MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition скачать в хорошем качестве
MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition
3 года назад
Не удается загрузить Youtube-плеер. Проверьте блокировку Youtube в вашей сети.
Повторяем попытку...
Повторяем попытку...
Скачать видео с ютуб по ссылке или смотреть без блокировок на сайте: MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition в качестве 4k
У нас вы можете посмотреть бесплатно MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition или скачать в максимальном доступном качестве, видео которое было загружено на ютуб. Для загрузки выберите вариант из формы ниже:
-
Информация по загрузке:
Скачать mp3 с ютуба отдельным файлом. Бесплатный рингтон MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием видео, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса ClipSaver.ru
MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition
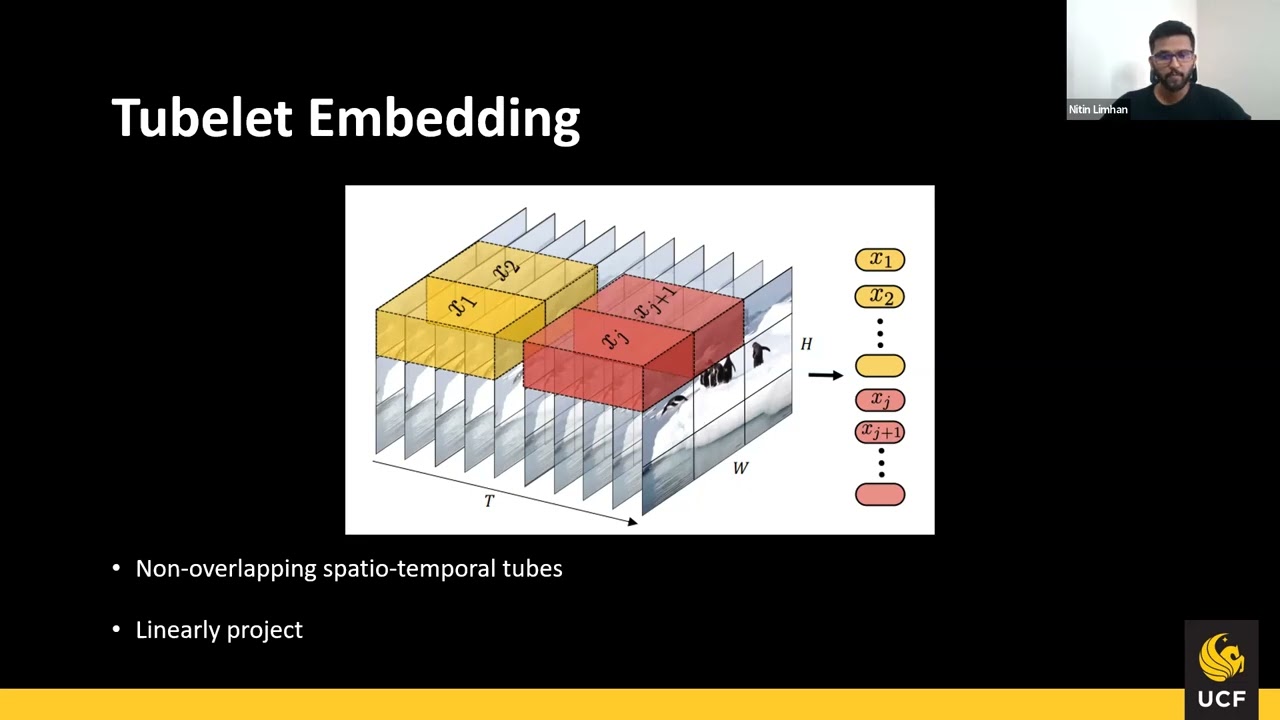
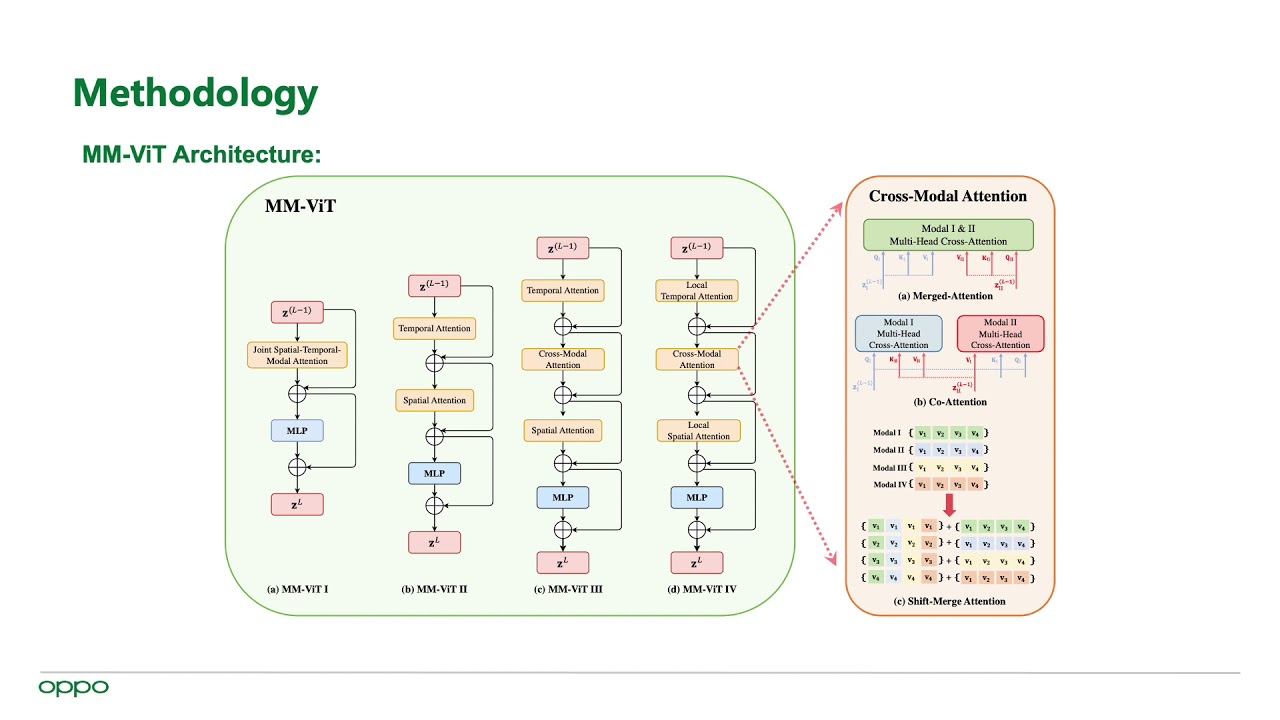
Authors: Jiawei Chen (InnoPeak Technology)*; Chiuman Ho (OPPO US R&D) Description: This paper presents a pure transformer-based approach, dubbed the Multi-Modal Video Transformer (MM-ViT), for video action recognition. Different from other schemes which solely utilize the decoded RGB frames, MM-ViT operates exclusively in the compressed video domain and exploits all readily available modalities, i.e., I-frames, motion vectors, residuals and audio waveform. In order to handle the large number of spatiotemporal tokens extracted from multiple modalities, we develop several scalable model variants which factorize self-attention across the space, time and modality dimensions. In addition, to further explore the rich inter-modal interactions and their effects, we develop and compare three distinct cross-modal attention mechanisms that can be seamlessly integrated into the transformer building block. Extensive experiments on three public action recognition benchmarks (UCF-101,Something-Something-v2, Kinetics-600) demonstrate that MM-ViT outperforms the state-of-the-art video transformers in both efficiency and accuracy, and performs better or equally well to the state-of-the-art CNN counterparts with computationally-heavy optical flow
Comments