ICRA'2021 Talk - General-Sum Multi-Agent Continuous Inverse Optimal Control скачать в хорошем качестве
ICRA'2021 Talk - General-Sum Multi-Agent Continuous Inverse Optimal Control
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: ICRA'2021 Talk - General-Sum Multi-Agent Continuous Inverse Optimal Control в качестве 4k
У нас вы можете посмотреть бесплатно ICRA'2021 Talk - General-Sum Multi-Agent Continuous Inverse Optimal Control или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон ICRA'2021 Talk - General-Sum Multi-Agent Continuous Inverse Optimal Control в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
ICRA'2021 Talk - General-Sum Multi-Agent Continuous Inverse Optimal Control
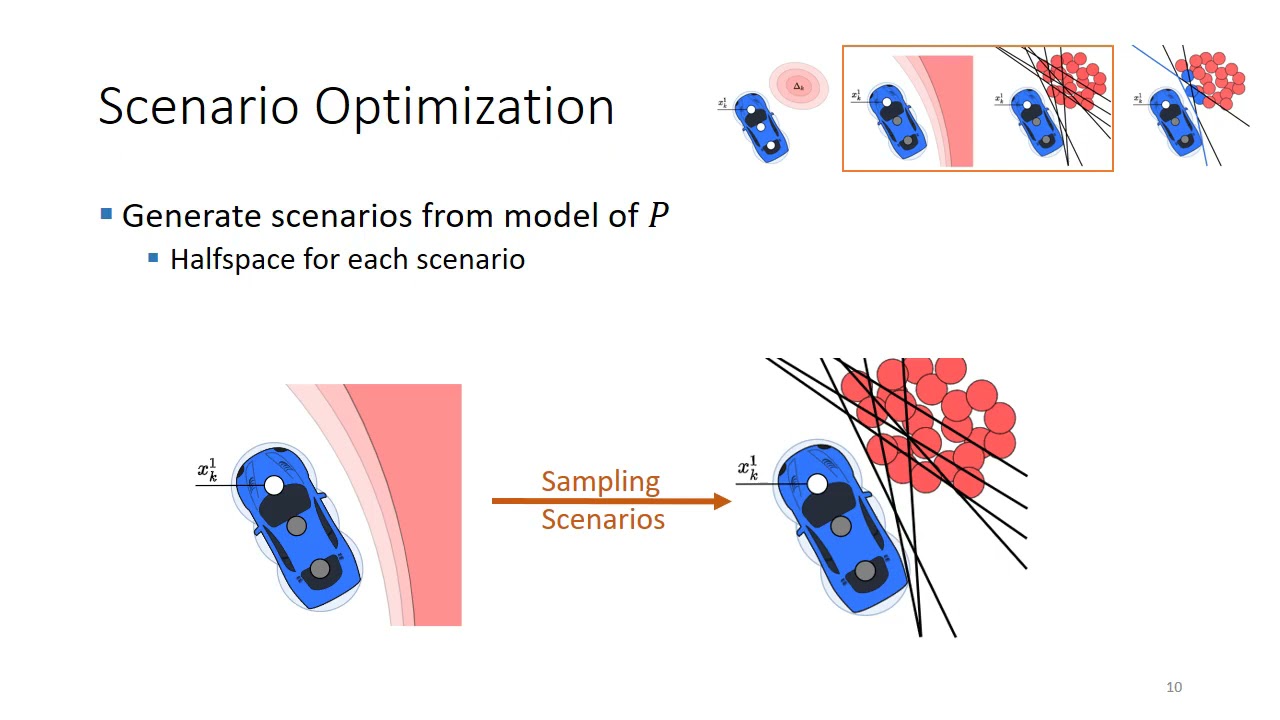
Talk by Christian Neumayer based on the paper: C. Neumeyer, F.A. Oliehoek and D.M. Gavrila General-Sum Multi-Agent Continuous Inverse Optimal Control. IEEE Robotics and Automation Letters (RAL), vol.6, nr.2, pp.3429-3436, 2021 Abstract Modelling possible future outcomes of robot-human interactions is of importance in the intelligent vehicle and mobile robotics domains. Knowing the reward function that explains the observed behaviour of a human agent is advantageous for modelling the behaviour with Markov Decision Processes (MDPs). However, learning the rewards that determine the observed actions from data is complicated by interactions. We present a novel inverse reinforcement learning (IRL) algorithm that can infer the reward function in multi-agent interactive scenarios. In particular, the agents may act boundedly rational (i.e., suboptimal), a characteristic that is typical for human decision making. Additionally, every agent optimizes its own reward function which makes it possible to address non-cooperative setups. In contrast to other methods, the algorithm does not rely on reinforcement learning during inference of the parameters of the reward function. We demonstrate that our proposed method accurately infers the ground truth reward function in two-agent interactive experiments1. For the PDF of the full paper, see http://intelligent-vehicles.org/publi...
Comments