PD Disaggregation: Maximizing DeepSeek Throughput скачать в хорошем качестве
PD Disaggregation: Maximizing DeepSeek Throughput
8 месяцев назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...

Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: PD Disaggregation: Maximizing DeepSeek Throughput в качестве 4k
У нас вы можете посмотреть бесплатно PD Disaggregation: Maximizing DeepSeek Throughput или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон PD Disaggregation: Maximizing DeepSeek Throughput в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
PD Disaggregation: Maximizing DeepSeek Throughput
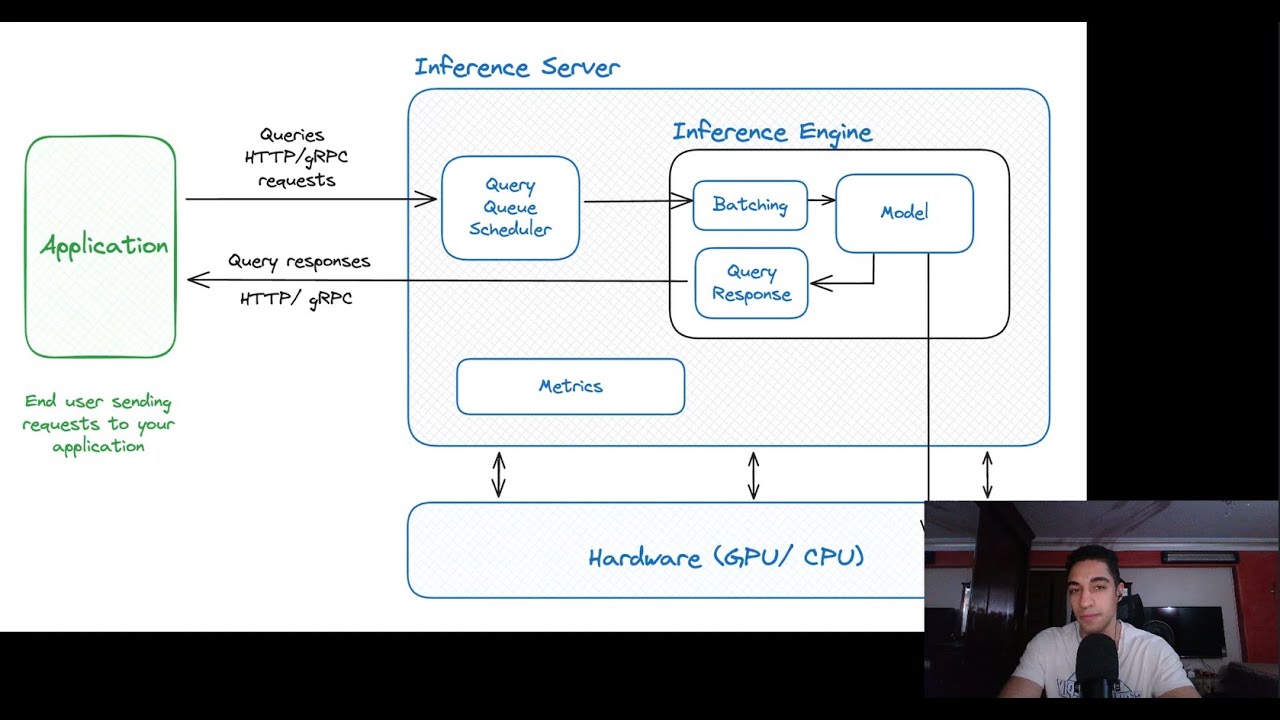
How we unlocked +52 % more LLM output per GPU, explained in 10 minutes. Atlas Cloud walks through the exact playbook that pushed our NVIDIA H100 clusters to 51.7 K tokens/sec (prefill) and 22.5 K tokens/sec (decode) on DeepSeek models, beating the reference benchmarks without adding hardware. Key Takeaways Higher throughput, lower cost: Up to 52 % more tokens per GPU lets you scale user traffic or trim infrastructure budget. Faster time-to-value: PD disaggregation cuts latency, improving user experience without code changes. Future-proof stack: Runs on neocloud GPU infrastructure—an agile, hyperscaler alternative designed for safe, simple, scalable AI. 👍 Like this video? Subscribe for more thought-leadership breakdowns on GPU infrastructure, inference best practices, and scaling strategies.
Comments
-
 Трансляция закончилась 1 год назад
Трансляция закончилась 1 год назад
-
 11 дней назад
11 дней назад
-
 Трансляция закончилась 21 час назад
Трансляция закончилась 21 час назад
-
 3 года назад
3 года назад
-
 9 дней назад
9 дней назад
-
 2 дня назад
2 дня назад
-
 12 часов назад
12 часов назад
-
 10 дней назад
10 дней назад
-
![Почему взрываются батарейки и аккумуляторы? [Veritasium]](https://imager.clipsaver.ru/a3-3R9zwyGY/max.jpg) 3 месяца назад
3 месяца назад
-
 4 недели назад
4 недели назад
-
 1 год назад
1 год назад
-
 7 месяцев назад
7 месяцев назад
-
 3 недели назад
3 недели назад
-
 2 недели назад
2 недели назад
-
 1 год назад
1 год назад
-
 10 месяцев назад
10 месяцев назад
-
 8 дней назад
8 дней назад
-
 2 недели назад
2 недели назад
-
 2 года назад
2 года назад
-
 9 дней назад
9 дней назад