Tokenization: The Cursed Trick that Unlocked LLMs скачать в хорошем качестве
Tokenization: The Cursed Trick that Unlocked LLMs
1 день назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: Tokenization: The Cursed Trick that Unlocked LLMs в качестве 4k
У нас вы можете посмотреть бесплатно Tokenization: The Cursed Trick that Unlocked LLMs или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон Tokenization: The Cursed Trick that Unlocked LLMs в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
Tokenization: The Cursed Trick that Unlocked LLMs
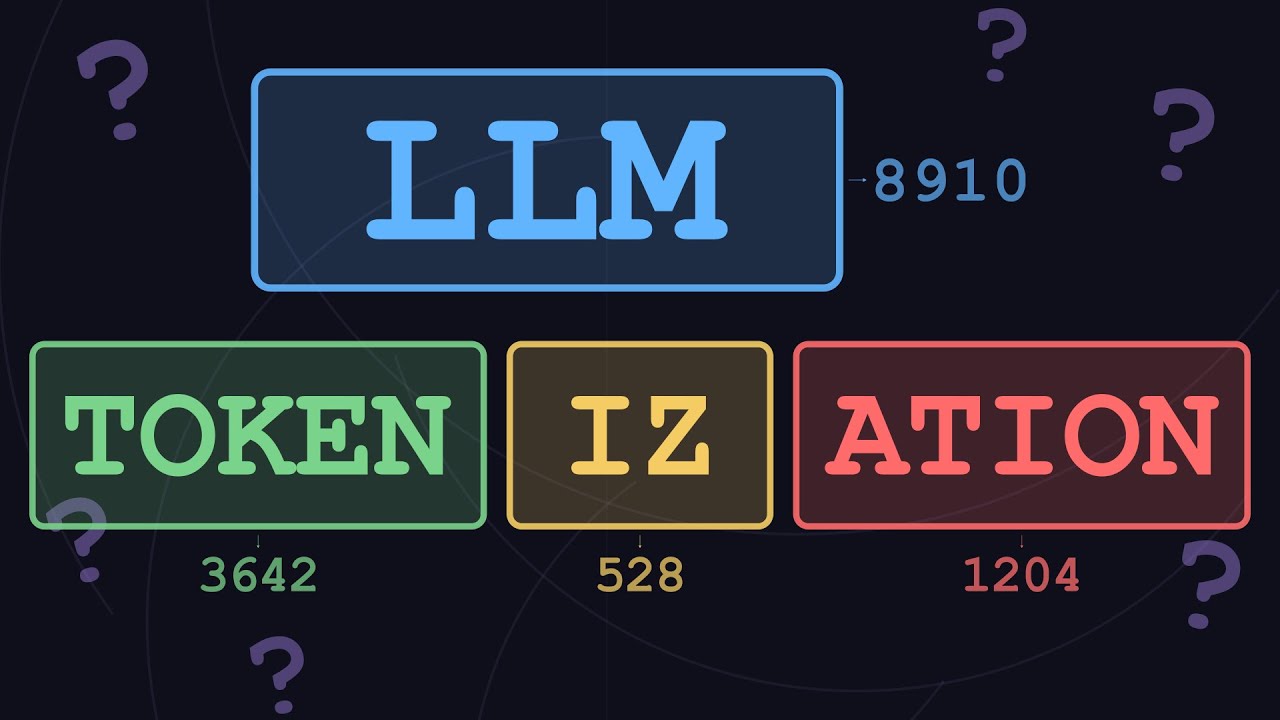
GPT doesn't read your text. It reads tokens — chunks of characters that don't always line up with words. "ChatGPT" is three separate objects to the model. This invisible translation layer explains every weird AI behavior: the strawberry R-counting failure, arithmetic struggles, and the SolidGoldMagikarp glitch. → What tokens actually are — not characters, not words, something in between → How BPE (Byte Pair Encoding) builds a 100K-token vocabulary from scratch → The two-process gap — why tokenizer training ≠ LLM training → SolidGoldMagikarp — the Reddit username that broke GPT → Why GPT struggles with spelling, math, and non-English text → The unified root cause behind every confusing AI behavior Chapters: 0:00 Intro 0:03 The Hook — ChatGPT Is Three Words 0:52 What Is a Token 1:58 How BPE Builds the Vocabulary 3:14 Glitch Tokens & SolidGoldMagikarp 4:42 Why This Explains Everything 6:07 Outro References: → Andrej Karpathy: Let's Build the GPT Tokenizer — • Let's build the GPT Tokenizer → SolidGoldMagikarp — Alignment Forum — https://www.alignmentforum.org/posts/... → OpenAI Tokenizer — https://platform.openai.com/tokenizer #Tokenization #GPT #LLM
Comments