RL-1B: State, Action, Reward, Policy, State Transition скачать в хорошем качестве
RL-1B: State, Action, Reward, Policy, State Transition
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: RL-1B: State, Action, Reward, Policy, State Transition в качестве 4k
У нас вы можете посмотреть бесплатно RL-1B: State, Action, Reward, Policy, State Transition или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон RL-1B: State, Action, Reward, Policy, State Transition в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
RL-1B: State, Action, Reward, Policy, State Transition
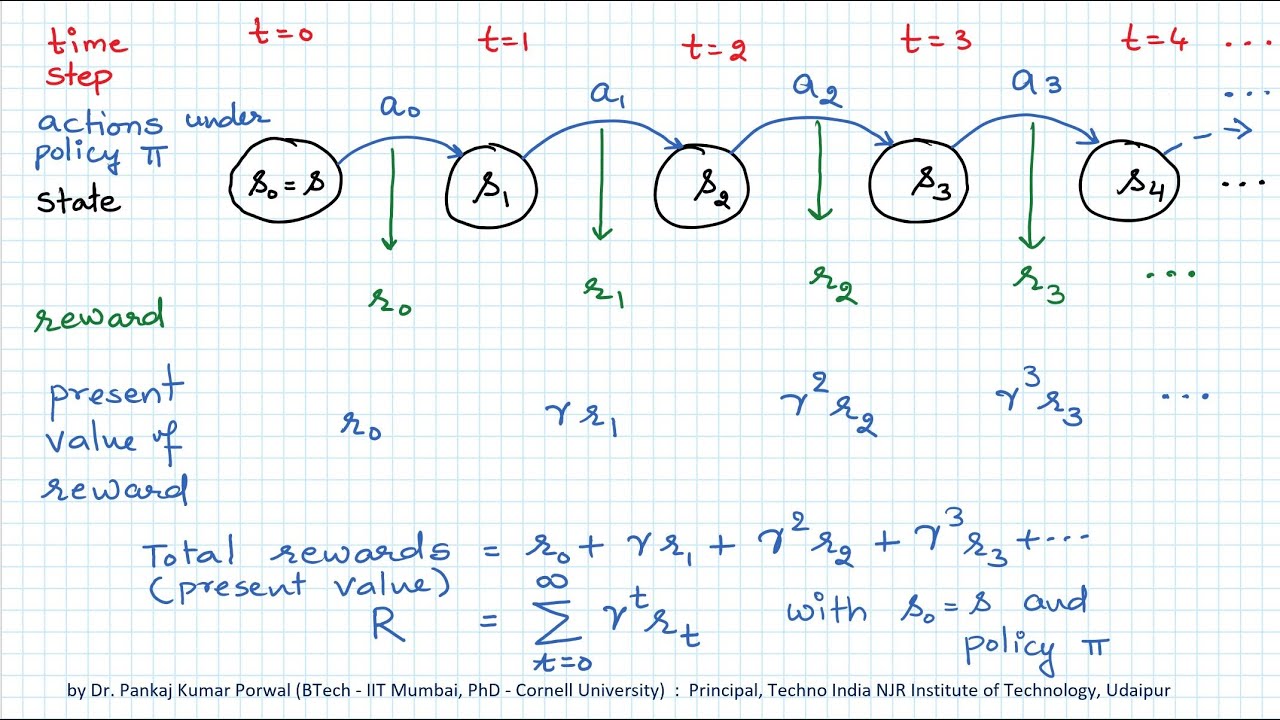
Next Video: • RL-1C: Randomness in MDP, Agent-Environmen... This lecture introduces the basic concepts of reinforcement learning, including state, action, reward, policy, and state transition. Slides: https://github.com/wangshusen/DRL.git
Comments