RAG Is Simpler Than You Think (90% Do It Wrong) скачать в хорошем качестве
RAG Is Simpler Than You Think (90% Do It Wrong)
5 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: RAG Is Simpler Than You Think (90% Do It Wrong) в качестве 4k
У нас вы можете посмотреть бесплатно RAG Is Simpler Than You Think (90% Do It Wrong) или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон RAG Is Simpler Than You Think (90% Do It Wrong) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
RAG Is Simpler Than You Think (90% Do It Wrong)
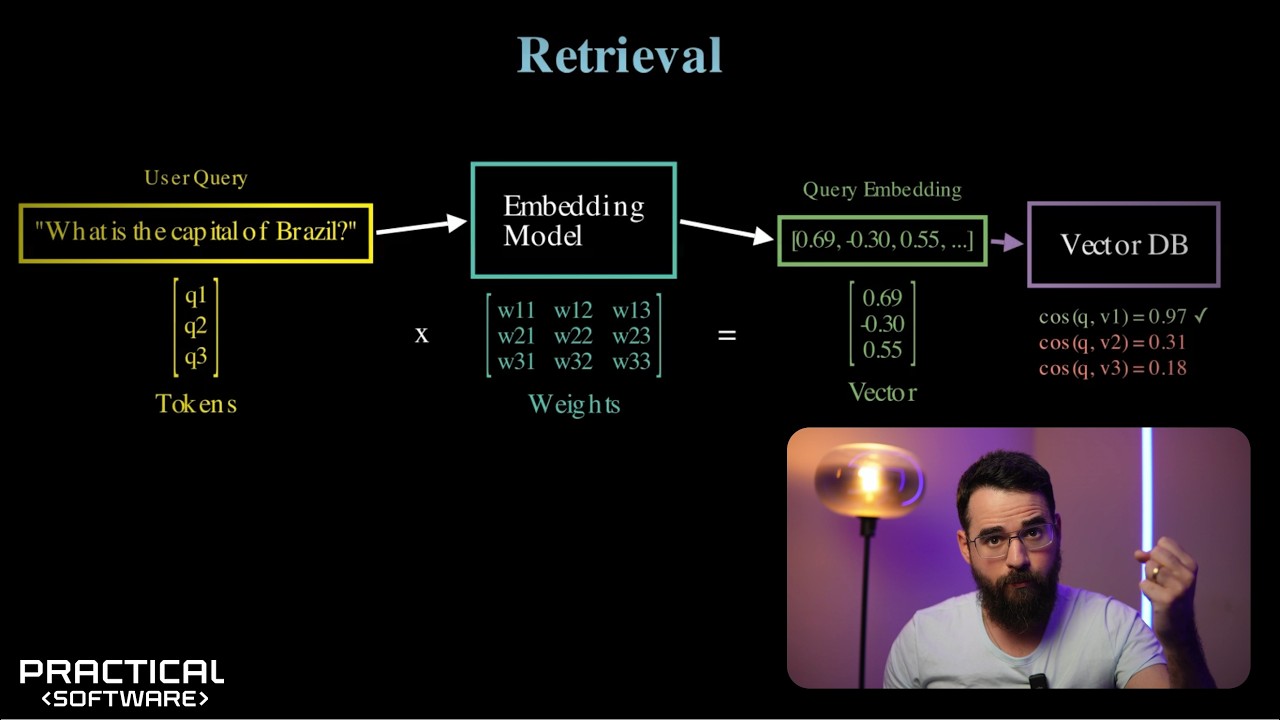
Join My Community to Level Up ➡ https://www.skool.com/earlyaidopters/... Grab The RAG Cheat Sheet Guide: https://markkashef.gumroad.com/l/ragr... 📅 Book a Meeting with Our Team: https://bit.ly/3Ml5AKW 🌐 Visit Our Website: https://bit.ly/4cD9jhG 🎬 Core Video Description RAG (Retrieval Augmented Generation) isn’t one thing—it’s a spectrum. In this practical 35-minute guide, I map that spectrum from “lazy but lethal” context-dumping to bleeding-edge agentic graph RAG, showing exactly when each level makes sense so you don’t overengineer simple problems—or underbuild the hard ones. You’ll learn a clear decision playbook to match your data size, accuracy needs, cost constraints, and maintenance reality. We’ll cover fast wins like prompt caching and smart chunk selection; proven foundations like classic vector-search RAG; precision boosters like hybrid (semantic + keyword) and contextual RAG; and advanced patterns like agentic RAG, multi-index RAG, Graph RAG, and Agentic Graph RAG. Along the way I reference tools and stacks including n8n, Pinecone/Qdrant, Supabase, Elasticsearch, GPT-4.1/4.1-mini, Gemini 2.5 (Pro/Flash), and Claude—plus a downloadable cheat sheet of the full ladder (grab it via the second link above). By the end, you’ll know exactly which RAG level to ship now, and when to level up later. ⏳ TIMESTAMPS: 00:00 – Why RAG matters & the overengineering trap 00:46 – The RAG spectrum: pick what fits today 01:42 – What we’ll cover (10 RAG styles) 02:04 – How to use this guide (decide first, build second) 02:16 – Level 0: Context Dump (“paste everything”) 03:01 – 1M-token models + the cheat-sheet trick 04:00 – n8n demo: quick context-dump setup 06:20 – Pros/cons & ideal use cases 08:58 – Level 1: Prompt Caching (big savings on repeats) 10:54 – Providers, cache windows, and caveats 11:38 – Level 2: Smart Chunks (AI librarian) 13:01 – Cross-section risks & org hygiene 14:05 – Level 3: Traditional RAG (embeddings + vectors) 16:55 – Speed/scale sweet spots & tradeoffs 17:01 – Level 4: Hybrid RAG (semantic + keyword) 19:20 – Dual maintenance, failure points, best fits 20:04 – Level 5: Contextual RAG (surrounding sections) 22:31 – Precision vs token costs 22:49 – Level 6: Agentic RAG (research-assistant loop) 25:11 – Cost/complexity realities 25:16 – Level 7: Multi-Index RAG (specialist indexes) 27:24 – Upkeep overhead & enterprise fit 28:01 – Level 8: Graph RAG (relationship maps) 30:53 – Multi-hop reasoning: power & pitfalls 30:59 – Level 9: Agentic Graph RAG (self-healing network) 33:23 – Why it’s overkill for most teams 34:17 – Playbook recap: start lazy, then level up 34:46 – Grab the cheat sheet (link #2) 34:57 – Community invite & outro #RAG #RetrievalAugmentedGeneration #HybridRAG #GraphRAG #AgenticAI #AIAgents #VectorDatabases #Pinecone #Qdrant #Elasticsearch #n8n #OpenAI #gpt5 #gemini #ClaudeAI
Comments