✅ SerDe Explained: What is LazySimpleSerDe and why it’s critical for text-based files like CSV and TSV. ✅ Handling CSV Headers: How to use table properties to skip header rows for clean data results. ✅ Practical SQL Analysis: Executing distinct counts, aggregations (sales per category), and date-based queries. ✅ Efficiency Challenge: Why manual schema definition fails for large datasets and how AWS Glue Crawlers provide the solution. Key Technical Concepts: Difference between Internal and External Tables. The role of the AWS Glue Data Catalog. Data Aggregation and Transformation using Presto/Trino SQL. Preparing for Python/Pandas integration for automated schema inference.
Comments