How 1 Bit LLMs Work скачать в хорошем качестве
How 1 Bit LLMs Work
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How 1 Bit LLMs Work в качестве 4k
У нас вы можете посмотреть бесплатно How 1 Bit LLMs Work или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How 1 Bit LLMs Work в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How 1 Bit LLMs Work
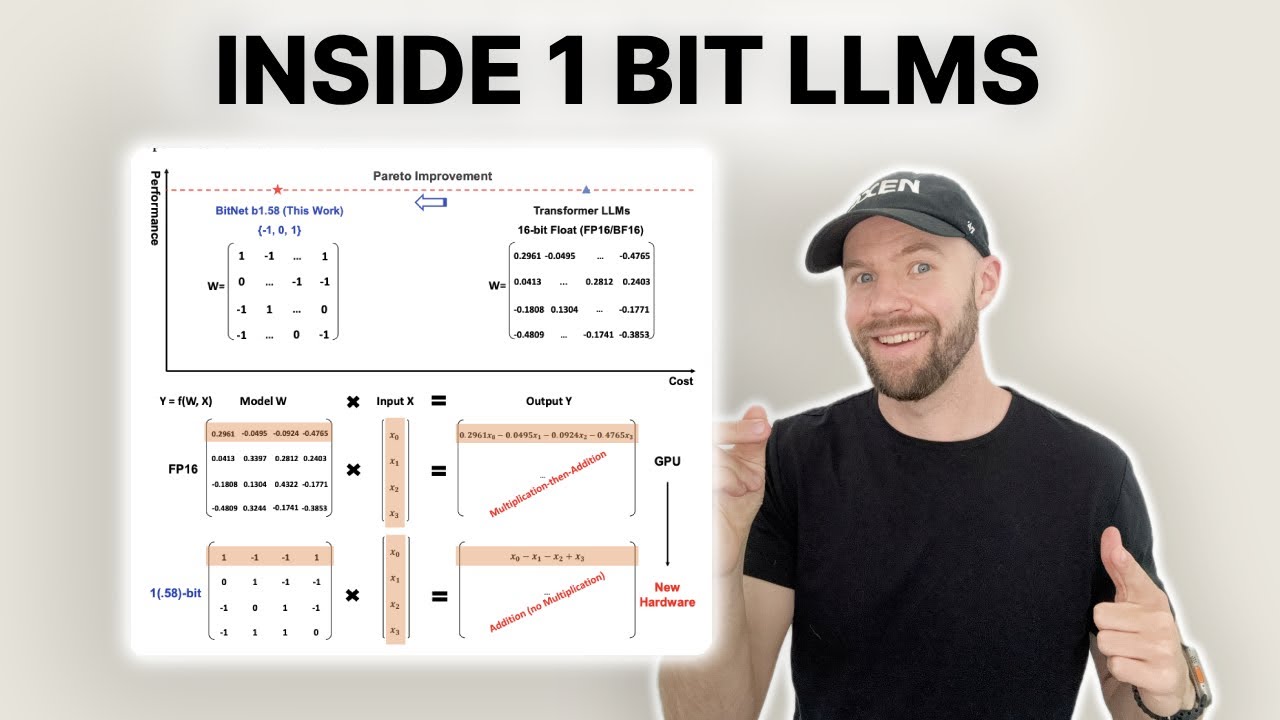
We dive into The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits paper, a technique to represent weights with 0, 1, or -1 integers instead of floats. -- Get Oxen AI 🐂 https://oxen.ai/ Oxen AI makes versioning your datasets as easy as versioning your code! Even is millions of unstructured images, the tool quickly handles any type of data so you can build cutting-edge AI. -- Paper 📜 https://arxiv.org/abs/2402.17764 Links + Notes 📝 https://www.oxen.ai/blog/arxiv-dives-... Join Arxiv Dives 🤿 https://oxen.ai/community Discord 🗿 / discord -- Chapters 0:00 Intro 2:28 Why Called BitNet 1.58 3:08 Why Should I Care? 4:18 Math 6:08 Quantization Without BitNet 8:50 BitLinear Layer 11:30 What About Backpropagation? 13:42 How Many Gainz? 15:03 Bessie the BitNet 16:15 Testing the Base Model 21:20 Fine_Tuning for QA/Instructions 33:03 The Code 33:25 Diving into the Quantization 43:30 Good News and Bad News 44:22 What’s Next? 44:58 Takeaways
Comments


















![[1hr Talk] Intro to Large Language Models](https://imager.clipsaver.ru/zjkBMFhNj_g/max.jpg)