Attention is all you need. A Transformer Tutorial: 5. Positional Encoding скачать в хорошем качестве
Attention is all you need. A Transformer Tutorial: 5. Positional Encoding
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Attention is all you need. A Transformer Tutorial: 5. Positional Encoding в качестве 4k
У нас вы можете посмотреть бесплатно Attention is all you need. A Transformer Tutorial: 5. Positional Encoding или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Attention is all you need. A Transformer Tutorial: 5. Positional Encoding в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Attention is all you need. A Transformer Tutorial: 5. Positional Encoding
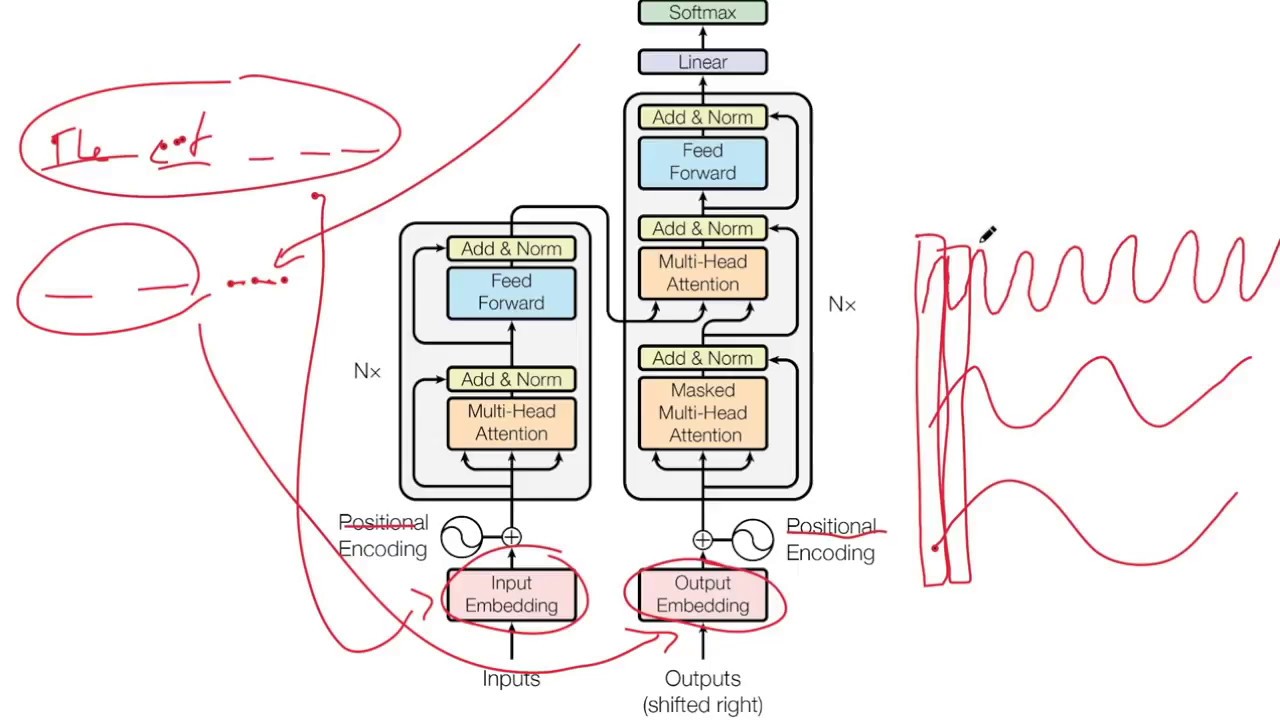
Repo link: https://github.com/feather-ai/transfo... Transformers don't have any inherent form of encoding sequences. Positional Encoding is a strategy we can use to encode the positions of the words in the sequence. This video guides us through the code and theory of how positional encoding works
Comments






![Как внедрение вращательного положения даёт толчок развитию современных LLM [RoPE]](https://imager.clipsaver.ru/SMBkImDWOyQ/max.jpg)











