Attention Is All You Need - Paper Explained скачать в хорошем качестве
Attention Is All You Need - Paper Explained
4 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Attention Is All You Need - Paper Explained в качестве 4k
У нас вы можете посмотреть бесплатно Attention Is All You Need - Paper Explained или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Attention Is All You Need - Paper Explained в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Attention Is All You Need - Paper Explained
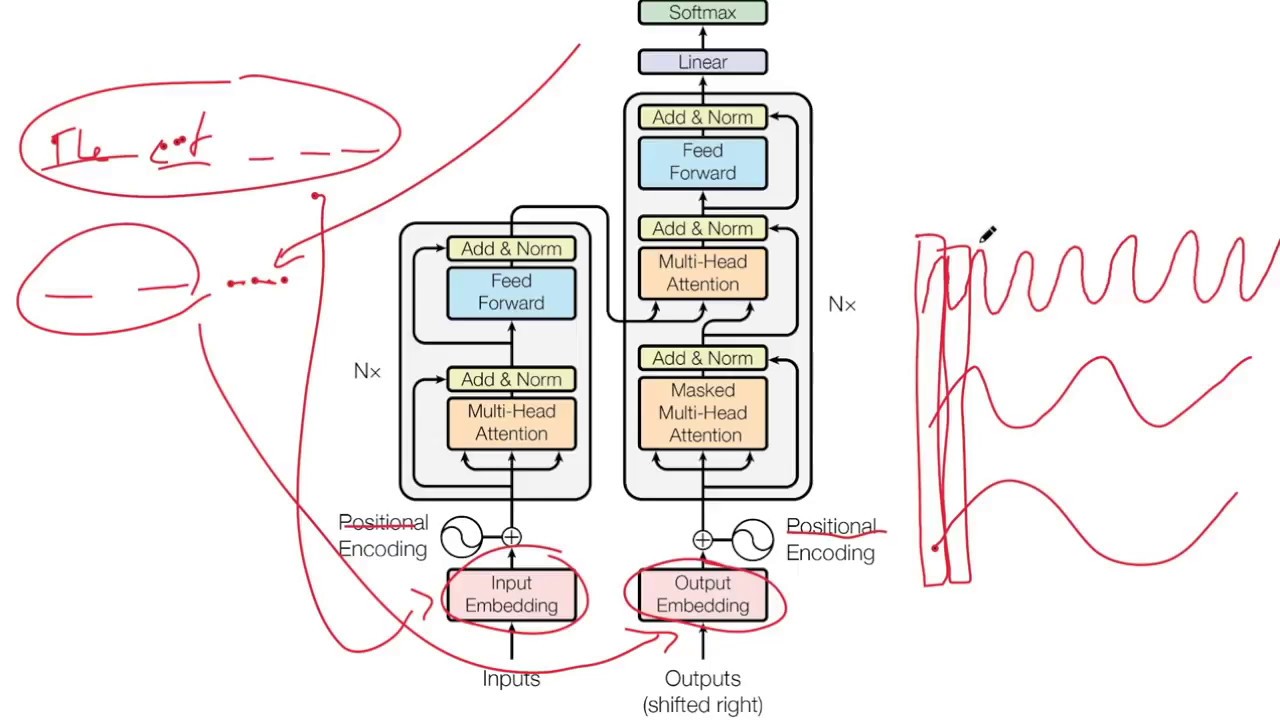
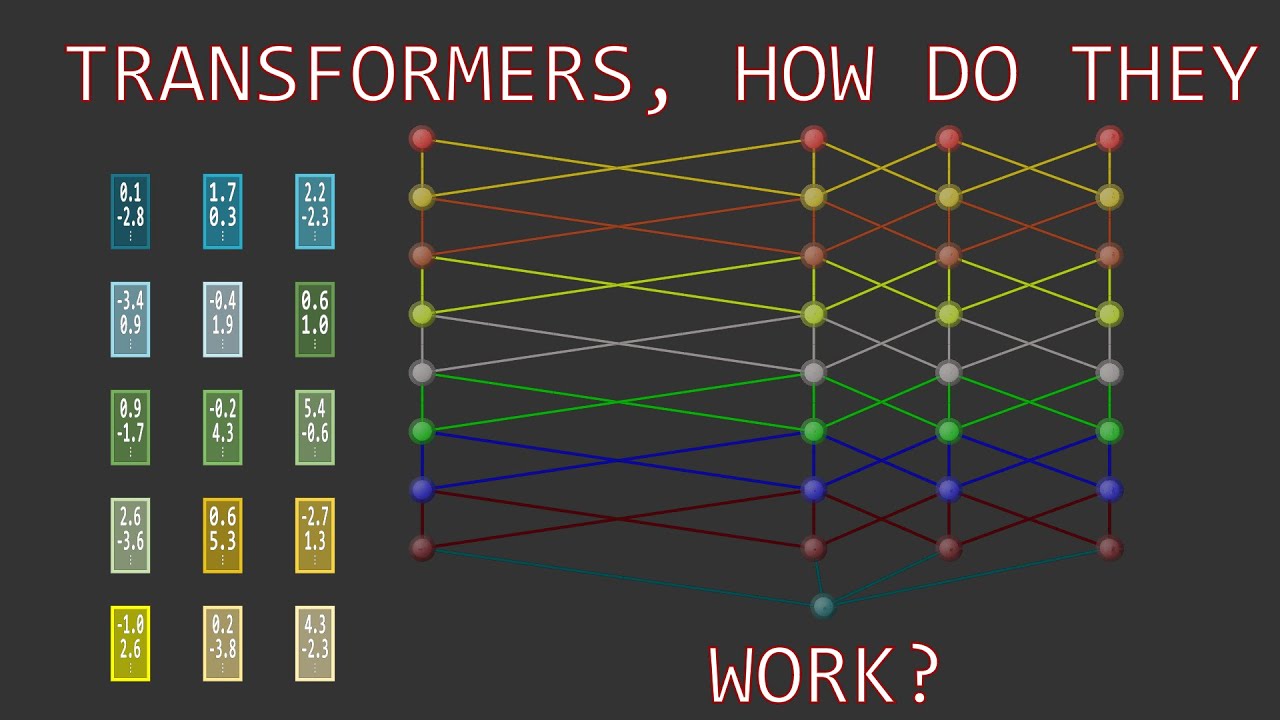
In this video, I'll try to present a comprehensive study on Ashish Vaswani and his coauthors' renowned paper, “attention is all you need” This paper is a major turning point in deep learning research. The transformer architecture, which was introduced in this paper, is now used in a variety of state-of-the-art models in natural language processing and beyond. 📑 Chapters: 0:00 Abstract 0:39 Introduction 2:44 Model Details 3:20 Encoder 3:30 Input Embedding 5:22 Positional Encoding 11:05 Self-Attention 15:38 Multi-Head Attention 17:31 Add and Layer Normalization 20:38 Feed Forward NN 23:40 Decoder 23:44 Decoder in Training and Testing Phase 27:31 Masked Multi-Head Attention 30:03 Encoder-decoder Self-Attention 33:19 Results 35:37 Conclusion 📝 Link to the paper: https://arxiv.org/abs/1706.03762 👥 Authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin 🔗 Helpful Links: "Vectoring Words (Word Embeddings)" by Computerphile: • Vectoring Words (Word Embeddings) - Comput... "Transformer Architecture: The Positional Encoding" by Amirhossein Kazemnejad: https://kazemnejad.com/blog/transform... "The Illustrated Transformer" by Jay Alammar: https://jalammar.github.io/illustrate... Lennart Svensson's Video on Masked self-attention: • Transformers - Part 7 - Decoder (2): maske... Lennart Svensson's Video on Encoder-decoder self-attention: • Transformer - Part 8 - Decoder (3): Encode... 🙏 I'd like to express my gratitude to Dr. Nasersharif, my supervisor, for suggesting this paper to me. 🙋♂️ Find me on: halflingwizard.me 🎁 Support the Channel: If you’d like to support my work, you can check out my wishlist here: https://www.amazon.com/registries/gl/... Your support helps me keep creating content like this. Thank you for being part of this journey! #Transformer #Attention #Deep_Learning
Comments










![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg)





![[1hr Talk] Intro to Large Language Models](https://imager.clipsaver.ru/zjkBMFhNj_g/max.jpg)
