Encoder Decoder Architecture Explained for Machine Translation Seq2Seq NLP скачать в хорошем качестве
Encoder Decoder Architecture Explained for Machine Translation Seq2Seq NLP
9 дней назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Encoder Decoder Architecture Explained for Machine Translation Seq2Seq NLP в качестве 4k
У нас вы можете посмотреть бесплатно Encoder Decoder Architecture Explained for Machine Translation Seq2Seq NLP или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Encoder Decoder Architecture Explained for Machine Translation Seq2Seq NLP в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Encoder Decoder Architecture Explained for Machine Translation Seq2Seq NLP
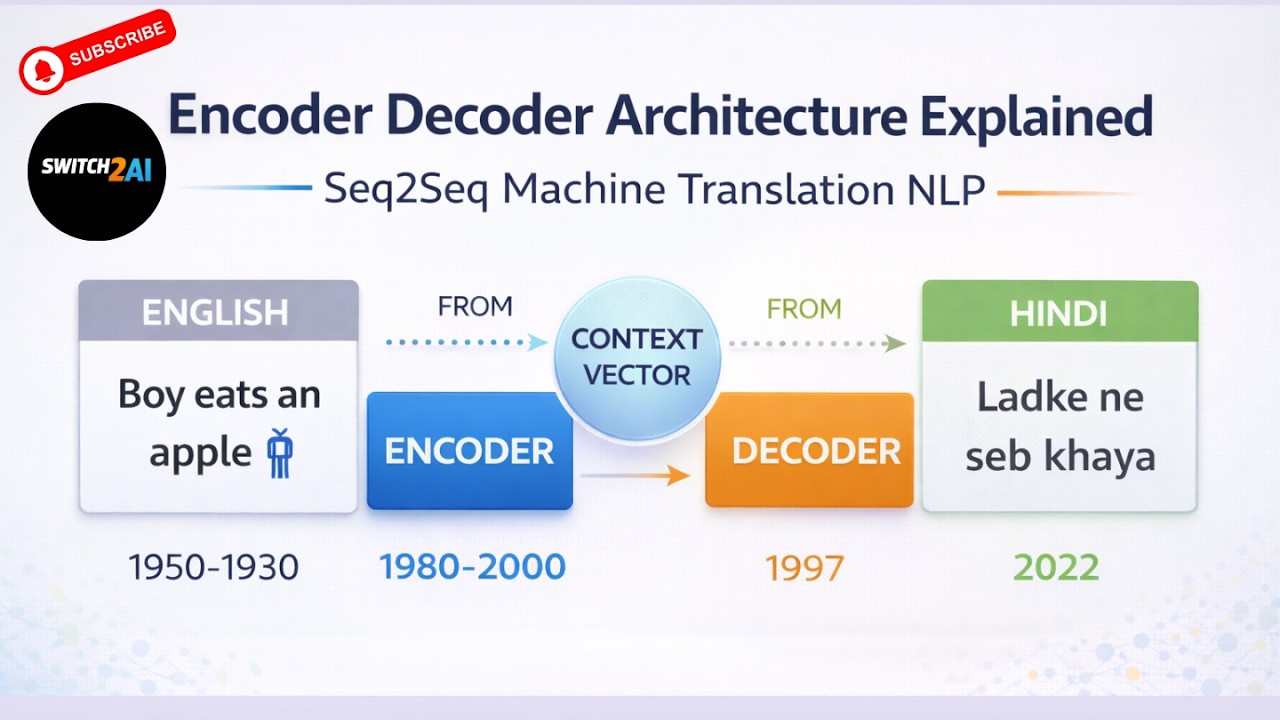
In this video, we introduce the Encoder–Decoder architecture used in Natural Language Processing for sequence-to-sequence tasks such as machine translation. This architecture became one of the most important breakthroughs in deep learning for language tasks and laid the foundation for many modern NLP systems. Here is the GitHub repo link: https://github.com/switch2ai You can download all the code, scripts, and documents from the above GitHub repository. We start by understanding the machine translation problem. In machine translation, a sentence in the source language is converted into another language called the target language. For example, a sentence in English such as “Boy eats an apple” can be translated into Hindi as “Ladke ne seb khaya”. To solve this problem, sequence-to-sequence models are used. These models consist of two main components: an encoder and a decoder. The encoder processes the input sentence word by word and converts it into a fixed-length numerical representation known as the context vector. Initially the hidden state starts with a zero vector. As each word is processed, the hidden state is updated and begins capturing the meaning of the sentence. For example, the hidden state gradually builds context as “Boy”, “Boy eats”, “Boy eats an”, and finally “Boy eats an apple”. The final hidden state contains the complete representation of the input sentence and becomes the context vector. This context vector is then passed to the decoder. The decoder is responsible for generating the translated sentence one word at a time. The decoding process usually begins with a special token called Start of Sentence (SoS). Based on the context vector and previously generated words, the decoder predicts the next word in the target sequence until it reaches the End of Sentence (EoS) token. We also discuss an important training technique called teacher forcing. During training, the decoder normally uses the previously generated output as the next input. However, if the model generates an incorrect word early in the sequence, the error can propagate through the rest of the sequence. Teacher forcing solves this issue by feeding the correct word from the training dataset instead of the model’s predicted word. This technique helps the model learn faster and stabilizes training. The encoder–decoder architecture offers several advantages. It is well suited for sequence-to-sequence problems such as machine translation, text summarization, and dialogue systems. It also allows end-to-end learning where the model directly learns to map input sequences to output sequences. However, the architecture also has some limitations. Since the entire input sentence is compressed into a single context vector, important information may be lost when processing long sentences. This can lead to a drop in accuracy for longer sequences. We also briefly discuss how traditional embedding methods used static embeddings where each word had a fixed vector representation. For example, the word “Apple” would always have the same embedding regardless of whether it refers to the fruit or the company. This limitation later led to the development of contextual embeddings in modern language models. By the end of this video, you will clearly understand how the encoder–decoder architecture works, how machine translation models generate sentences, and why this architecture became a key milestone in the evolution of NLP systems. Channel Name: Switch 2 AI Hashtags #EncoderDecoder #Seq2Seq #MachineTranslation #NLP #DeepLearning #NeuralNetworks #LSTM #AI #NaturalLanguageProcessing #Switch2AI SEO Tags encoder decoder architecture seq2seq model explained machine translation neural networks encoder decoder LSTM tutorial sequence to sequence model NLP teacher forcing explained RNN encoder decoder model machine translation deep learning context vector neural networks seq2seq NLP tutorial LSTM encoder decoder example NLP machine translation model deep learning NLP architecture sequence modeling neural networks Switch 2 AI SEO Tags (500 characters comma separated) encoder decoder architecture,seq2seq model explained,machine translation neural networks,encoder decoder LSTM tutorial,sequence to sequence model NLP,teacher forcing explained,RNN encoder decoder model,machine translation deep learning,context vector neural networks,seq2seq NLP tutorial,LSTM encoder decoder example,NLP machine translation model,deep learning NLP architecture,sequence modeling neural networks,Switch 2 AI,seq2seq encoder decoder explained
Comments