How to Efficiently Serve an LLM? скачать в хорошем качестве
How to Efficiently Serve an LLM?
1 год назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: How to Efficiently Serve an LLM? в качестве 4k
У нас вы можете посмотреть бесплатно How to Efficiently Serve an LLM? или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон How to Efficiently Serve an LLM? в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
How to Efficiently Serve an LLM?
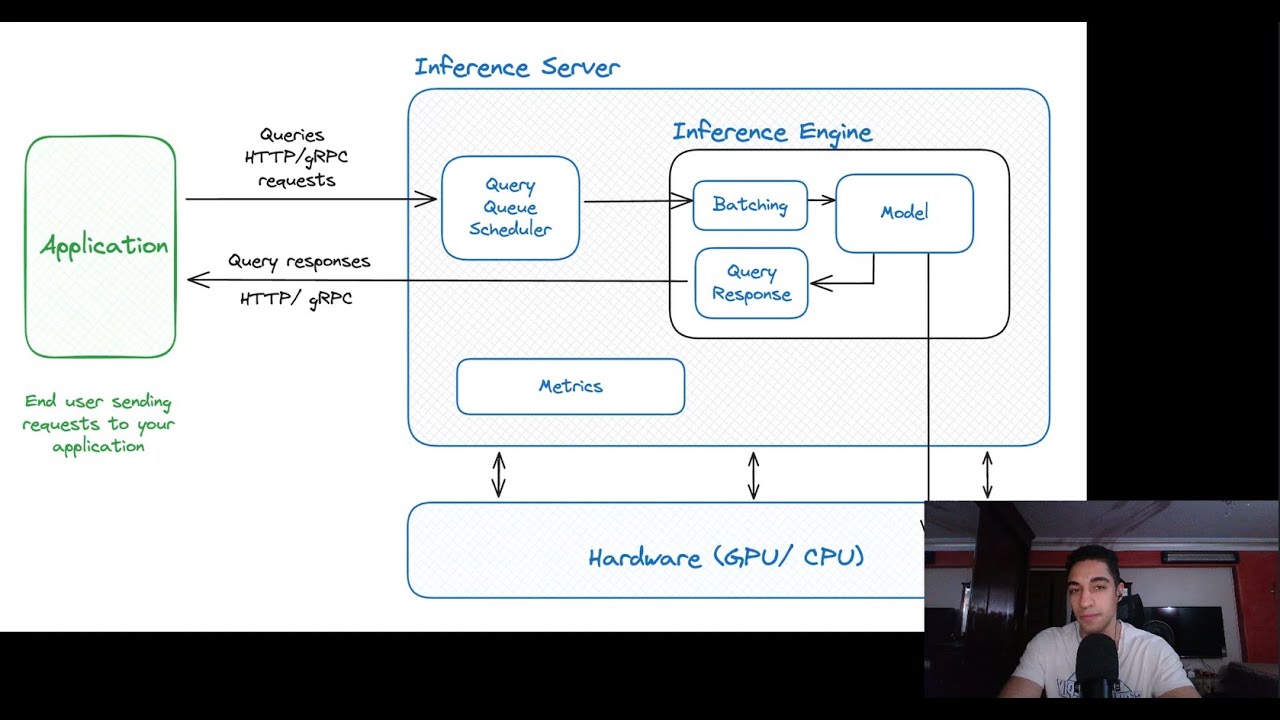
How to Efficiently Serve an LLM Large Language Models (LLMs) have become crucial due to their performance, but their size poses significant serving challenges. This video covers strategies to optimize LLM serving systems for better efficiency. Key Steps in LLM Inference: 1. Request Handling: Users send requests via HTTPs/gRPC, which the LLM server schedules based on Quality of Experience (QoE) metrics: TTFT (Time to First Token) TDS (Token Delivery Speed) 2. Inference Phases: Prefill Phase: Processes input tokens in parallel to generate the KV Cache, utilizing GPU's parallel processing. Decode Phase: Generates output tokens sequentially, requiring optimization for efficiency. Optimization Techniques: 1. Batching: Combines multiple requests to maximize resource use. 2. Model Quantization: Reduces model weight precision to free up GPU memory. 3. Paged Attention: Manages memory efficiently by avoiding fragmentation. 4. Prefill Chunking: Merges prefill and decode phases for different requests. 5. Prefill/Decode Disaggregation: Separates phases to transfer KV Cache effectively. 6. KV Cache Compression: Speeds up network transfer for large context lengths. 7. Speculative Decoding: Uses smaller models for faster token generation. 8. Radix Attention: Reuses KV Cache without recomputation for specific use cases. 9. Early Rejection: Predicts infeasible requests early to save resources. For a detailed dive into each optimization, check my blog post: https://ahmedtremo.com/posts/How-to-E... 00:00 Introduction 00:49 Prefill/Decode 02:00 Pricing 03:05 Continuous Batching 03:41 Quantization 04:37 Prefill Chunking 05:56 Disaggregated Arch 06:30 Radix Attention 07:54 Early Rejection 08:33 KV Compression 09:32 PagedAttention/vAttention 11:00 QoE Scheduling 11:40 Speculative Decoding
Comments
-
 11 месяцев назад
11 месяцев назад
-
![Как внимание стало настолько эффективным [GQA/MLA/DSA]](https://imager.clipsaver.ru/Y-o545eYjXM/max.jpg) 2 месяца назад
2 месяца назад
-
 8 месяцев назад
8 месяцев назад
-
 1 год назад
1 год назад
-
 2 года назад
2 года назад
-
 2 года назад
2 года назад
-
 2 года назад
2 года назад
-
 Трансляция закончилась 9 месяцев назад
Трансляция закончилась 9 месяцев назад
-
 2 года назад
2 года назад
-
 1 год назад
1 год назад
-
 Трансляция закончилась 1 год назад
Трансляция закончилась 1 год назад
-
 1 год назад
1 год назад
-
 2 дня назад
2 дня назад
-
 8 месяцев назад
8 месяцев назад
-
 2 года назад
2 года назад
-
 1 год назад
1 год назад
-
 1 год назад
1 год назад
-
 Трансляция закончилась 1 год назад
Трансляция закончилась 1 год назад
-
 1 год назад
1 год назад
-
 1 год назад
1 год назад